

这篇研究现状报告对抓取检测阐述的比较详细,我这里就只写这篇报告关于机器学习方面的抓取检测。
摘要
作为机器人在工厂、家居等环境中最常用的基础动作,机器人自主抓取有着广泛的应用前景,近十年来研究人员对其给予了较高的关注,然而,在非结构环境下任意物体任意姿态的准确抓取仍然是一项具有挑战性和复杂性的研究. 机器人抓取涉及3个主要方面:检测、规划和控制. 作为第1步,检测物体并生成抓取位姿是成功抓取的前提,有助于后续抓取路径的规划和整个抓取动作的实现. 鉴于此,以检测为主进行文献综述,从分析法和经验法两大方面介绍抓取检测技术,从是否具有抓取物体先验知识的角度出发,将经验法分成已知物体和未知物体的抓取,并详细描述未知物体抓取中每种分类所包含的典型抓取检测方法及其相关特点. 最后展望机器人抓取检测技术的发展方向,为相关研究提供一定的参考.
关键词: 机器人;抓取检测;经验法;未知物体;深度学习
Abstract: As the most common and basic robotic movement in environment such as factory and household, the autonomous grasping has various application prospect. Although researchers have paid higher attention to the robot autonomous grasping in recent decades, grasping arbitrary objects accurately with arbitrary poses in non-structural environment is still a challenging and complex study. The robot grasping involves three main aspects: sensing, planning and controlling. The first step is detecting the targeted object and generating the grasping pose. It is the precondition of the successful grasp that helps achieve the grasp path planning and the entire grasp movement. The literature review in this study is mainly based on sensing. Firstly, the grasping technology is introduced from two aspects: analytical method and empirical method, and the empirical method is divided into the grasping of known objects and unknown objects from the perspective of whether there is prior knowledge of grasping objects. Moreover, the typical grasping methods and their related features contained in each category of unknown object grasping is detailly described. Finally, the development direction of robotic grasp detection technology is prospected with the aim of providing references for the relevant researchers.
Keywords: robot;grasp detection;empirical method;unknown object;deep learning
3.2 基于学习的方法
机器学习方法已被证明对广泛的感知问题有效[32-36], 允许感知系统学习从一些特征集到各种视觉特性的映射[37]. 研究人员更是将深度学习引入抓取检测中,将学习方法应用于视觉中,引入学习方法对抓取质量进行评分[38]. 近期的文献采用了更丰富的特征和学习方法,允许机器人抓取部分被遮挡的已知物体[39] 或已知物体未知姿态[40] 以及系统之前未见过的全新物体(未知物体)[41],本文将讨论后一种情况. 早期的工作集中在仅从2D部分视图数据中检测单个抓取点,使用启发式方法基于此点确定机械手姿态[41]. 由于只有二维信息,第三维度的距离必须是固定的,抓取具有局限性,而3D数据的使用显著改善了这些结果[42]. 随着诸如Kinect等低成本RGB-D传感器的出现,深度数据在机器人抓取中的使用变得更加普遍.
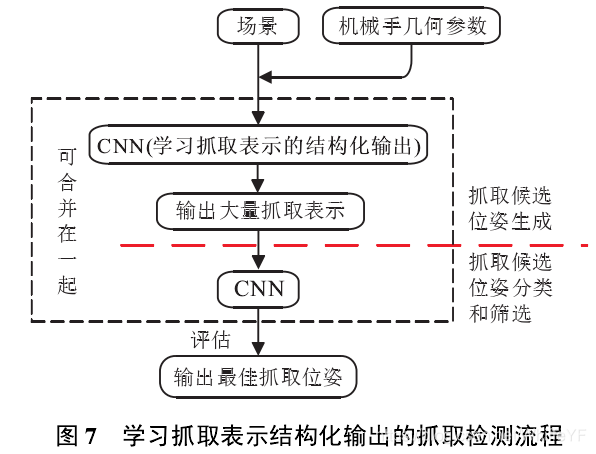
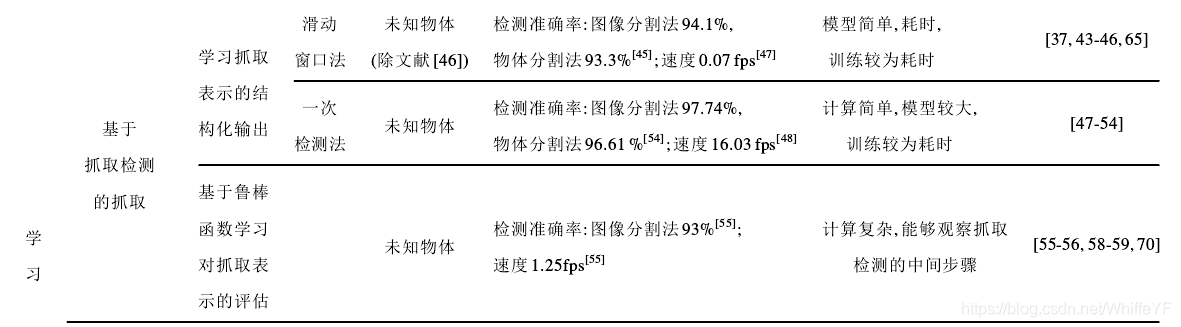
使用学习的方法检测抓取可分为两大类,如图6所示:一是基于抓取检测的抓取方法(需要一个单独抓取规划控制系统),通过抓取检测方法生成抓取位姿,再使用单独的规划控制系统基于轨迹规划生成轨迹,实现完整的抓取;二是基于视觉运动控制策略的端到端抓取方法, 实现从图像直接到抓取动作的映射. 其中,第1类按照学习内容的不同又包含两种方法,一种是学习抓取表示的结构化输出,例如抓取框等; 另一种是学习抓取鲁棒性评估[2]. 表 1 列出了基于学习的抓取检测方法的分类以及相关文献的检测准确率、速度等结果,并展示了文献所采用的数据集和算法,下文将紧紧围绕表1进行详细说明.

