

0. 简介
Intel的CPU和ARM的CPU都有SIMD指令,可以完成CPU 指令级的并行化。这里边主要涉及CPU的汇编的知识和一些寄存器的知识。在一些耗时的SLAM优化迭代的场合,经常出现这样的指令的优化。SSE是Intel x86架构CPU的SIMD指令的简称,NEON是ARM CPU的SIMD指令的简称。
最近在jetson的ARM架构平台下发现在移植slam的代码的时候,无法快速处理,而GPU本身需要处理一些深度学习模型文件,所以需要使用一些并行加速代码。作为学习,因此这里做了一些两种SIMD指令的转化和比较。
1. 基础定义
一般computer中存在内存,内存就像仓库,而CPU中的寄存器则代表了一次性可以拿出多少东西。寄存器的位数和指令的位宽是一样的。我们说128位的指令位宽,那么对应的寄存器的位数就是128位,而CPU每次可以计算的数据的宽度最大也是128位。因为我们常用的数据达不到这样的宽度,这样每个指令周期就可以执行多个数据的计算。这就是所谓向量化计算。比如浮点数占4个字节或者8个字节,而整数却可以分别占1,2,4个字节,按照应用场合不同使用的不同,因此向量化加速也不同。因此一个指令最多完成4个浮点数计算。而可以完成16个int8_t数据的计算。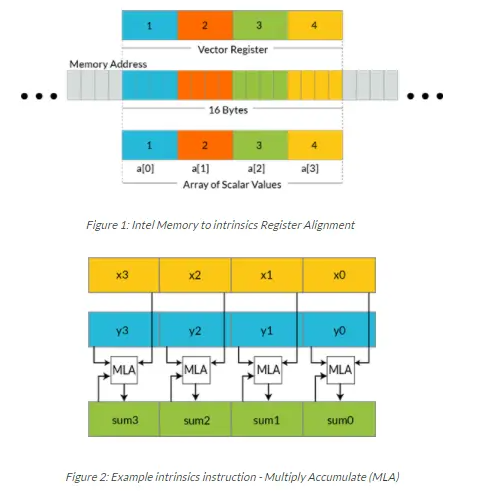
2. NENO与SSE的指令对比
tip:这里的f代表浮点数,p代表指针,i代表整数, m128代表了float32x4的数组
|SSE|NEON| 功能|
|—|—|—|
|_mm_set1_ps(_f)|vreinterpretq_m128_f32(vdupq_n_f32(_f)) |Create a vector with all four elements equal to F|
|_mm_load_ps(_p)|vreinterpretq_m128_f32(vld1q_f32(_p)); |Memory TO register|
| _mm_setr_epi32(i3,i2,i1,i0)|vreinterpretq_m128i_s32(vld1q_s32(int32_t __attribute__((aligned(16))) data[4])); | 按相反顺序设置4个有符号32位整数值|
| _mm_cmpneq_ps(m128_f0, m128_f1)| vreinterpretq_m128_u32( vmvnq_u32( vceqq_f32(vreinterpretq_f32_m128(m128_f0), vreinterpretq_f32_m128(m128_f1)) ) ) | 不平等的比较 |
| _mm_or_ps(m128_a, m128_b) |vreinterpretq_m128_s32( vorrq_s32(vreinterpretq_s32_m128(m128_a), vreinterpretq_s32_m128(m128_b)) )| 计算a和b的四个单精度浮点值的位或 |
| _mm_and_ps(m128_a, m128_b) | vreinterpretq_m128_s32( vandq_s32(vreinterpretq_s32_m128(m128_a), vreinterpretq_s32_m128(m128_b)) ) | 计算和的四个单精度浮点值的位和 |
|_mm_add_ps(m128_a, m128_b)|vreinterpretq_m128_f32(vaddq_f32(vreinterpretq_f32_m128(m128_a), vreinterpretq_f32_m128(m128_b)))|加法运算|
|_mm_mul_ps(m128_a, m128_b) | vreinterpretq_m128_f32(vmulq_f32(vreinterpretq_f32_m128(m128_a), vreinterpretq_f32_m128(m128_b)) |乘法运算|
|_mm_store_ps(_p, m128_a)| vst1q_f32(_p, vreinterpretq_f32_m128(m128_a));|register to Memory|
3. 优化技巧
- 注意指令的顺序,为什么呢,因为CPU是流水线工作的,因此相邻的指令开始的执行的时间并非一个指令执行完毕之后才会开始,但是一旦遇到数据联系,这时候会发生阻塞,如果我们很好的安排指令的顺序,使得数据相关尽量少发生,或者发生的时候上一个指令已经执行完了。因此注意稍微修改指令的执行顺序就会使得代码变快,是不是特别神奇?
