

0. 前言
最近尝试着去在SLAM当中使用深度学习,而目前的SLAM基本上是基于C++的,而现有的Pytorch、Tensorflow这类框架均是基于python的。所以如何将Python这类脚本文件来在C++这类可执行文件中运行,这是非常有必要去研究的,而网络上虽然存在有例子,但是很多都比较杂乱,所以本篇文章将网络上常用的方法进行整理,以供后面初学者有迹可循
1. 模型认识
我们知道,目前基于C++存在两种方式,一种是通过Opencv加载训练好的模型和网络,而另一种则是通过TensorRT来进行C++的深度学习开发,TensorRT是Nvidia官方给的C++推理加速工具,如同OpenVINO之于Intel。支持诸多的AI框架,如Tensorflow,Pytorch,Caffe,MXNet等。
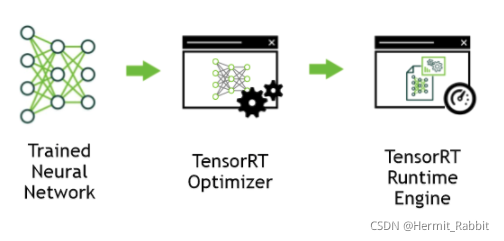
对于这类C++程序而言,其最重要是更加通用,同时支持模型自身运算的加速。
2. Opencv
实验流程为:Pytorch -> Onnx -> Opencv。即首先将Pytorch模型转换为Onnx模型,然后通过Opencv解析Onnx模型。
首先,参考pytorch官方文档中训练一个分类器的代码,训练一个简单的图像分类器。代码如下:
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.onnx
import torchvision
import torchvision.transforms as transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(images.shape)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 12, 3)
self.conv3 = nn.Conv2d(12, 32, 3)
self.fc1 = nn.Linear(32 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = x.view(-1, 32 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(100): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(outputs)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
上述代码相对于官方文档的代码,仅仅是增加了卷积层和利用GPU进行训练,且输出结果未经处理,只是简单输出各个类别的概率值。
训练完网络之后,将网络保存,代码如下:
# 保存网络结构和参数
# 方法1:保存网络结构和参数
PATH = './cifar_net.pth'
torch.save(net, PATH)
# 方法2:保存网络参数
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
# 方法3:导出网络到ONNX
dummy_input = torch.randn(1, 3, 32, 32).to(device)
torch.onnx.export(net, dummy_input, "torch.onnx")
# 方法4:保存网络位TORCHSCRIPT
dummy_input = torch.randn(1, 3, 32, 32).to(device)
traced_cell = torch.jit.trace(net, dummy_input)
traced_cell.save("tests.pth")
并通过方法3将保存好的ONNX模型输入到opencv中,并通过opencv提供的Net cv::dnn::readNetFromONNX ( const String & onnxFile )函数读取保存好的网络。代码实现如下:
//测试opencv加载pytorch模型