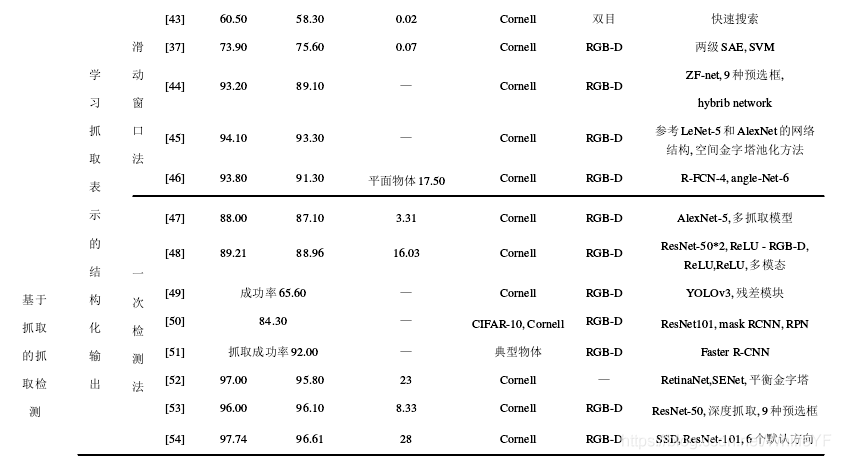


[43] Jiang Y, Moseson S, Saxena A. Efficient grasping from RGBD images: Learning using a new rectangle representation[C]. IEEE International Conference on Robotics and Automation. Shanghai: IEEE, 2011: 9-13.
[37] Lenz I, Lee H, Saxena A. Deep learning for detecting robotic grasps[J]. International Journal of Robotics Research, 2015, 34(4/5): 705-724.
[44] Guo D, Sun F, Liu H, et al. A hybrid deep architecture for robotic grasp detection[C]. IEEE International Conference on Robotics and Automation (ICRA). Singapore: IEEE, 2017: 1609-1614.
[45] 喻群超, 尚伟伟, 张驰. 基于三级卷积神经网络的物体抓取检测[J]. 机器人, 2018, 40(5): 762-768.(Yu Q C, Shang W W, Zhang C. Object grab detecting based on three-level convolution neural network[J].Robot, 2018, 40(5): 762-768.)
[46] 夏晶, 钱堃, 马旭东, 等. 基于级联卷积神经网络的机器人平面抓取位姿快速检测[J]. 机器人, 2018, 40(6):794-802.(Xia J, Qian K, Ma X D, et al. Fast detection of robot plane grab position based on concatenated convolution neural network[J]. Robot, 2018, 40(6): 794-802.)
[47] Redmon J, Angelova A. Real-time grasp detection using convolutional neural networks[DB/OL]. 2014, arXiv: 1412.3128.
[48] Kumra S, Kanan C. Robotic grasp detection using deep convolutional neural networks[DB/OL]. 2016, arXiv: 1611.08036.
[49] 张凯宇. 基于 RGB-D 图像的机械臂抓取位姿检测 [D]. 杭州: 浙江大学机械工程学院, 2019: 1-89. (Zhang K Y. Robotic grasp posture detection based on RGB-D image[D]. Hangzhou: School of Mechanical Engineering, Zhejiang University, 2019: 1-89.)
