

描述
DBSCAN是一种基于点云密度的无监督聚类方法
论文:A Density-Based Algorithm for Discovering Clusters in Large Spatial DataBase with Noise, 1996
它是一种聚类的基本算法,了解它的原理并实现是一件基础的工作。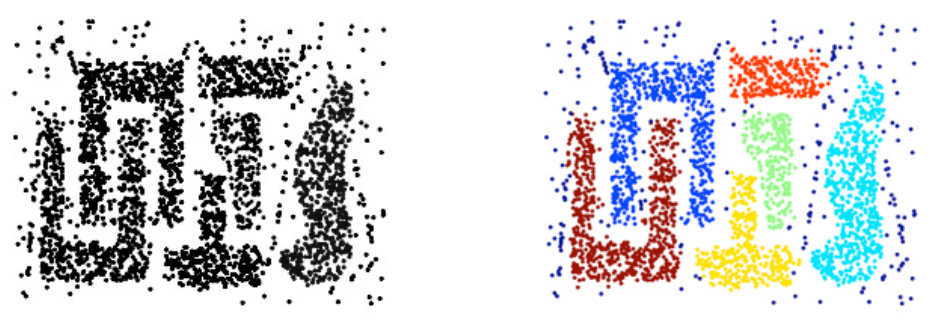
定义
如论文所述,主要解决三个问题:
- It can often be difficult to know which input parameters that should be used for a specific database, if the user does not have enough knowledge of the domain.(需要先验输入参数)
- spatial data sets can contain huge amounts of data, and trying to find cluster patterns in several dimensions is very computationally costly.(找到大量且多维数据的聚类模式难)
- the shapes of the clusters can be arbitrary and in bad cases very complex. Finding these shapes can be very cumbersome.(点云簇形状复杂时的聚类问题)
在实际算法前,作者给出了6个定义及2个引理
1. 点的ε邻域(The Eps-neighborhood of a point)
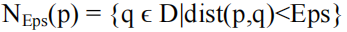

2. 密度直达 (Directly density-reachable)
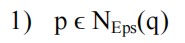
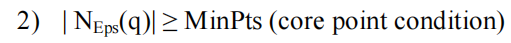
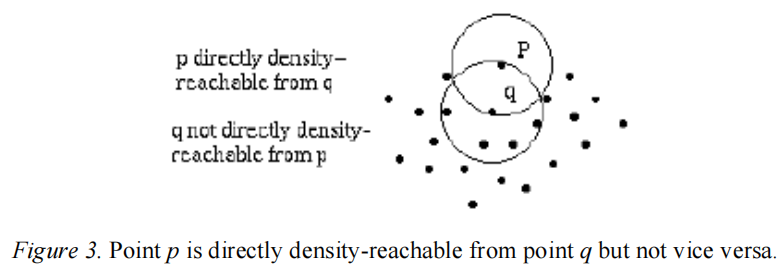
3. 密度可达 (Density-reachable)
A point p is density-reachable from a point q with respect to Eps and MinPts if there is a chain of points p1…,pn, p1=q, pn=p such that pi+1 is directly density-reachable from pi.
q可以到达p
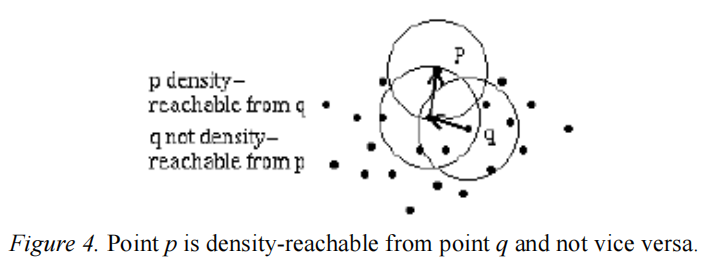
4. 密度相连 (Density-connected)
A point p is density-connected to a point q with respect to Eps and MinPts if there is a point o such that both, p and q are density-reachable from o with respect to Eps and MinPts.
q和p是相连的
5. 点云簇 (cluster)
6. 噪声 (noise)
Noise is the set of points, in the database, that don’t belong to any of the clusters.
2个引理:
- A cluster can be formed from any of its core points and will always have the same shape.
- Let p be a core point in cluster C with a given minimum distance (Eps) and a minimum number of points within that distance (MinPts). If the set O is density-reachable from p with respect to the same Eps and MinPts, then C is equal to the set O.
算法步骤
计算流程:
输入:样本集D=(x1,x2,…,xm),邻域参数(ϵ,MinPts), 样本距离度量方式
输出: 簇划分C={C1,C2,…,Ck}.