- 适当的循环展开,适当注意仅仅是适当,目的还是减少数据相关,不过展开太多怕被鄙视啊。
4. 相关官网链接
neon指令权威官网:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics
neon指令中文速查:https://blog.csdn.net/billbliss/article/details/78924636
neon指令总结,参考这篇文章:https://blog.csdn.net/xiongtiancheng/article/details/77103810
SSE相关发展:https://www.wanweibaike.net/wiki-SSE?new
SSE指令总结,参考这篇文章: https://blog.csdn.net/qq_27825451/article/details/103934359
5. NENO示例
向量相乘:
下面的运算就是向量的每一维相乘然后相加,相乘之间具有良好的并行性,所以可以通过ARM NEON intrinsic指令进行加速。下面是代码实现:
inline float dot(const float* A, const float* B, int K)
{
float sum = 0;
float32x4_t sum_vec = vdupq_n_f32(0);//, left_vec, right_vec;
for (int k = 0; k<K; k += 8)
{
sum_vec = vmlap_f32(sum_vec, vld1q_f32(A + k), vld1q_f32(B + k));
sum_vec = vmlap_f32(sum_vec, vld1q_f32(A + k + 4), vld1q_f32(B + k + 4));
// sum_vec = vmlap_f32(sum_vec, vld1q_f32(A + k+8), vld1q_f32(B+k+8));
// sum_vec = vmlap_f32(sum_vec, vld1q_f32(A + k+12), vld1q_f32(B+k+12));
}
float32x2_t r = vadd_f32(vget_high_f32(sum_vec), vget_low_f32(sum_vec));
sum += vget_lane_f32(vpadd_f32(r, r), 0);
return sum;
}
exp加速:
算法的基本原理是考虑了float数据类型在内存中的布局而精巧设计的,想了解更多细节可以参考原博客,本文只介绍如何将其用ARM NEON intrinsic指令进行加速(相比原始博客,代码中第二个常量有点变化,该新常量是我试验出来的,误差更小)。
ARM NEON intrinsic指令的优势是并行计算,所以我们对一个数组的每一个元素进行exp并相加,然后将其加速:
inline float expf_sum(float* score,int len)
{
float sum=0;
float32x4_t sum_vec=vdupq_n_f32(0);
float32x4_t ai=vdupq_n_f32(1064807160.56887296), bi;
int32x4_t int_vec;
int value;
for(int i=0;i<len;i+=4)
{
bi=vld1q_f32(score+4*i);
sum_vec=vmlaq_n_f32(ai,bi,12102203.1616540672);
int_vec=vcvtq_s32_f32(sum_vec);
value=vgetq_lane_s32(int_vec,0);
sum+=(*(float*)(&value));
value=vgetq_lane_s32(int_vec,1);
sum+=(*(float*)(&value));
value=vgetq_lane_s32(int_vec,2);
sum+=(*(float*)(&value));
value=vgetq_lane_s32(int_vec,3);
sum+=(*(float*)(&value));
}
return sum;
}
6. 参考链接
https://x007dwd.github.io/2017/03/18/SSE-vs-NEON/
https://blog.csdn.net/qq_20880415/article/details/101290987
https://blog.csdn.net/qq_20880415/article/details/100050059
https://aijishu.com/a/1060000000217479
https://github.com/intel/ARM_NEON_2_x86_SSE
https://github.com/jratcliff63367/sse2neon
https://blog.csdn.net/jgj123321/article/details/95633431
https://blog.csdn.net/qq_27825451/article/details/103934359
https://blog.csdn.net/weixin_40593924/article/details/104972350


评论(0)
您还未登录,请登录后发表或查看评论