[50] 唐博恒. 基于改进 Mask RCNN 的不规则 3D 物体抓 取点识别[D]. 石家庄: 河北科技大学电气工程学院, 2019: 1-85.(Tang B H. Grasping point recognition of irregular 3D objects based on improved mask RCNN[D].Shijiazhuang: School of Electrical Engineering, Hebei University of Science and Technology, 2019: 1-85.)
[51] 张亚辉. 基于 Faster R-CNN 目标检测的机器人抓取系统研究[D]. 深圳: 中国科学院大学深圳先进技术研究院, 2019: 1-65.(Zhang Y H. Research on robot grasping system based on faster R-CNN target detection[D]. Shenzhen: Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences University, 2019: 1-65.)
[52] 卢智亮, 林伟, 曾碧, 等. 机器人目标抓取区域实时检测方法 [J]. 计算机工程与应用, 2019(9/10/11/12):1-10.(Lu Z L, Lin W, Zeng B, et al. Real-time detection method for robot target grabbing area[J]. Computer Engineering and Applications, 2019(9/10/11/12): 1-10.)
[53] Chu F J, Ruinian X, Patricio V. Real-world multi-object, multi-grasp detection[J]. IEEE Robotics and Automation Letters, 2018, 1802: 1.
[54] Zhou X W, Lan X, Zhang H, et al. Fully convolutional grasp detection network with oriented anchor box[DB/OL]. 2018, arXiv: 1803.02209.
[55] Mahler J, Liang J, Niyaz S, et al. Dex-Net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics[C]. Robotics Science and Systems (RSS). Cambridge: MIT, 2017: 58.
[56] Ten Pas A, Gualtieri M, Saenko K, et al. Grasp pose detection in point clouds[J]. The International Journal of Robotics Research, 2017, 36(13/14): 1455-1473.
[57] Park D, Chun S Y. Classification based grasp detection using spatial transformer network[DB/OL]. 2018, arXiv: 1803.01356.
[58] Lu Q, Chenna K, Sundaralingam B, et al. Planning multi-fingered grasps as probabilistic inference in a learned deep network[DB/OL]. 2017, arXiv: 1804.03289.
[59] 王斌. 基于深度图像和深度学习的机器人抓取检测算法研究[D]. 杭州: 浙江大学机械工程学院, 2019:1-85.(Wang B. Research on robot grab detection algorithm based on depth image and deep learning[D]. Hangzhou:School of Mechanical Engineering, Zhejiang University,2019: 1-85.)
[60] Zhang F, Leitner J, Milford M, et al. Towards vision-based deep reinforcement learning for robotic motion control[C]. Proceedings of the Australasian Conference on Robotics and Automation. Canberra: IEEE, 2015: 2-4.
[61] Mahler J, Goldberg K Y. Learning deep policies for robot bin picking by simulating robust grasping sequences[C]. Proceedings of the 1st Annual Conference on Robot Learning. California: Mountain View, 2017: 515-524.
[62] Mahler J, Matl M, Liu X, et al. Dex-Net 3.0: Computing robust robot vacuum suction grasp targets in point clouds using a new analytic model and deep learning[DB/OL]. 2018, arXiv: 1709.06670.
[63] Zeng A, Song S, Yu K, et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domainImage matching[C]. Proceedings of the IEEE International Conference on Robots and Automation (ICRA). QLD: Brisbane, 2018: 21-26.
3.2.1 学习抓取表示的结构化输出
最常用方法是滑动窗口法, 如图 7 所示. 该方法将点取场景信息与机械手几何参数输入到卷积神经网络(convolutional neural networks, CNN)中,使用分类器确定图像每个小部分是否构成良好抓取,得分高的部分被认为是很好的候选抓取[47].