1)初始化核心点集Ω=∅, 初始化聚类簇数k=0,初始化未访问样本集合Γ = D, 簇划分C = ∅
2) 遍历样本集,从样本集中找出所有的核心点:
a) 通过距离度量方式,找到样本xj的ϵ-邻域
b) ϵ-邻域中的点个数满足|Nϵ(xj)|≥MinPts, 样本xj成为一个核心点
3)从核心点集中取出一个核心点p,找到从p出发所有密度可达的数据点,形成一个点云簇
4)不断执行步骤3,直到所有核心点集为空
分类效果
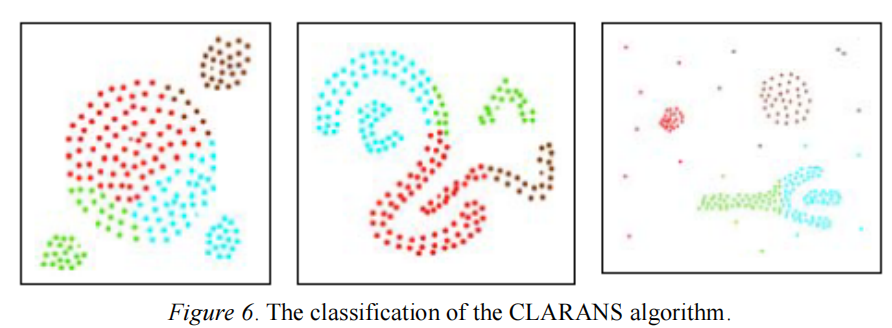

优点
- 可以发现任意形状的聚类簇
- 不需要输入类别数K
- 聚类同时找到噪声点
- 聚类结果稳定
缺点
- 样本集较大时,聚类收敛时间较长 —— 可以使用KD树来加速
- 密度不同,但距离相近时,很难区分
- 有两个输入参数:距离阈值及邻域样本数阈值
代码实现
二维DBSCAN
这个github里面是一个人写的二维DBSCAN算法,写的不错贴在这里
https://github.com/buresu/DBSCAN
三维DBSCAN
在二维DBSCAN代码的基础上,我进行了一点点修改及代码规范,贴在这里main.cpp
srand(time(0)); // 根据时间生成随机数
pcl::visualization::CloudViewer cloud_viewer("DBSCAN Cluster Result");
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud_total(new pcl::PointCloud<pcl::PointXYZ>);
// 省略点云文件加载步骤
std::vector<pcl::PointXYZ> points_dbscan;
for (int p = 0; p < cloud_total->points.size(); p++) {
points_dbscan.push_back(cloud_total->points[p]);
}
std::vector<int> labels_dbscan;
int num_dbscan = dbscan(points_dbscan, labels_dbscan, 1, 3);
std::cout<<"\033[32m"<<"dbscan clusters num: "<<num_dbscan<<"\033[0m"<<std::endl;
std::vector<int> r_;
std::vector<int> g_;
std::vector<int> b_;
for (int p = 0; p < num_dbscan; p++) {
int r = rand() % 255;
int g = rand() % 255;
int b = rand() % 255;
r_.push_back(r);
g_.push_back(g);
b_.push_back(b);
}
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud_colored(new pcl::PointCloud<pcl::PointXYZRGB>);
pcl::copyPointCloud(*cloud_total, *cloud_colored);
size_t max_i = cloud_colored->points.size();
for (size_t i = 0; i < max_i; i++) {
cloud_colored->points[i].r = (uint8_t)r_[labels_dbscan[i]];
cloud_colored->points[i].g = (uint8_t)g_[labels_dbscan[i]];
cloud_colored->points[i].b = (uint8_t)b_[labels_dbscan[i]];
}
cloud_viewer.showCloud(cloud_colored);
dbscan.h
#ifndef __DBSCAN_H__
#define __DBSCAN_H__
#include <vector>
#include <math.h>
#include <algorithm>
#include <pcl/point_cloud.h>
#include <pcl/point_types.h>
int dbscan(const std::vector<pcl::PointXYZ> &input, std::vector<int> &labels, double eps, int min);
