

0. 前言
ubuntu下安装cuda、cuddn等NVIDIA机器学习、深度学习环境往往是在使用Linux中最头疼的配置步骤,同时,由于nvidia的cuda、cuddn版本众多,这让统一环境开发成为了难点。而Nvidia官方也认清楚了这一点,并基于docker开发了nvidia docker并且提供cuda镜像,这让我们完全不用考虑环境问题了
环境:
ubuntu20.04
docker 19.03
1. 安装docker
1.查看ubuntu内核
uname -r
2.安装docker
sudo apt-get install docker.io
3.查看版本
docker version 或 docker -v
4.启动
sudo systemctl unmask docker.service
sudo systemctl unmask docker.socket
sudo systemctl start docker.service
5.查看状态
sudo systemctl status docker
2. 修改docker源
sudo gedit /etc/docker/daemon.json
添加以下内容:(使用阿里源)
{
"registry-mirrors":[
"https://emasu4pd.mirror.aliyuncs.com",
"http://hub-mirror.c.163.com"
],
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
3. 从官网镜像获取镜像文件
- 拉取镜像(上海服务器)
docker pull registry.cn-shanghai.aliyuncs.com/tcc-public/super-mario-ppo:race
- 启动容器后台运行
docker run -id registry.cn-shanghai.aliyuncs.com/tcc-public/super-mario-ppo:race
- 查看容器内的文件
docker ps
- 结果如下
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3d747e7ccb2b 12f1b1d66471e "/bin/bash" 5 seconds ago Up 7 seconds xenodochial_dewdne
- 这个ID很重要,接下来ls 进入这个容器。
docker exec -it 3d747e7ccb2b /bin/bash
- 然后查看当前目录下的文件
root@3d747e7ccb2b:/workspace#
root@3d747e7ccb2b:/workspace# ls
__pycache__ core_lstm.py env.py gym-results ppo_lstm.py pretrain spinningup test_lstm.py
- 退出这个容器只需要exit即可。
root@3d747e7ccb2b:/workspace# exit #输入exit命令退出当前容器或按ctrl+D退出当前容器
4. 拷贝并更新回容器-本地更新
- 建立一个文件夹用来存储这些文件。
将该ID容器里的文件拷贝到你创建的文件夹中。
docker cp 3d747e7ccb2b:/workspace/ppo_lstm.py E:/tianchi_rl_submit/
- 将修改后的拷贝文件拷贝回容器
docker cp E:/tianchi_rl_submit/ppo_lstm.py 3d747e7ccb2b:/workspace/
- 更新镜像(自己的),这里是深圳服务器。
docker commit 3d747e7ccb2b registry.cn-shenzhen.aliyuncs.com/docker_tanchi/rl_submit:race
- 查看生成的镜像
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-shenzhen.aliyuncs.com/docker_tanchi/rl_submit race 12f1b1d66471 3 hours ago 11.2GB
registry.cn-shanghai.aliyuncs.com/tcc-public/python 3 a4cc999cf2aa 20 months ago 929MB
如此操作,大概理解了流程,这里都是本地的更新过程,那么再回顾官方的教程复习一遍,官方教程是完整的上传到个人仓库的一个过程。
- 将镜像打包成tar包
docker save -o xxx.tar imagexxx # 当前路径下会生成一个xxx.tar
- 将tar包生成镜像
docker load < xxx.tar # 生成的镜像跟之前打包的镜像名称一样
5. 官方教程-上传到仓库
- 输入用户名和密码
sudo docker login --username=xxxx
- 修改镜像标记,必须为自己注册账号的用户名开头
#docker tag [OPTIONS] IMAGE[:TAG] [REGISTRYHOST/][USERNAME/]NAME[:TAG]
sudo docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/egg_mario/mario:[镜像版本号]
- 将镜像推送到Registry
sudo docker push registry.cn-hangzhou.aliyuncs.com/egg_mario/mario:[镜像版本号]
在输入docker images后可以看到对应的TAG和IMAGE ID
如果提示denied: requested access to the resource is denied,那么再运行一下login即可。
6. nvidia-docker安装
- 开启docker服务
sudo systemctl --now enable docker
- 引入nvidia-docker源:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
- 更新源:
sudo apt update
- 安装nvidia-docker,重启docker服务:
sudo apt-get install nvidia-docker2
sudo systemctl restart docker
- 镜像载入
用以下指令载入一个带有cuda的镜像(启动命令中添加参数:–gpus all 或 —gpus “device=1”指定):
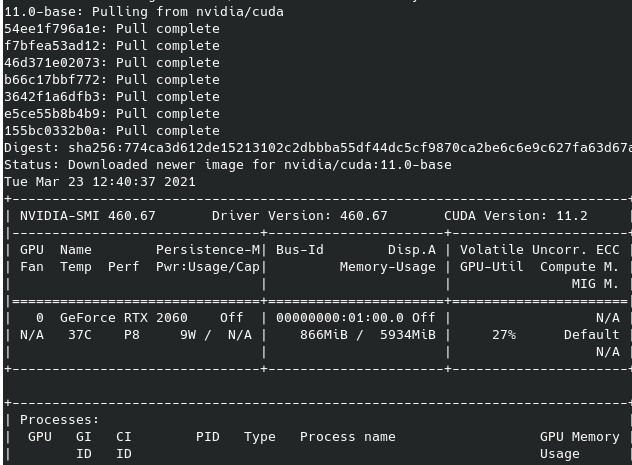
sudo docker run --rm --gpus all nvidia/cuda:10.0-base nvidia-smi
- 如果出现下图,则nvidia-docker安装成功:
- 然后将需要的包全部安装好,然后打包成镜像,并发布。
7. 参考链接
https://www.i4k.xyz/article/liuzhuomei0911/115176455
https://blog.csdn.net/weixin_45385568/article/details/115140719



评论(0)
您还未登录,请登录后发表或查看评论