Saxena 等[41] 通过监督学习进行训练, 使用合成图像作为训练集, 可在 1.2 s 内识别单个抓取点, 但没有使用深度图像, 获得 87.5 % 的抓取成功率. Rao等[64] 采用监督定位方法选择抓取点,估计形状后找到一对抓取点,同样获得了87.5 %的抓取成功率. 随后, Jiang等[43] 提出了七维抓取框的抓取表示,取代了原来的抓取点表示方法,明确地模拟了夹具的物理尺寸(即宽度),仅使用单个抓取点或一对抓取点无法表示该尺寸,而抓取矩形表示方法却能严格限制夹具的抓取边界. 此外,抓取点表示方法具有任意的支撑区域(如围绕这些点的一定半径的区域),该支撑区域与抓取手指将占据的物理空间可能出现不匹配的情况。
Jiang 等[43] 提出了一种多模态深度学习结构, 首先进行无监督分层学习,用于RGB和深度模态的特征提取;然后通过组合RGB和深度特征开发共享层;最后将无监督分层学习用作监督特征分类器以进行最终决策. Lenz等[37] 在七维抓取框的基础上提出了五维抓取框,以此为抓取表示,基于二维图像提出了一个具有两级深度网络的级联系统. 如图8所示,首先通过一个较浅的卷积神经网络找到所有可能的抓取矩形,保留一些评分较高的抓取矩形;然后通过一个深的卷积神经网络在保留的抓取矩形中找到评分最高的,即最佳抓取矩形框,得到最佳抓取矩形框后,将矩形框中心的点云法线方向作为机械手的接近向量,检测准确率达到75%,每个图像的处理时间为13.5 s[2]. 该检测算法处理时间较慢, 也仅依赖于局部特征确定抓取位置. 由于采用类似于穷举法的搜索机制,需要在不同大小的图像块上使用分类器进行重复计算,计算量非常大,且十分耗时。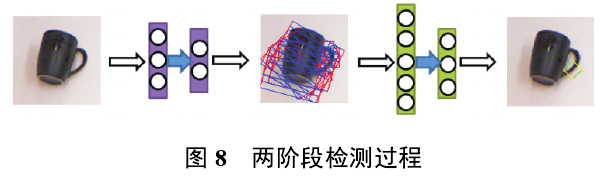
Guo 等[44] 提出了一种视觉和触觉传感混合的深层结构, 使用参考矩形方法识别图像的可抓取区域, 该方法改编自区域候选网络 (region proposal network, RPN)[65], 实质是基于滑窗的无类别物体检测器,检测准确率达到89.1 %. 喻群超等[45] 提出了一种3级串联卷积神经网络,第1级用来定位物体,为下一级卷积神经网络进行搜索抓取框做准备,第2级使用较浅的网络进行抓取框的搜索,去除掉不能实现的抓取框,第3级用一个深的卷积神经网络精确搜索抓取框,检测准确率达到 93.3 %, 但是当物体背景颜色变化较大时,该方法不能很好地使用,鲁棒性不好. 夏晶等[46] 为了快速检测平面物体的抓取姿态,提出了一种级联卷积神经网络,第1级基于R-FCN定位抓取框并进行了抓取框角度的粗估计,第2级使用angle-Net 进行抓取框角度的精细估计, 使得机器人抓取平均成功率达到 92.5 %. 使用滑动窗口方法识别参考矩形位置的方法,以遍历搜索获得最优解,时间代价大. 亟需解决的问题是减少抓取定位时间消耗和提升姿态估计精度.
鉴于滑动窗口法存在时间长的问题,一次检测法应运而生. 该方法在图像上应用CNN直接预测抓取坐标,不用遍历搜索,该网络层数较多,但因为只对图像应用一次, 实时性能有所提升. Redmon 等[47] 利用大型卷积网络强大的学习能力,对物体的完整图像进行全局抓取预测. 该网络在不使用标准滑动窗口或区域候选网络的情况下对可抓取的边界框直接执行单阶段回归,达到88%的准确性,在GPU上以每秒13帧的速度运行. 该网络可以同时执行分类,以便在一个步骤中识别对象并找到一个良好的抓取矩形,对该模型的修改通过使用局部约束的预测机制来预测每个对象的多个抓取位姿. 对于有多种方式抓取的对象,局部约束模型表现得更好. 每张图像的检测准确率为84.4 %,处理速度为76 ms. 因为该数据集没有对图像中的多个抓取进行适当的评估,所以局部预测模型不能对预测的每个图像的多个抓取能力进行定量评估. 该方法使用类似于AlexNet的卷积神经网络模型实现单阶段检测,以更快的速度达到更高的检测精度,但由于卷积神经网络结构的复杂性仍然存在模型较大的缺陷. Kumra等[48] 使用深度卷积神经网络从图片中提取特征,并使用浅卷积神经网络预测感兴趣物体的抓取位姿,该多模态模型在标准Cornell Grasp数据集上的检测准确率达到89.21 %,每个图像的处理速度达到 100 ms, 仅在 RGB 图像上训练并且不具有深度特定特征,其采用网络结构更复杂、特征提取能力更强的ResNet50提取抓取特征,用SVM预测抓取配置的参数,虽然可以达到比较好的检测精度,但是由于模型采用层数较深的残差网络,导致网络模型和计算量都比较大. 可以看出,一次性检测中的大部分工作都采用深度迁移学习技术来使用预先训练的神经网络架构[66-67].