#endif // __DBSCAN_H__
dbscan.cpp
#include "dbscan.h"
static const inline double distance(double x1, double y1, double z1, double x2, double y2, double z2) {
double dx = x2 - x1;
double dy = y2 - y1;
double dz = z2 - z1;
return sqrt(dx * dx + dy * dy + dz * dz);
}
const inline int region_query(const std::vector<pcl::PointXYZ> &input, int p, std::vector<int> &output, double eps) {
for(int i = 0; i < (int)input.size(); i++) {
if(distance(input[i].x, input[i].y, input[i].z, input[p].x, input[p].y, input[p].z) < eps){
output.push_back(i);
}
}
return output.size();
}
bool expand_cluster(const std::vector<pcl::PointXYZ> &input, int p, std::vector<int> &output, int cluster, double eps, int min) {
std::vector<int> seeds;
if(region_query(input, p, seeds, eps) < min) {
//this point is noise
output[p] = -1;
return false;
} else{
//set cluster id
for(int i = 0; i < (int)seeds.size(); i++) {
output[seeds[i]] = cluster;
}
//delete paint from seeds
seeds.erase(std::remove(seeds.begin(), seeds.end(), p), seeds.end());
//seed -> empty
while((int)seeds.size() > 0) {
int cp = seeds.front();
std::vector<int> result;
if(region_query(input, cp, result, eps) >= min) {
for(int i = 0; i < (int)result.size(); i++) {
int rp = result[i];
//this paint is noise or unmarked point
if(output[rp] < 1) {
//unmarked point
if(!output[rp]) {
seeds.push_back(rp);
}
//set cluster id
output[rp] = cluster;
}
}
}
//delete point from seeds
seeds.erase(std::remove(seeds.begin(), seeds.end(), cp), seeds.end());
}
}
return true;
}
int dbscan(const std::vector<pcl::PointXYZ> &input, std::vector<int> &labels, double eps, int min) {
int size = input.size();
int cluster = 1;
std::vector<int> state(size);
for(int i = 0; i < size; i++) {
if(!state[i]) {
if(expand_cluster(input, i, state, cluster, eps, min)) {
cluster++;
}
}
}
labels = state;
return cluster - 1;
}
代码效果
用我自己的数据的结果如下
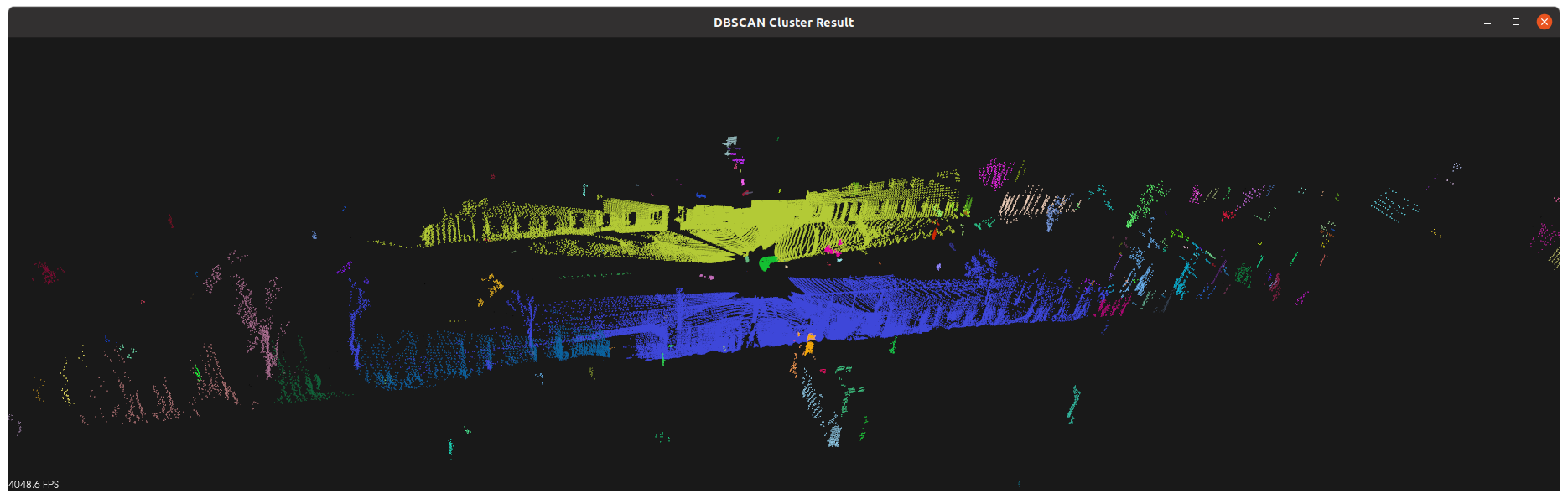
速度可以说是相当慢了。。。再优化吧



评论(0)
您还未登录,请登录后发表或查看评论