

LeNet
1998年由Yann LeCun, Leon Bottou, Yoshua Bengio, Patrick Haffner发表,众所周知其中的两人已经被授予了2018年图灵奖。
这篇文章的重要性不言而喻,其中有很多重要的概念。它的核心网络结构,被称为LeNet-5
网络的特点来概括一下:网络一共7层,池化使用的是全局 pooling,激活函数使用的是Sigmoid,输出层使用径向基函数,网络结构简单参数量少,用于识别MNIST数据集挺好用。
为了学习第一手资料,我们还是对照原文来进行学习,当然了,也会增加一些理解部分。
网络结构
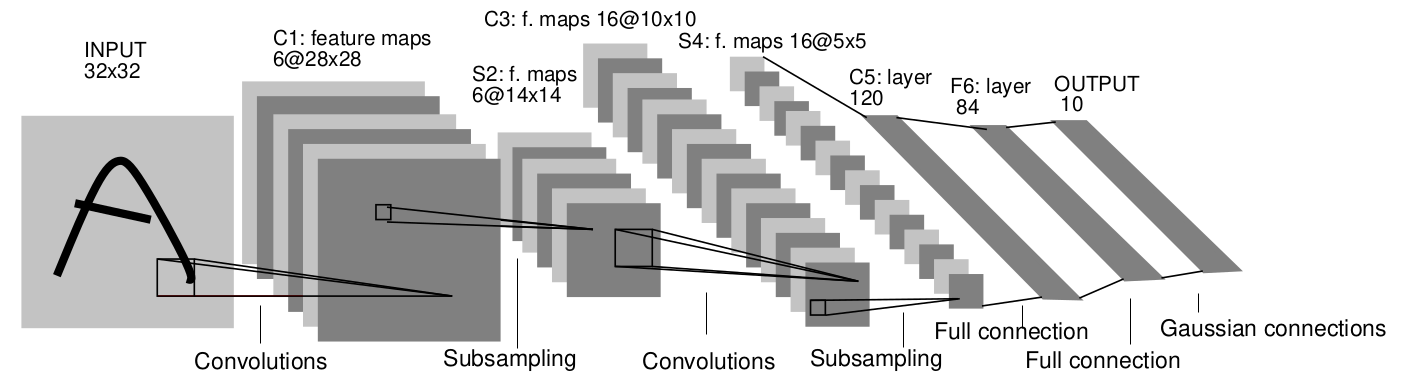
LeNet-5 网络虽然很小,但是它包含了基本模块:卷积层,池化层,全连接层,是其他深度学习模型的基础。
LeNet-5共有7层(layer),不包含输入,每层都包含可以训练(也是需要训练)的参数(权重weight)
卷积层标记为Cx,下采样层标记为Sx,全连接层标记为Fx,其中x是层索引。
我们接下来对每一层进行分析
输入层INPUT
输入图像的尺寸是32*32,这一层不算在7层之中。
卷积层C1
卷积层C1是具有6个特征图(Feature map)的卷积层。每个特征图中的每个单元都连接到输入中的5x5邻域。特征图的大小为28x28,可防止来自输入的连接掉入边界。C1包含156个可训练参数和122304个连接。
数字解释:
156:原始图中有32*32个像素点,在相邻的5x5像素上进行卷积操作。以第1个Feature map为例,5x5=25个像素值分别乘以25个权重,再在这25个加权值之和上再加一个bias值(偏置值),得到了Feature map上的一个像素点。由于使用了权值共享来减少参数量,第1个Feature map会一直使用这同一组参数,也就是5x5+1 = 26个。C1层一共有6个feature map,因此训练参数就是 6x26 = 156个
122304:32x32像素的原始图,经过5x5的卷积核,最终的尺寸会比原尺寸要小 5-1=4,可以自行滑动窗口来理解。以第1个feature map为例,它的尺寸是 28x28,也就是拥有 28x28 = 784个像素点。每个像素点连接了25个输入图上的像素点,别忘了还有一个bias值的点(把最后的相加操作也理解成一个连接),意思就是每个像素点会拥有26个连接。那么总的连接数就是 784x26 = 20384个连接。再算上所有的feature map,连接数就是 20384x6=122304了。
下采样层S2
层S2是一个具有6个14x14大小的特征图的下采样层。每个特征图中的每个单元连接到C1中相应特征图的2x2邻域。S2中每个单元的四个输入相加,然后乘以可训练系数,在加上一个可训练的偏差bias。结果还要过一次sigmoid函数。2x2感受野是不重叠的,因此S2中的特征图的行数和列数是C1中特征图的一半。S2层具有12个可训练参数和5880个连接。
数字解释:
12:以1个Feature map为例,它的尺寸是28x28,按照 2x2 的划分方式可以分为 14x14个。每个2x2格子中的操作都是把4个数加起来,把它们的和乘以一个数,再加上一个数。每个Feature map使用的都是相同的2个数。因此全部Feature map的参数就是2x6 = 12个
5880:以1个Feature map为例,每个图像的尺寸是 14x14=196个像素点。每个像素点连接了C1层的4个像素点和1个偏置bias,一共的连接数就是196x5 = 980个连接。一共6个 Feature map,连接总数就是 980x6=5880个连接
卷积层C3
层C3是具有16个特征图的卷积层。每个特征图中的每个单元连接到S2特征图子集中相同位置的5x5邻域。下表显示了由每个C3特征图都是哪几个S2特征图的集合。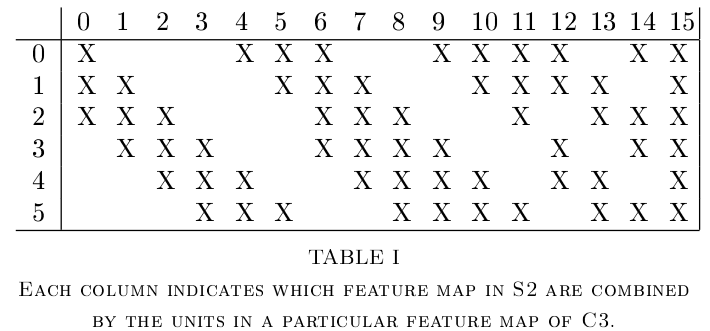
为什么不将每个S2特征图连接到每个C3特征图?原因有两方面。首先,非全连接的方案,可以将连接数控制在合理范围内(减少计算量);更重要的是,它迫使网络中的对称性中断。不同的特征图被迫提取不同的特征,因为它们的输入特征图不同(不同的C3提取的是不同的S2,且不再对称了,而且这些S2特征图的特征存在概率是互补的,我们希望这样)。表中连接方案的基本原理如下。前六个C3特征图从S2中三个特征图的每个连续子集获取输入。后六个C3特性图从四个特征图中的每个连续子集中获取输入。接下来的三个C3从四个不连续子集S2中获取输入。最后一个C3从所有S2特征图中获取输入。层C3具有1516个可训练参数和151600个连接。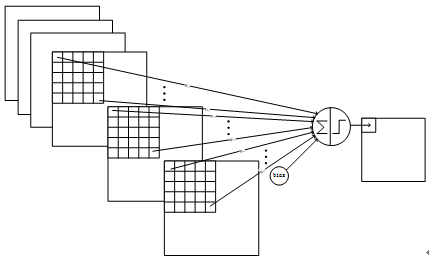
理解6个S2层Feature map通过16种卷积核得到16个C3层Feature map至关重要。
卷积核,并不一定都是1层,尺寸为 nxn 的。也可能是m层,尺寸为 nxn 的。
以前4个C3特征图,也就是表中0,1,2,3列为例,每个C3层的像素点,是这样计算得到的:第0个S2特征图的5x5邻域去和一个5x5权重进行点乘,第1个S2特征图的的5x5邻域去和另一个5x5权重进行点乘,第2个S2特征图同样也是如此。我们会得到3个点乘后的值,我们把这三个值加在一起,再加上一个bias,得到的就是C3层的一个像素点的值。换句话说,C3层的第0个Feature map,是3个S2层的Feature map,经过一个3层5x5的卷积核计算出来的。
讲明白这个,我们来看参数的计算。
数字解释:
1516:我们把C3层的特征图分为4组,第一组标号012345,它们都是由3个相连S2计算出来的。以第0个C3层特征图为例,它的参数是一个3层5x5卷积核加一个bias构成的,因此参数量是 3x5x5+1 = 76个,第一组一共 6x76 = 456个参数。第二组标号为67891011,它们都是由4个相连S2计算出来的。以第6个C3层特征图为例,它的参数是一个4层5x5的卷积核加一个bias构成的,因此参数量是 4x5x5+1 = 101个,第二组一共 6x101 = 606个。以此类推,第三组121314,参数量为3x(4x5x5+1) = 303个;第四组只有15,参数量为 6x5x5+1=151个。总的参数量为 456 + 606 + 303 + 151 = 1516个参数。
