

0. 前言
在C++编程中,我们经常会发现段错误这类问题,而这类问题经常是指访问的内存超出了系统所给这个程序的内存空间。一般是随意使用野指针或者数组、数组越界等原因造成的。段错误是指访问的内存超出了系统给这个程序所设定的内存空间,例如访问了不存在的内存地址、访问了系统保护的内存地址、访问了只读的内存地址等等情况。此前我们也在博客中讲述了通过GDB对ROS的调试,而段错误也会通过这样类似的形式运行并获得。
1. 什么是core dumped?
core dumped即段错误,当然它也有更官方的说法,称之为核心转储。当某一个进程在异常退出时,内核有可能把该程序当前内存映射到core文件里,即以文件的方式存储于硬盘上,方便后续的gdb调试。
2. 段错误种类
2.1. 使用非法的内存地址(指针),包括使用未经初始化及已经释放的指针、不存在的地址、受系统保护的地址,只读的地址等,这一类也是最常见和最好解决的段错误问题,使用GDB print一下即可知道原因。
// 访问不存在的内存地址
#include<stdio.h>
#include<stdlib.h>
void main()
{
int *ptr = NULL;
*ptr = 0;
}
// 访问系统保护的内存地址
#include<stdio.h>
#include<stdlib.h>
void main()
{
int *ptr = (int *)0;
*ptr = 100;
}
// 栈溢出
#include<stdio.h>
#include<stdlib.h>
void main()
{
main();
}
2.2. 内存读/写越界。包括数组访问越界,或在使用一些写内存的函数时,长度指定不正确或者这些函数本身不能指定长度,典型的函数有strcpy(strncpy),sprintf(snprint)等等。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void main()
{
char *ptr = "test";
strcpy(ptr, "TEST");
}
2.3. 对于C++对象,应该通过相应类的接口来去内存进行操作,禁止通过其返回的指针对内存进行写操作,典型的如string类的c_str()接口,如果你强制往其返回的指针进行写操作肯定会段错误的,因为其返回的地址是只读的。
这类问题是强调返回的指针可以把数据拿出来,但是别对不定长的指针接口去使用改变内存的方式来实现,可以转成string这类后再次操作。
2.4. 函数不要返回其中局部对象的引用或地址,当函数返回时,函数栈弹出,局部对象的地址将失效,改写或读这些地址都会造成未知的后果。
这类问题举个例子:由于某函数声明了返回值(应该返回一个shared_ptr),但是函数实现忘记return导致的,虽然使用这个函数时没有用到它的返回值,但是依然报错!段错误如果找不到原因可以看看函数是否忘记写返回值了,平时也要留意编译器的warning。
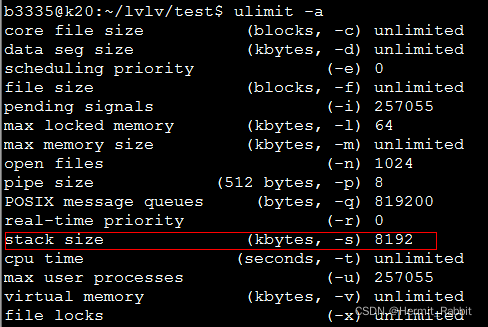
2.5. 避免在栈中定义过大的数组,否则可能导致进程的栈空间不足,此时也会出现段错误,同样的,在创建进程/线程时如果不知道此线程/进程最大需要多少栈空间时最好不要在代码中指定栈大小,应该使用系统默认的,这样问题比较好查,ulimit一下即可知道。这类问题也是为什么我的程序在其他平台跑得好好的,为什么一移植到这个平台就段错误了。
ulimit -s
10240
可以看到linux配置的线程栈的大小为10M。
如果BUFF_SZ设置过大,则当执行到printf调用函数就会出段错误,这说明找不到函数地址。数组大小BUFF_SZ是自己定义的全局常量,这个常量由于业务需求被定的较大(50MB左右)。这就是问题症结所在!这样的数组定义占用的是线程栈内存,可是linux线程所占栈内存上限一般为8MB。这样buffer实际上刷满了整个线程栈内存,才会导致执行时线程内找不到函数入口。
void* thread_func(void* rank) {
long my_rank = (long) rank;
printf("thread %ld is working...\n", my_rank);
//...
char buffer[BUFF_SZ];
//...
