

决策树
以二分类学习为例,机器学习中的决策树过程可以理解成模型通过样本的不同属性值进行深度分类。
让我们举个例子来说,假设我们需要评价一位英雄联盟玩家的水平,我们可以获得该玩家的某些样本属性和样本属性值,比如说KDA,MVP/SVP次数和参团率等等,KDA越高越好,但是也不能单看KDA,也需要其他的样本属性值,那么基于决策树的机器学习模型就是基于样本的各种属性值,不停得去求在某特定属性值情况下的最优另一属性,并且做不断重复迭代,从而找到最优解。
上面这样讲可能比较抽象,让我们来举个例子来进行说明,任务跟之前一样,那就是评价一位英雄联盟玩家的水平,为了方便讲解,将模型的输出限定在高手和非高手之中,数据集D中的样本属性和样本属性值如下图所示。(图中数据为作者编造,仅讲解分析用)
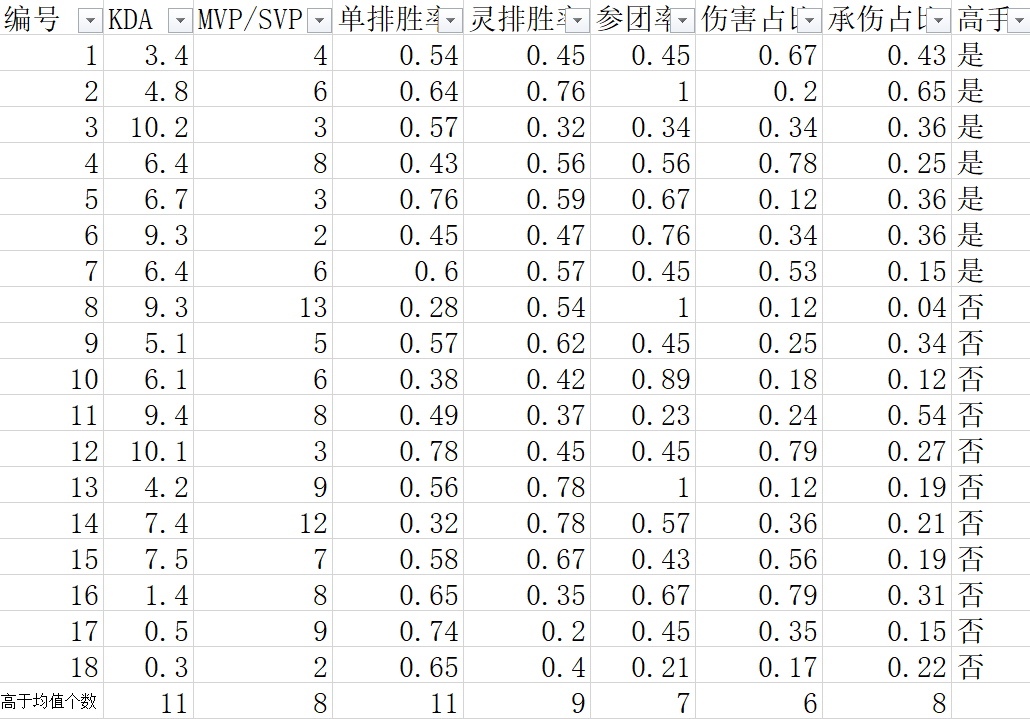
那么如何评价某些样本属性在样本分类中的重要性呢?这里就需要数学公式了,我们引入“信息熵”的概念,信息熵可以理解成在限定某一特定属性时,样本的纯度,公式如下:

那么有了信息熵的概念之后,就可以引入“信息增益”来评判某一特定样本属性对于决策树性能的增益,公式如下:
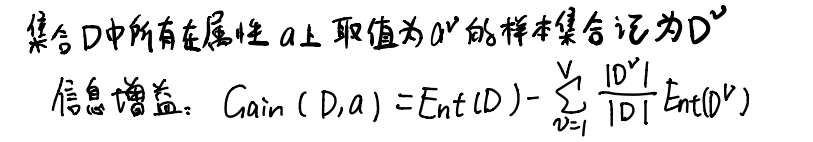
这个信息增益的作用就是在决策树往下延伸的时候,帮助我们判断应该选择哪个样本属性继续,在上述任务中,我们应该选择哪个样本属性来作为我们的第一个节点呢?这个时候就需要来计算特定样本属性的信息增益,从根结点来看,根结点包括所有样本,在所有样本中,高手的样本数量是7,非高中的样本数量是11,根据公式计算信息熵所得:
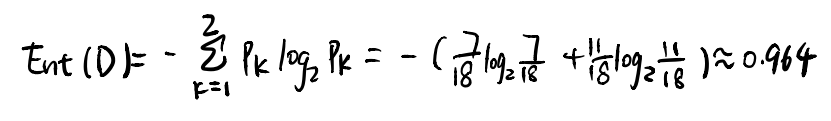
在这个基础上,计算KDA,MVP/SVP次数,单排胜率,灵排胜率,参团率,伤害占比,承伤占比的信息熵和信息增益,接下来就以KDA为例进行计算讲解。
为了方便描述,我计算出了KDA均值,并且通过均值将KDA的数据分成了上下2部分,高于均值就是优秀,低于均值就是普通,因此,在整个KDA列中,高于均值有11个,其中正例有5个,反例有6个,低于均值有7个,其中正例有2个,反例有5个,因此我们可以计算出KDA的信息熵:
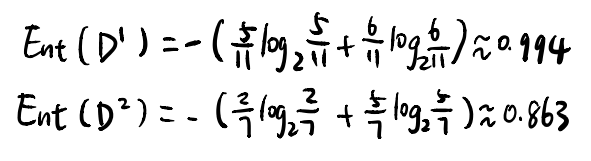
接下来计算信息增益,结果如下图所示:
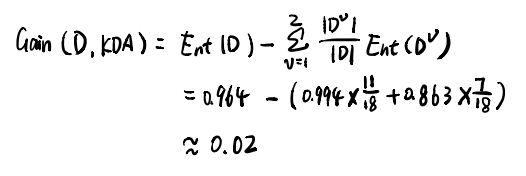
同理计算其他样本属性的信息增益,并且找到其中最大的(并列也可),我们选其为下一个节点,然后进行重复的迭代就会得到最终的决策树。



评论(0)
您还未登录,请登录后发表或查看评论