#include <opencv2/dnn.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
using namespace cv;
using namespace cv::dnn;
#include <fstream>
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
String modelFile = "./torch.onnx";
String imageFile = "./dog.jpg";
dnn::Net net = cv::dnn::readNetFromONNX(modelFile); //读取网络和参数
Mat image = imread(imageFile); // 读取测试图片
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
Mat inputBolb = blobFromImage(image, 0.00390625f, Size(32, 32), Scalar(), false, false); //将图像转化为正确输入格式
net.setInput(inputBolb); //输入图像
Mat result = net.forward(); //前向计算
cout << result << endl;
}
3. TensorRT
实验流程为:Pytorch -> Onnx -> TensorRT 或者Pytorch-> TensorRT。创建TensorRT引擎及进行前向推理,下面将分成两节来描述不同的方法。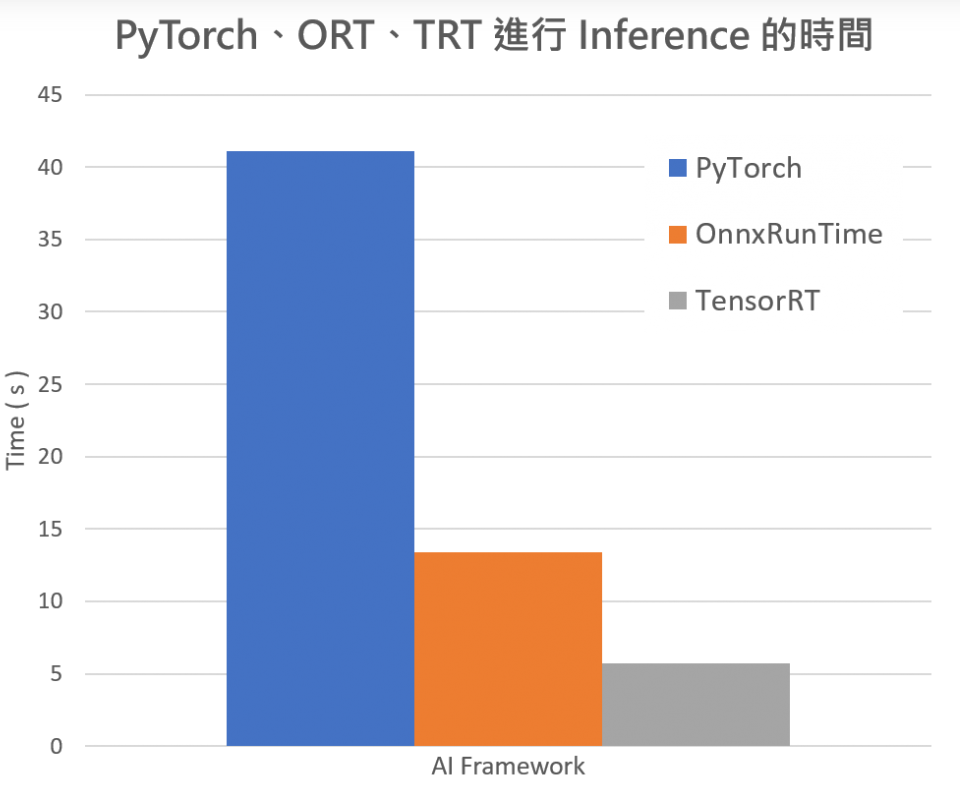
Pytorch-> TensorRT(只支持Python)
这里用到的库是torch2trt,安装这个库要保证TensorRT已经安装好,而且cudatoolkit是对应PyTorch版本的(之前debug了好久发现的问题,希望你们不会遇到)。
git clone https://github.com/NVIDIA-AI-IOT/torch2trt
cd torch2trt
python setup.py install
按照官方的README.md以及demo:
import torch
from torch2trt import torch2trt
from torchvision.models.alexnet import alexnet
# create some regular pytorch model...
model = alexnet(pretrained=True).eval().cuda()
# create example data
x = torch.ones((1, 3, 224, 224)).cuda()
# convert to TensorRT feeding sample data as input
model_trt = torch2trt(model, [x])
这里首先把pytorch模型加载到CUDA,然后定义好输入的样例x(这里主要用来指定输入的shape,用ones, zeros都可以)。model_trt就是转成功的TensorRT模型,你运行上面代码没报错就证明你转tensorRT成功了。
这里有一个小坑就是,原模型和tensorRT模型可能占2份GPU内存(额,也可能是我多虑,没做进一步实验)。那就可以先把tensorRT模型保存下来,下次推理的时候直接加载tensorRT模型就好:
torch.save(model_trt.state_dict(), 'alexnet_trt.pth')
from torch2trt import TRTModule
model_trt = TRTModule()
model_trt.load_state_dict(torch.load('alexnet_trt.pth'))
#............................