}
2.6. 操作系统的相关限制,如:进程可以分配的最大内存,进程可以打开的最大文件描述符个数等,在Linux下这些需要通过ulimit、setrlimit、sysctl等来解除相关的限制,这类段错误问题在系统移植中也经常发现,以前我们移植Linux的程序到VxWorks下时经常遇到(VxWorks要改内核配置来解决)。
struct GPU_task_head head;//局部栈空间上的变量
cout<<"sizeof(GPU_task_head):"<<sizeof(GPU_task_head)<<endl;
memset(&head,0,sizeof(GPU_task_head));//运行时出错
此时我们可以看到在该进程里面memset前面Struct大小已经超过进程大小,属于越界了。
2.7. 多线程的程序,涉及到多个线程同时操作一块内存时必须进行互斥,否则内存中的内容将不可预料。
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>
using namespace std;
int g_num = 0; // 为 g_num_mutex 所保护
mutex g_num_mutex;
void slow_increment(int id)
{
for (int i = 0; i < 3; ++i)
{
// g_num_mutex.lock();
++g_num;
cout << id << " => " << g_num << endl;
// g_num_mutex.unlock();
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
thread t1(slow_increment, 0);
thread t2(slow_increment, 1);
t1.join();
t2.join();
}
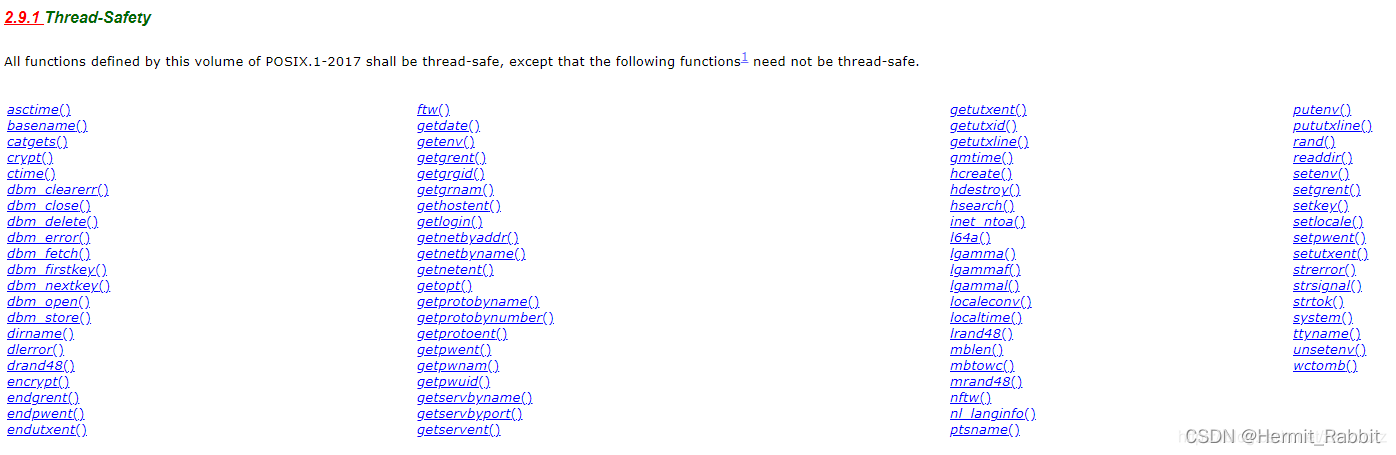
2.8. 在多线程环境下使用非线程安全的函数调用,例如 strerror 函数等。这个一般是c语言中的,在c++中也需要注意。
例如:exit调用会终止整个进程,在_exit的基础上执行一系列用户空间操作比如刷新缓冲区。_exit是直接交给内核,exit先执行清除操作再交给内核。exit或_exit时,系统无条件的停止剩下所有操作。
https://pubs.opengroup.org/onlinepubs/9699919799/functions/V2_chap02.html#tag_15_09
#include<iostream>
#include<stdlib.h>
#include<pthread.h>
#include<unistd.h>
using namespace std;
void fun(){
exit(1);//###1### 刷新流,析构全局对象,1表示异常返回给调用者,调用者可以根据该值进行相应处理
//_exit(0);//###2### 不会刷新流等,不会析构全局对象
}
class test{
public:
test(){
pthread_mutex_init(&mutex,NULL);
}
void doit(){
pthread_mutex_lock(&mutex);
fun();
pthread_mutex_unlock(&mutex);
}
~test(){
cout<<"~test"<<endl;
pthread_mutex_lock(&mutex);//可能引起死锁
pthread_mutex_unlock(&mutex);
}
private:
pthread_mutex_t mutex;
};
test one;//###3###exit会析构全局对象造成死锁,_exit不会析构全局对象
int main(){
//test one;//###4###局部对象不会被exit/_exit终止析构
one.doit();
}
2.9. 在有信号的环境中,使用不可重入函数调用,而这些函数内部会读或写某片内存区,当信号中断时,内存写操作将被打断,而下次进入时将无法避免地出错。
例如:样例代码中调用了printf函数,但是这个函数是一个不可重入函数,所以在信号处理函数里调用的话可能会引起问题。具体的是,在信号处理函数里调用printf函数的瞬间,引起程序死锁的可能性还是有的。但是,这个问题跟具体的时机有关系,所以再现起来很困难,也就成了一个很难解决的bug了。
int gSignaled;
void sig_handler(int signo) {
std::printf("signal %d received!\n", signo);
gSignaled = 1;
}
int main(void) {
struct sigaction sa;
// (省略)
sigaction(SIGINT, &sa, 0);
while(!gSignaled) {
//std::printf("waiting\n");
