

1.从Loss函数开始
卷积神经网络中的Loss函数的数学原理以及python实现请看我之前的文章:【交叉熵】:神经网络的Loss函数编写:Softmax+Cross_Entropy,交叉熵与二次代价函数的区别与联系请访问:交叉熵代价函数(作用及公式推导),该作者将为什么使用交叉熵而不用二次代价函数讲的很清楚。
1.1 softmax函数及其求导1
softmax的函数公式如下:
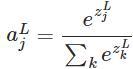
其中,
![]() 表示第L层(通常是最后一层)第j个神经元的输入,
表示第L层(通常是最后一层)第j个神经元的输入,
![]() 表示第L层第j个神经元的输出,e表示自然常数。注意看,
表示第L层第j个神经元的输出,e表示自然常数。注意看,
![]() 表示了第L层所有神经元的输入之和。
表示了第L层所有神经元的输入之和。
softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
另外,softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
由于softmax在ANN算法中的求导结果比较特别,分为两种情况。希望能帮助到正在学习此类算法的朋友们。求导过程如下所示:


1.2 Loss函数及其求导(Cross Entropy loss function+softmax activate function)
深度学习中的最小化代价函数。也叫作:最大化似然估计(maximum likelihood estimation);最小化负对数似然(NLL);最小化交叉熵(Cross Entropy)。具体可以参考Deep Learning 5.5 Maximum Likelihood Estimation。这里我们称之为log似然代价函数。
这里的代价函数(cost function)和损失函数(loss function)有稍微差别。这里我们称之为代价函数。 下图是我参考2的理解。

接上小节采用softmax作为激活函数,这里采用log似然代价函数(log-likelihood cost function)作为代价函数。
log似然代价函数的公式为:

其中,ak表示第k个神经元的输出值,也就是上小节softmax函数的输出,还是我们最终预测的结果。yk表示第k个神经元对应的真实值,取值为0或1,也就是标签的one-hot编码。
有了代价函数之后,我们知道深度学习反向传播的原理是最小化代价函数,也就是最小化C,这里边的原理先不深究,简而言之就是求C对各层参数的梯度,然后更新各层参数。所以找到最初的C对softmax层的输入
![]() 的导数,然后利用求导链式法则一层一层往前求梯度至关重要。
的导数,然后利用求导链式法则一层一层往前求梯度至关重要。
这里工作分为三步:
1.代价函数C对代价函数输入ak求导;(注意:ak同时是softmax层的输出)
2.softmax的输出ak对该层的输入
![]() 求导;(注意:在上一小节已经求过导数了)
求导;(注意:在上一小节已经求过导数了)
3.利用求导链式法则,求出代价函数C对softmax的输入
![]() 的导数。
的导数。
下面是公式:
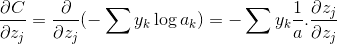
这里是第一步,然后将上小节公式代入,利用求导链式法则:
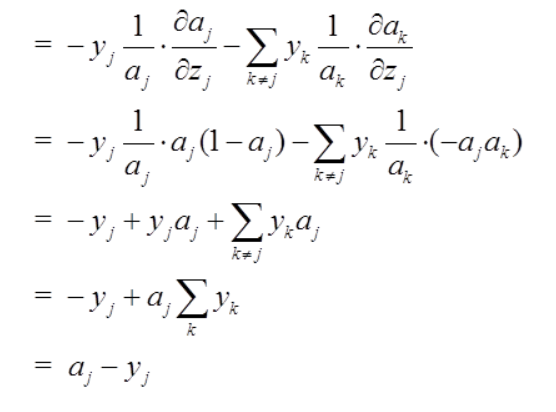
从结果可以看出,代价函数反向传播求梯度时,求C对softmax输入的梯度仅仅是softmax函数的输出ak与对应的标签yk之间的差。
【是的,你没看错,就是这么简单,原理上看很复杂,具体求解的话就是两个向量的差,估计这也是大家选择softmax做激活函数的原因之一吧】
2.代码
损失函数到softmax的输入的梯度求导代码很短,也就一句:
dscores[range(N), list(residual)] -= 1 这里,我将其直接放在softmax函数里:
class SoftmaxLayer:
def __init__(self, name='Softmax'):
pass
def forward(self, in_data):
shift_scores = in_data - np.max(in_data, axis=1).reshape(-1, 1) #在每行中10个数都减去该行中最大的数字
self.top_val = np.exp(shift_scores) / np.sum(np.exp(shift_scores), axis=1).reshape(-1, 1)
return self.top_val
def backward(self, residual):
N = residual.shape[0]
dscores = self.top_val.copy()
dscores[range(N), list(residual)] -= 1 #loss对softmax层的求导
dscores /= N
return dscores需要注意的是,后边还跟了一句:
dscores /= N我还没找到解释,可能是label值是概率值,减去1之后变成负数了,需要从新归一化一下,各位有不同的理解,欢迎留言交流。
更新:如果是损失函数的话,也就是多样本问题,就需要在前边加一个1/N。
{到此为止,我参考的是卷积神经网络系列之softmax loss对输入的求导推导}
3.在进一步,softmax层对前一层全连接层的求导
这里,先解释一下我所设置的层的情况:
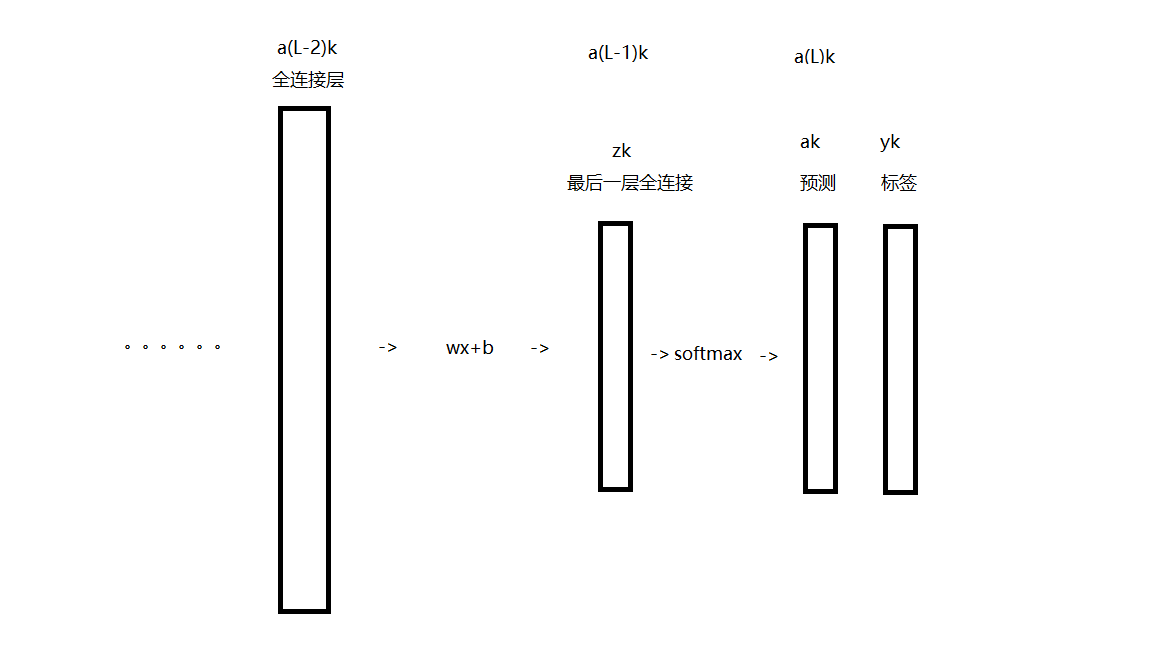
这里是两个全连接和一个softmax,输出的是prob向量。
上小节求得的结果是损失函数对a(L-1)k层向量的导数,这节,我们求损失函数对a(L-2)k层向量的导数。
首先介绍一下,我在下一篇会介绍全连接层的正向传播与反省传播。
这里要加一个番外篇,这个是我从博客softmax的log似然代价函数(公式求导)看到的。当时搜索的是求导到softmax层,不明白为啥还有w,b的事。后来理解了,它是直接求损失函数对a(L-2)k层向量的导数的。下面我把原文粘贴过来做参考。
为了检验softmax和这个代价函数也可以解决上述所说的训练速度变慢问题,接下来的重点就是推导ANN的权重w和偏置b的梯度公式。以偏置b为例:
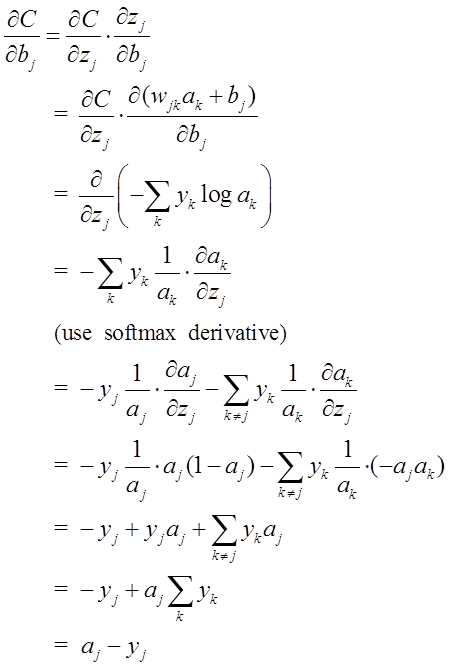
同理可得:

注意:这里
![]() 是a(L-1)k层的数据。
是a(L-1)k层的数据。
注:1.一个例子
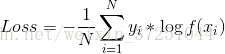
假设有一个batch有2个数据,那么,这里N = 2 ,假设一个5分类任务,一张图像经过softmax层后得到的概率向量f(xi)是[0.1,0.2,0.25,0.4,0.05],真实标签yi是[0,0,1,0,0],那么损失回传时该层得到的梯度就是f(xi)-yi=[0.1,0.2,-0.75,0.4,0.05]/N。这个梯度就指导网络在下一次forward的时候更新该层的权重参数。
注:2.我们一般成熟算法loss函数都有权值惩罚项,这里简单理解为见,没有写。
也有Loss函数使用如下形式(对权值进行了惩罚):

这里不做讨论。具体可以看:Softmax回归



评论(0)
您还未登录,请登录后发表或查看评论