我国一些研究人员也采用该种方法进行研究.张凯宇[49]提出了基于卷积神经网络的栅格化抓取位置检测方法,使用YOLOv3算法以及残差模块,抓取成功率为65.6 %,但当前模型对物体点云信息利用得不够充分,使用的训练数据量也较小,模型的准确性还有较大提升空间. 唐博恒[50] 提出了一个两级抓取网络,第1级基于Mask R-CNN进行目标分类和生成掩膜图,第2级网络使用深度、灰度、掩膜图进行抓取预测. 该网络最终得到84.3 %的泛化性实验准确率,但在小目标物体抓取检测方面准确率不高. 张亚辉[51] 基于Faster R-CNN提出一种多物体分类及摆放算法,旨在解决工业生产问题,该抓取系统的总成功率为92 %左右,但没有考虑到物体的姿态、避障等功能. 卢智亮等[52] 提出一种基于嵌入通道注意力结构SENet的一阶抓取检测网络(squeeze and excitation networks-RetinaNet used for grasp, SE-etinaGrasp) 模型的机器人抓取区域实时检测方法,该方法采用快速的一阶目标检测模型RetinaNet作为基本结构,在其特征提取网络中嵌入通道注意力模块SENet以提升重要特征通道的权重,确保检测精度,而且结合平衡特征金字塔(balance feature pyramid)思想,充分融合高低层的特征信息,加强检测小抓取框的能力,每张图片与每个物体的检测准确率为97.0 %与95.8 %,时间为23 ms,但未考虑多物体堆叠的情况.
尽管一次检测的首选方法是抓取表示的直接回归,但是在很多情况下,分类和回归技术被用于一次检测中,将方向预测视为分类问题[2]. 一部分研究人员在一次检测法的基础上,细致地研究了抓取框的方向. Chu等[53] 将回归问题转换为区域检测和方向分类问题(零假设竞争)的组合,使用具有红色、绿色、蓝色和深度(RGB-D)图像输入的深度神经网络预测单个对象或多个对象的多个抓取候选者,在单个对象处理时,该方法优于Cornell数据集的最先进方法,分别在图像和对象分割上具有96.0 %和96.1 %的检测准确率. 对多对象数据集的评估表明了该体系结构的泛化能力. 抓取实验在一组家用物体上实现了96.0 %的抓取定位和89.0 %的抓取成功率. 从图像中的抓取检测到抓取动作规划,实时过程花费不到0.25 s,该方法在多对象多抓取时存在改进空间,可以结合先验知识提高检测准确率. 该模型适用于多物体的抓取场景,并且达到了较高的抓取检测准确率,因为模型较深且类似于级联系统会导致模型较大. Zhou 等[54,68] 在 Guo 等[44] 的基础上, 提出了一种定向锚箱机构模型,并在训练过程中采用端到端的完全卷积神经网络. 网络由两部分组成: 特征提取器和多抓取预测器. 特征提取器是深度卷积神经网络. 多抓取预测器从预定义的定向矩形(称为定向锚框)中回归抓取矩形,并将矩形分类为可抓取和不可抓取. 在标准的Cornell Grasp数据集中,该模型分别在图像分割和逐个对象分割上实现了97.74 %和96.61 % 的检测准确率, 该方法没有在杂乱环境下进行. 可见,一次检测方法在速度以及检测准确率方面具有更好的性能,但是网络结构较为复杂.
3.2.2 学习抓取鲁棒性评估
学习抓取鲁棒性评估也是许多深度抓取检测研究的核心思想. 研究人员使用此功能来识别具有最高评分的抓取位姿作为输出,该方法主要评估抓取而不学习控制器如何抓住物体. 抓取鲁棒性描述了某个位置或图像区域的抓取概率[55],对于这种方法,二元分类是一种很好的研究方法,它将候选抓取位姿分类为有效或无效(1或0). 方法流程见图9,采用几何等方法生成候选抓取,再通过卷积神经网络基于鲁棒函数进行学习评估,输出最佳抓取.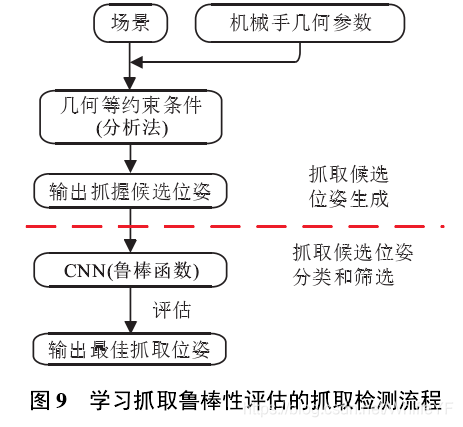
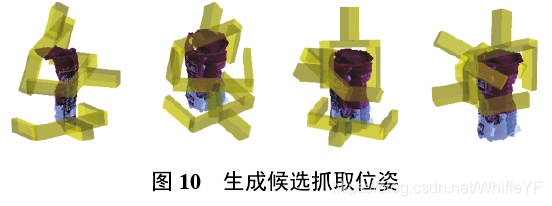
Mahler 等[55] 提出了一种学习最佳抓取鲁棒性函数的方法,对抓取点表示方法进行了更深一步的研究,将鲁棒性视为[0, 1]范围内的标量概率,并创造了Dex-Net 2.0 数据集, 其中包括 670 万点云和分析抓取质量指标,针对2指平行夹爪,使用对1 500个3D对象网格模型的数据集进行稳健的准静态平行夹爪空间分析,以每个3D模型表面法向量为接近向量随机生成大量抓取位姿,然后将生成的抓取位姿与点云对应存储,投入抓取质量网络(grasp quality convolution neural network, GQ-CNN) 进行训练. 利用 Dex-Net 2.0数据集测试了CNN,抓取的检测准确率达到93 %,但需要进行大量计算工作. Ten等[56]对提取到的点云信息进行处理优化,基于几何信息计算曲率、法线等,生成大量六自由度抓取候选位姿(图10显示了基于该算法生成候选抓取位姿的3个示例),继而基于深度学习法对大量六自由度抓取候选位姿进行分类,根据机器人可以轻松达到的程度选择最佳抓取位姿,以识别密集物体杂乱中的可抓取区域. 该方法针对物体点云数据能达到77 %的检测准确率,主动点云可以达到93 %抓取成功率,此种方法在标记时必须记录至少两个点云.