151600:这次连接数好计算了。上面算的是参数量,我们发现16个特征图的第一个像素点的连接数之后,就是参数的个数。因此 1516x10x10 = 151600就是总的连接数
下采样层S4
层S4是具有16个尺寸为5x5的特征图的子采样层。每个特征图中的计算方式与C1到S2类似,每个像素点连接到C3中相应特征图的2x2邻域。层S4具有32个可训练参数和2000个连接。
数字解释:
32:(1+1)x16 = 32
2000:16x5x5x(2x2+1)=2000
卷积层C5
层C5是具有120个特征图的卷积层(每个Feature map尺寸为1x1)。每个单元连接到所有16个S4特征图上的5x5邻域。这里,因为S4的大小也是5x5,所以C5的特征图的大小是1x1:这相当于S4和C5之间的完全连接(只是因为现在输入图像尺寸比较小,才会有这种现象)。C5被标记为卷积层,而不是完全连接层,因为如果LeNet-5输入更大,而其他一切保持不变,则特征图维度将大于1x1。C5层可训练的参数和连接都是48120。(注意,都是48120的原因只是因为输入图像尺寸较小)
数字解释:
48120:120x(16x5x5+1) = 48120
全连接层F6
层F6包含84个单元(这个数字的原因来自输出层的设计,下面会说到),是C5层的全连接。它有10164个可训练参数。
我们当然可以决定全连接层的神经元个数,只不过在LeNet-5中,是以数字识别数据为输入的。为了配合最后的输出层设计,才设置全连接层神经元个数为84个。
数字解释:
10164:84x(120+1) = 10164个
输出层
输出层包含10个神经元,分别代表数字0到9。如果节点i的值为0,则这张输入的照片经过LeNet-5识别的结果就是数字i。从F6层到输出层,采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:

式中 w_{ij}的值由 i 的比特图编码确定,i的取值是从0到9,j的取值是从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接(参数不需要训练)。
数字解释:
840:84x10 = 840个
这一步的卷积权重参数是不需要训练的(训练后期你也可以对它们进行学习),而是从上面提到的比特图中挑出就可以了。我们选代表数字0到9的比特图,与F6层进行全连接卷积后就可以衡量,F6层的输出究竟更贴近哪个数字。当然了,当你选择要识别其他字符时,就要选择其他的比特图了
文章中使用的比特图如下

这些图的尺寸都是7x12,其中每个像素点白色值为-1,黑色为1,每一个比特图就是上面公式使用的w_{ij}
总结
这篇文章分析了LeNet-5的网络结构。
我会介绍一些经典的深度学习网络,这一系列只是我的总结性笔记,因为毕竟深度学习不是我的核心技能。



评论(0)
您还未登录,请登录后发表或查看评论