y = model(x)
y_trt = model_trt(x)
# check the output against PyTorch
print(torch.max(torch.abs(y - y_trt)))
Pytorch -> Onnx -> TensorRT
这种TensorRT的转换方法是存在C++和Python版本的,这里都提一下。
python导入方法
TensorRT的加载模型执行推理的步骤基本上跟OpenVINO与OpenCV DNN很相似,唯一区别的地方在于使用tensorRT做推理,首先需要把数据从内存搬到显存,处理完之后再重新搬回内存,然后解析输出。基本步骤与代码如下:创建网络,并将其转为ONNX版本的模型文件
#--*-- coding:utf-8 --*--
import onnx
import torch
import torchvision
import netron
net = torchvision.models.resnet18(pretrained=True).cuda()
# net.eval()
export_onnx_file = "./resnet18.onnx"
x=torch.onnx.export(net, # 待转换的网络模型和参数
torch.randn(1, 3, 224, 224, device='cuda'), # 虚拟的输入,用于确定输入尺寸和推理计算图每个节点的尺寸
export_onnx_file, # 输出文件的名称
verbose=False, # 是否以字符串的形式显示计算图
input_names=["input"]+ ["params_%d"%i for i in range(120)], # 输入节点的名称,这里也可以给一个list,list中名称分别对应每一层可学习的参数,便于后续查询
output_names=["output"], # 输出节点的名称
opset_version=10, # onnx 支持采用的operator set, 应该和pytorch版本相关,目前我这里最高支持10
do_constant_folding=True, # 是否压缩常量
dynamic_axes={"input":{0: "batch_size", 2: "h"}, "output":{0: "batch_size"},} #设置动态维度,此处指明input节点的第0维度可变,命名为batch_size
)
# import onnx # 注意这里导入onnx时必须在torch导入之前,否则会出现segmentation fault
net = onnx.load("./resnet18.onnx") # 加载onnx 计算图
onnx.checker.check_model(net) # 检查文件模型是否正确
onnx.helper.printable_graph(net.graph) # 输出onnx的计算图
import onnxruntime
import numpy as np
netron.start("./resnet18.onnx")
session = onnxruntime.InferenceSession("./resnet18.onnx") # 创建一个运行session,类似于tensorflow
out_r = session.run(None, {"input": np.random.rand(16, 3, 256, 224).astype('float32')}) # 模型运行,注意这里的输入必须是numpy类型
print(len(out_r))
print(out_r[0].shape)
然后将onnx文件导入到TensorRT中用于加速,并生成trt的TensorRT模型文件。
import tensorrt as trt
from log import timer, logger
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
def build_engine(onnx_path, shape = [1,224,224,3]):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(1) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = (256 << 20)
# 256MiB
builder.fp16_mode = True
# fp32_mode -> False
with open(onnx_path, 'rb') as model:
parser.parse(model.read())
engine = builder.build_cuda_engine(network)
return engine
def save_engine(engine, engine_path):
buf = engine.serialize()
with open(engine_path, 'wb') as f:
f.write(buf)
def load_engine(trt_runtime, engine_path):
with open(engine_path, 'rb') as f:
engine_data = f.read()
engine = trt_runtime.deserialize_cuda_engine(engine_data)
return engine
if __name__ == "__main__":
onnx_path = './resnet18。onnx'
trt_path = './resnet18.trt'
input_shape = [1, 224, 224, 3]
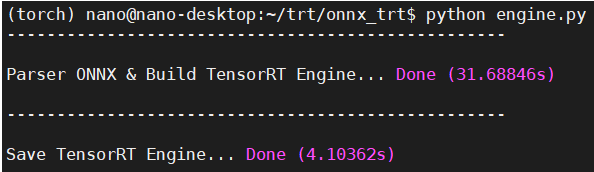
build_trt = timer('Parser ONNX & Build TensorRT Engine')
engine = build_engine(onnx_path, input_shape)
build_trt.end()
save_trt = timer('Save TensorRT Engine')
save_engine(engine, trt_path)
save_trt.end()
c++导入方法
第一步也是将建立模型并解析ONNX格式模型文件(这里借用这篇文章的例子)