Park 等[57] 使用基于原始空间变换网络 (spatial transformer networks, STN)[69]和深度残余网络(deep residual learning for image recognition, ResNet)[70]的多级空间变换网络预测抓取候选,与其他基于回归的抓取检测方法不同,该方法允许部分观察中间结果,如抓取位置和方向. 每张图像的抓取检测准确率为89.60 %,处理速度为23 ms. Lu等[58] 使用了反向传播算法在神经网络内部使用梯度上升优化有效地进行抓取概率研究,以使新物体的检测准确率达到75.6 %. 抓取检测算法使用解析的方法生成候选抓取姿态, 需要大量计算工作. 王斌[59] 在 Mahler 等[55]的基础上,设计了一种基于深度图像和深度学习的归一化算法,以更好地适应各种夹具宽度和物体的距离,并基于GQ-CNN和改进的Dex-Net 2.0结构,设计了改进的GQ-CNN,在仿真环境下单阶段抓取检测算法的抓取检测准确率达到88.9 %,平均计算用时为4 ms, 但在实际抓取中存在大量噪声, 抓取效果不好,而且没有考虑到多物体、杂乱环境有遮挡、非水平背景下的抓取检测情况,有待进一步改进.此类方法能够观察抓取检测的中间步骤,但计算复杂.
3.2.3 基于视觉运动控制策略的端到端抓取
近年来,人们探索了新的方法,可以不使用单独的抓取规划控制系统,而使用深度学习训练视觉运动控制器. 该学习器迭代地校正抓取点,直到在抓爪之间成功抓取物体为止.
Zhang 等[60] 提出了一种使用强化学习[59] 确定将机器人末端执行器扩展到 2D 图像平面中某个点的动作的方法. 以Mnih等[71] 提出的深度Q网络(DQN)为基础,使用合成图像使其适应机器人系统,在测试中系统达到目标点的成功率为51 %. 这些结果在很大程度上不能从合成场景应用到现实场景, 领域适应性较差. 此项目使用单目相机进行视觉传感,作者指出使用立体摄像机或RGBD传感器应该会获得更好的结果. Mahler等[61] 提出了一种可以在杂乱环境下利用在合成数据上训练CNN挑选物体的方法. 使用离散时间部分可观察的马尔可夫决策过程进行建模,通过将迁移学习技术与之前的方法[55] 结合使用,实现了 92.4 % 的检测准确率, 以及 70 % 的抓取成功率. 来自Dex-Net 2.1的GQ-CNN高平均精度得分表明,当模型不具有较高的置信度时,可以通过引入替代动作 (如探测或使用吸盘) 提高性能. Mahler 等[62]提出了一种吸力接触模型, 该模型可以计算吸盘与局部目标表面之间的密封质量,并衡量吸力抓取抵抗外部重力扳手的能力. 在 Dex-Net 3.0 上训练的 GQ-CNN 在约 552 000 个数据点的验证集上具有 93.5 %的检测准确率,对分类为“基本”(棱柱形或圆柱形)、“典型”(更复杂的几何)和“对抗性”(具有很少的吸点) 的未知对象进行评估时, 抓取成功率分别达到98 %、82 % 和 58 %. 该方法将夹爪换成吸盘, 方法新颖,抓取成功率在“基本”“典型”物体中具有较高的检测准确率,但是对于“对抗性”物体的抓取成功率有待改进.