struct timespec t = { 1, 0 }; nanosleep(&t, 0);
}
2.10. 跨进程传递某个地址,传递的都是经过映射的虚拟地址,对另外一个进程是不通用的。
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信机制。
这里可以参考之前写的Python多进程通信的博客、以及C++博客
1.管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
2.命名管道(named pipe/FIFO):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
3.共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
4.信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;Linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
5.内存映射(mmap):mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
6.消息(Message)队列:消息队列是消息链式队列,消息被读完就删除,可以供多个进程间通信。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
3. ROS段错误调试
3.1. dmesg命令
‘dmesg’命令显示linux内核的环形缓冲区信息,我们可以从中获得诸如系统架构、cpu、挂载的硬件,RAM等多个运行级别的大量的系统信息。
当计算机启动时,系统内核(操作系统的核心部分)将会被加载到内存中。在加载的过程中会显示很多的信息,在这些信息中我们可以看到内核检测硬件设备。
3.2. GDB调试
在ROS中我们除了通过launch启动外还可以通过添加GDB调试指令(cmd)启动,这种方式和传统的程序运行基本一致。所以其段错误内容也可以类似的获取。
下面看一个简短的程序(非法赋值):
#include <stdio.h>
int main()
{
char* str = "hello world";
str[1] = 'H';
return 0;
}
运行结果:
当我们出现core dump时,如何获取具体的错误信息?我们先使用ulimit -a命令来查看系统资源限制。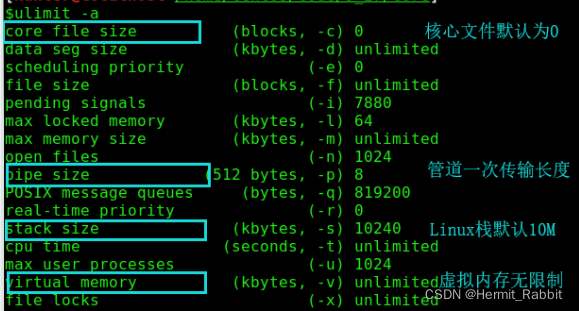
默认为0,即不会生成core文件,需要修改core file size的值在编译链接时生成core file。
既然core file存储了错误信息,目的是后续的gdb调试,那么为什么操作系统(在Linux下)默认关闭?
如果操作系统对core
file默认开启,一旦程序上线之后,程序就脱离了程序员的管理范畴,此时程序员可能不知情,程序一直重启挂掉重启挂掉,那么你的硬盘上就会dump出很多文件,将你的硬盘空间慢慢吞噬,甚至将你的操作系统挂掉。
我们可以使用ulimit -c来改变core文件的大小(临时改变,重启后恢复默认):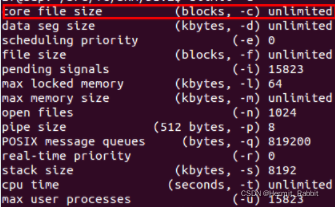
现在我们执行刚才的程序看是否生成了core文件。
从上述结果可以看出,此时重新编译链接会生成一个core.5321的文件,5321为引起错误的进程id。进入gdb模式并定位dump信息需要两步:
① gdb [可执行程序] [dump文件] 进入gdb模式。
② 使用where或core-file [core.(进程号)]定位dump的错误信息。
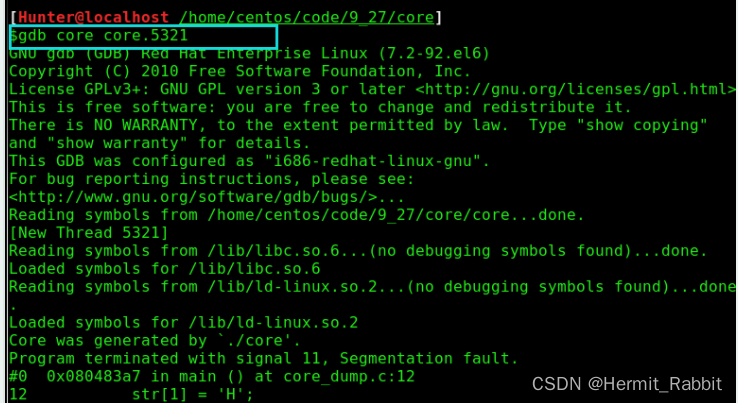
从结果可以看出,程序第12行出错,快速定位了dump的位置。以上就是gdb模式下dump错误信息的定位,下一节我将对gdb的使用技巧作以阐述。
tip:当然也可以直接不保存中间文件,直接使用该方式启动
4. 参考链接
https://blog.csdn.net/qq_41035588/article/details/82884859
https://blog.csdn.net/chen1415886044/article/details/108175581
https://hermit.blog.csdn.net/article/details/106882721
https://www.bbsmax.com/search/%E6%AE%B5%E9%94%99%E8%AF%AF/
https://www.bbsmax.com/A/nAJv6eqmJr/
https://www.cnblogs.com/zhenjing/archive/2010/12/22/signal_fork_thread.html
https://blog.csdn.net/weixin_38416696/article/details/90719388



评论(0)
您还未登录,请登录后发表或查看评论