IBuilder* builder = createInferBuilder(gLogger);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
auto parser = nvonnxparser::createParser(*network, gLogger);
// 解析ONNX模型
parser->parseFromFile(onnx_filename.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load onnx mnist model...\n");
创建推理引擎并获取输入与输出名称,格式
// 创建推理引擎
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1 << 20);
config->setFlag(nvinfer1::BuilderFlag::kFP16);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
IExecutionContext *context = engine->createExecutionContext();
// 获取输入与输出名称,格式
const char* input_blob_name = network->getInput(0)->getName();
const char* output_blob_name = network->getOutput(0)->getName();
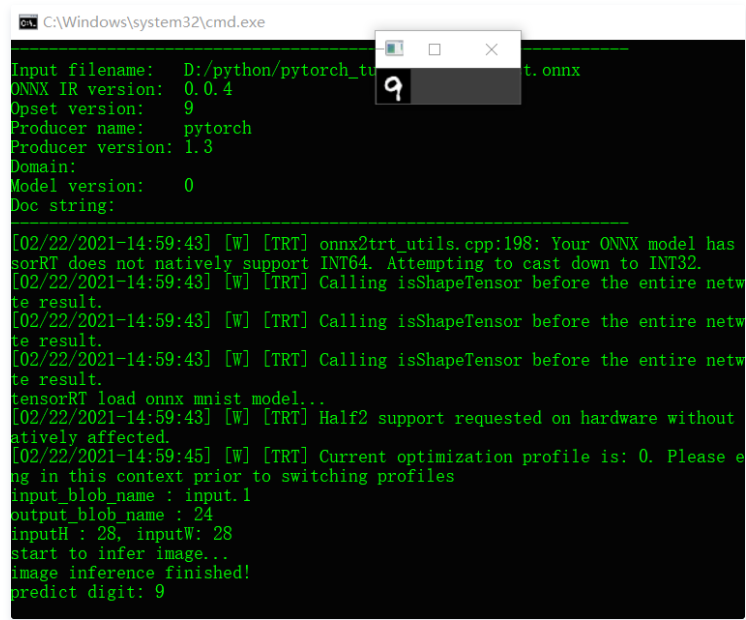
printf("input_blob_name : %s \n", input_blob_name);
printf("output_blob_name : %s \n", output_blob_name);
const int inputH = network->getInput(0)->getDimensions().d[2];
const int inputW = network->getInput(0)->getDimensions().d[3];
printf("inputH : %d, inputW: %d \n", inputH, inputW);
设置输入数据并创建GPU缓冲区
// 预处理输入数据
Mat image = imread("D:/images/9_99.png", IMREAD_GRAYSCALE);
imshow("输入图像", image);
Mat img2;
image.convertTo(img2, CV_32F);
img2 = (img2 / 255 - 0.5) / 0.5;
// 创建GPU显存输入/输出缓冲区
void* buffers[2] = { NULL, NULL };
int nBatchSize = 1;
int nOutputSize = 10;
cudaMalloc(&buffers[0], nBatchSize * inputH * inputW * sizeof(float));
cudaMalloc(&buffers[1], nBatchSize * nOutputSize * sizeof(float));
// 创建cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
void *data = malloc(nBatchSize * inputH * inputW * sizeof(float));
memcpy(data, img2.ptr<float>(0), inputH * inputW * sizeof(float));
模型计算
// 内存到GPU显存
cudaMemcpyAsync(buffers[0], data, \
nBatchSize * inputH * inputW * sizeof(float), cudaMemcpyHostToDevice, stream);
std::cout << "start to infer image..." << std::endl;
// 推理
context->enqueueV2(buffers, stream, nullptr);
// 显存到内存
float prob[10];
cudaMemcpyAsync(prob, buffers[1], 1 * nOutputSize * sizeof(float), cudaMemcpyDeviceToHost, stream);
// 同步结束,释放资源
cudaStreamSynchronize(stream);
cudaStreamDestroy(stream);
解析输出与打印
// 解析输出
std::cout << "image inference finished!" << std::endl;
Mat result = Mat(1, 10, CV_32F, (float*)prob);
float max = result.at<float>(0, 0);
int index = 0;
for (int i = 0; i < 10; i++)
{
if (max < result.at<float>(0,i)) {
max = result.at<float>(0, i);
index = i;
}
}
std::cout << "predict digit: " << index << std::end
4. 参考链接
https://www.136.la/nginx/show-176224.html
https://blog.csdn.net/cai1493105270/article/details/108127290
https://cloud.tencent.com/developer/article/1800743
https://www.jianshu.com/p/3c2fb7b45cc7
https://blog.csdn.net/weixin_39757626/article/details/111109461
https://blog.csdn.net/qq_38003892/article/details/89225636
https://www.rs-online.com/designspark/nvidia-cudagpujetson-nano-tensorrt-2-cn



评论(0)
您还未登录,请登录后发表或查看评论