Zeng 等[63] 提出了一种能够在杂乱的环境中识别抓取物体的视觉控制方法. 首先使用一个与类别无关的抓取框架来完成从视觉观察到动作的映射;推断出4个不同的抓取原始动作负担的密集像素级概率图;然后以最高的承受能力执行操作,并使用跨域图像分类框架识别拾取的对象, 该框架将观察到的图像与产品图像进行匹配. 由于产品图像可轻松用于各种对象(如从网上获取),该系统无需任何其他数据收集或重新训练. 检测准确率为88.6 %,时间为0.06 fps, 抓取和吸取精度均大于 90 %, 其中抓取略好于吸取,此方法限于无障碍抓取或者吸取. 加强学习以对原始动作进行排序的策略是本方法值得探索的替代方法. 此类方法不需单独的抓取系统,可以进行分类,但速度较慢.
4 机器人抓取检测技术总结
当前机器人抓取检测技术可按图 11 进行分类,主要分为分析法和经验法. 其中,分析法在2005年之前应用较为广泛,使用分析法仍然可以准确地从图像中检测物体的抓取配置问题,但是由于面向任务存在复杂性高以及依赖已知参数的缺点, 后来逐步被经验法所取代. 经验法可应用于针对已知、未知物体的抓取检测,其中针对已知物体的抓取检测方法必须具有完整的三维模型,导致在实际应用中具有较大局限. 因此,针对未知物体的抓取检测方法成为当前的研究热点.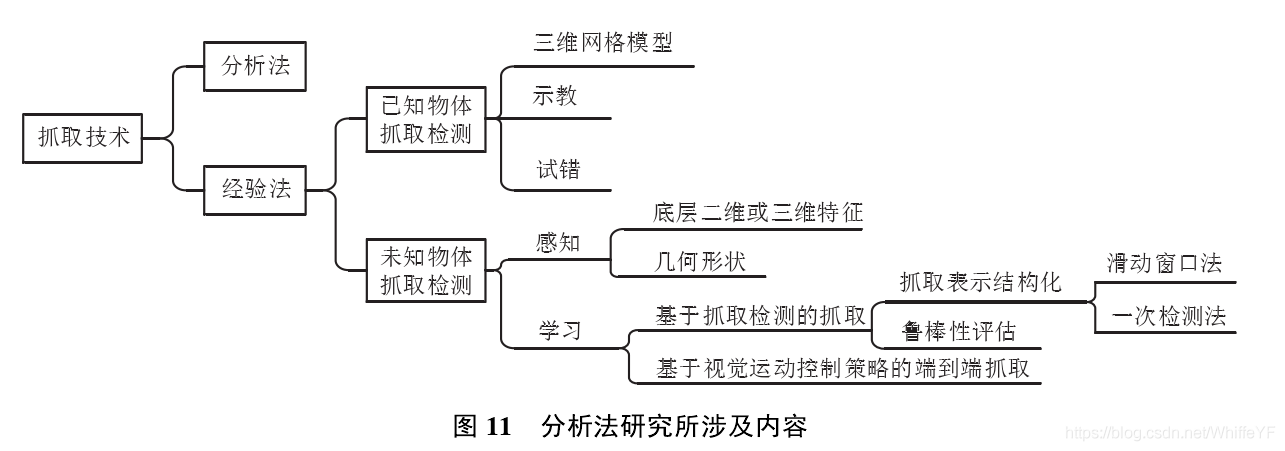


未知物体抓取检测技术的分类及其特点如表2所示. 可见,未知物体的抓取检测分为基于感知的抓取检测和基于学习的抓取检测. 基于感知的抓取检测没有结合现有的流行技术,只针对特定形状物体,且计算量较大,检测准确率稍低,耗时较长,实际应用具有局限性. 基于学习的抓取检测方法目前研究较多,不限于被抓物体形状,其中基于抓取检测的抓取需要独立配置规划控制系统,根据学习内容的不同,又可将其分为学习抓取表示的结构化输出和学习抓取鲁棒性评估两种方法. 学习抓取表示的结构化输出方法不允许观察中间步骤, 其中的滑动窗口法多采用以 LeNet-5 和 AlexNet 为基础的网络模型, 结构简单,检测准确率较好,能泛化性抓取,主要局限性在于以遍历搜索获得最优解,不适合实时操作,亟需解决的问题是减少抓取定位时间消耗, 以及提升姿态估计精度;一次检测法能够实时进行检测,但是采用的网络多以ResNet为基础,检测准确率有所提高,耗时较短,但网络结构较为复杂,需大型数据集进行训练且较为耗时,亟需解决的问题是精简网络结构. 学习抓取鲁棒性评估的方法能够观察抓取检测的中间步骤,检测准确率较好,但计算复杂,大多没有给出检测时间,部分文献给出的时间也较长,理论上源于计算的复杂性,未来的研究方向可聚焦于提升检测速度方面. 一次检测法虽然训练时间较长,但是好在使用过程中速度快,而学习抓取鲁棒性评估的方法与其相反,但是大多情况下,期望能够在检测过程中提升速度. 与基于抓取检测的抓取不同的是基于视觉运动控制策略的端到端抓取,该方法不需独立配置规划控制系统,可以实现从图像直接到抓取动作的映射,能够用于分类但速度较慢,未来可提升速度并探索其在实际中的应用.
由前文可知, 视觉传感方面使用 RGB-D 相机较多, 相比于双目和单目相机, 较为廉价, 使用较为方便, 且检测准确度较高. 建议研究学者们使用 RGB-D 相机, 当然如果需要在室外进行抓取, 双目相机也不失为一个好的选择. 同样可以看出,抓取点表示方法[41,55,64]使用较少,抓取框的表示方法能进一步限制夹具的抓取情况,使用更为普遍.
总体而言,基于深度学习的抓取检测技术方兴未艾,正在逐步代替传统的人工设计、提取图像特征的方式. 目前常用的抓取检测方法主要有如下两种:
1) 基于一次检测法的抓取方法. 由前文可见, 研究人员大多采用一次检测进行抓取检测,在图像上应用CNN直接预测抓取坐标. 相比于滑动窗口法,一次性检测法引入了更深的网络. 深度增加时,可表达更为复杂的模型,能从图像中学习更多特征,因此对物体的检测准确率显著上升. 但是也存在一些弊端:一是训练数据需求量大,较大的数据集将导致要提取的特征增加,而有限的数据集将导致过度拟合,同时也需要训练数据之间具有较大差异,即使是人工标注也存在较大难度; 二是可训练参数的数量将随着深度的增加而增加,需要大量的计算和存储资源,对硬件的要求大幅提高. 图像检测准确率的提高依赖于更新的算法、改进的网络体系结构、强大的硬件支持、更大的训练数据集以及更大的学习模型,因此仍然具有挑战性. 未来可以尝试着设计特定于应用的深层卷积神经网络,使用轻量化模型,或者使用稀疏连接的深层网络以使识别速度更快,再在其中加入残差模块等以保持较高的检测准确率,使用网络预训练避免出现过拟合,此外,为了便于与国内外研究成果进行比较, Cornell数据集不失为一个好的选择. 相信随着科技的发展,硬件设备更好,训练可无需依赖NVIDIA显卡,不只使用CUDA进行加速,亦可尝试使用其他框架进行训练,更加便于移植.
2) 基于视觉运动控制策略的端到端抓取方法.通过使用深度学习训练视觉运动控制器, 可以避免独立配置规划控制系统, 实现从图像直接到抓取动作的映射. 近期已有研究人员开始探索将强化学习应用在该方法中,强化学习是一种基于奖励的方法,不需要预先标记数据集,但涉及到更长的训练过程,类似于反复试验过程,获得必要数量的有效数据实例所需时间较长,需要进一步的工作来确定更省时的方法. 迄今为止,研究人员较为回避此方法在实际产业中的应用,以减轻对机器人设备的潜在损害以及需要较长训练时间的问题. 然而,随着领域自适应技术的发展,可以在仿真环境下训练强化学习算法,再在实际产业中应用,避免对机器人的潜在损害,此类方法值得进一步探索. 譬如在工厂中,可按照实际的需要以及特定物体的特点,选用吸取或者抓取的方式分拣物体,此时,针对杂乱环境中物体的分层抓取以及语义理解,将成为研究的重点与难点.
5 结 语
随着机器人在工厂、家居等环境的快速普及,机器人抓取技术已经成为最近几年的研究热点,近年来我国有很多的研究人员和机构聚焦于抓取检测领域,但整体而言我国抓取检测技术成果与国外相比仍有较大差距. 然而,当前的国内外研究都存在一些共性问题:
1)高检测准确率下检测抓取框时间过长,不满足机器人抓取检测的实时性要求;
2) 容易忽略目标物中可用于抓取的小部位信息,检测出来的抓取框偏大、精确度不足;
3)技术载体多为实验室样机,很多是在仿真环境下执行抓取,未能投入到生产生活中进行实际使用;
4)只有部分文献考虑到多物体、杂乱环境情况下的抓取,建议研究人员们可以从单一物体无遮挡情况下的检测逐渐转变为多物体杂乱环境下的抓取检测,同时也应关注小目标的检测以及抓取.
无论采用哪种方法,本文能够提供一定的参考价值,使得机器人抓取检测准确率更高,速度更快,进而提升抓取成功率,以增强机器人在复杂多变环境下的作业能力,满足实际生活、生产中的各种抓取任务需求,提高生活质量与生产效率.
")


评论(0)
您还未登录,请登录后发表或查看评论