

前言
相关与回归分析是分析变量之间关系的统计方法,本章只介绍简单的相关分析和一元线性回归。
变量间关系的度量
变量之间存在的不确定的数量关系,称为相关关系
即当给定一个自变量 x ,其对应的因变量 y 值可能有好几个,这种关系不确定的变量显然不能用函数关系来描述,但也不是没有规律可循,相关分析就是分析这类数据的方法。
相关系数
相关系数是反映两个数值变量之间关系的指标。
对于数值变量 x 和 y ,我们可以通过散点图来判断两个变量之间是否有相关关系,并对这种关系进行大致的描述,但是没法给出定量的描述,因此需要计算相关系数。
相关系数也分为总体相关系数和样本相关系数,下面给出样本相关系数的计算公式: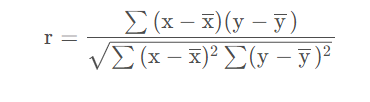
其中 x 表示 x 的均值,使用该公式计算出的相关系数也称Pearson相关系数。
Pearson相关系数的注意事项:
- r 的取值范围为-1~1,如果 r 大于0,说明 x 和 y 之间存在正相关关系,如果 r小于0, x 和 y之间存在负相关关系;当 r 等于0,说明 x 和 y 之间没有线性相关关系,也即 y的取值与 x无关;
- r 具有对称性。即 x 和 y 之间的相关系数 r x y r和 y 与 x 之间的相关系数 r y x相等,即 r x y = r y x ;
- r 的值大小与 x 与 x 的尺度无关,改变 x和 y的数据及其计量尺度,并不影响 r 的值;
- r 只能用来描述线性关系,不能描述非线性关系,所以在计算相关系数前,我们可以先绘制散点图来观测数据分布,如果数据的分布不是明显的线性关系,那么也就没有计算相关系数的必要了;
- r 的值只是一个参考,并不能说明 x 和 y 之间存在因果关系;
| 相关系数 | 相关程度 |
|---|---|
| | r | = = = 1 | 完全线性关系 |
| 0.8 ≤ | r | ≤≤ 1 | 高度相关关系 |
| 0.5≤ | r | ≤ 0.8 | 中度相关关系 |
| 0.3 ≤ | r | ≤ 0.5 | 低度相关关系 |
| | r | ≤ 0.3 | 极弱相关关系 |
| | r | = = = 0 | 不存在线性关系 |
相关关系的显著性检验
一般情况下,总体的相关系数 p 是未知的,我们只能通过样本数据计算 r,通常都是用 r来近似表示 p ,至于能否使用样本相关系数来代替总体相关系数,就需要我们对样本相关系数的可靠性进行假设检验。 r的相关性检验又叫做 t分布检验,可以用于大样本,也可以用于小样本。具体检验步骤如下:

值得注意的是为什么自由度为n-2,这是因为相关系数的变量是 x 和 y 两个,所以自由度为2个。
自由度: 自由度指的是计算某一统计量时,取值不受限制的变量个数。 通常 d f = n − k 。 其中n为样本含量,k为被限制的条件数或变量个数,或计算某一统计量时用到其它独立统计量的个数。
一元线性回归
回归分析非常重要!
很早之前就接触过回归分析,那个时候还只是知道给定两组数据,使用Matlab的回归函数直接计算系数,然后进行预测。从来不知道回归分析的详细推导,其实别看回归分析非常简单,后面包含的知识体系非常大。
回归分析包含线性回归和非线性回归,线性回归中有包含一元线性和多元线性,我们这里只研究一元线性回归。
描述因变量 y如何依赖于自变量 x和误差项 ε的方程,称为回归模型。对于只涉及一个自变量的一元线性回归模型如下:
y = β 0 + β 1 x + ε
y 的值是由自变量 x 和误差项所决定,误差项 ε是一个期望值为0的随机变量,即 E ( ε ) = 0 E(\varepsilon)=0 E(ε)=0,这也意味着,模型中的 β 0是常数,于是 y y y的期望值 E ( y ) = β 0 + β 1 。
参数的最小二乘估计

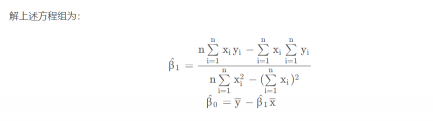
利用最小二乘法就可以求解合适的参数,一般在遇到问题时,我们都是借助计算机来求解,因为计算机只需要导入数据,直接可以生成所有结果。
在平时做题时,我们利用最小二乘法求解完参数就以为结束了,但是事实上还有很多工作没有做,或者说做了我们不知道,例如参数的检验,线性关系的检验和拟合效果评价。
回归直线的拟合优度
我们利用最小二乘法对数据进行了拟合,但是效果怎么样却不能直观看出,我们需要计算相关的指标,其中用来评价拟合效果的指标就是判定系数。
判定系数又称 R 2 R^2 R2,在了解 R 2 R^2 R2是如何计算前,需要了解几个定义:
我们可以用它来评价回归直线拟合的效果如何,当 R 2 的值越接近于1,就说明我们拟合的模型效果就越好。
在前面的相关系数我们计算的相关系数是 r,这里的判定系数为 R 2,都含有 r ,那么它们之间是否有某种关系呢?
答案是肯定的,在一元线性回归中,相关系数 r 实际上就是判定系数的平方根,利用这一结论就可以直接计算判断系数了。在前面我们说过通过 r 可以看出观测数据的线性关系如何,那么这里又知道也可以通过 r 来说明回归直线的拟合优度,但是有一点需要注意,用 r 来直接评判拟合优度的效果并没有 R 2 好,因为当 r
的值为0.5时, R 2 才有0.25,拟合的效果并不好,当 r的值为0.7时, R 2 才有0.5。所以我们一般不直接用 r 的值来评价模型的拟合优度。
回归直线的误差
上一节介绍的是回归直线的拟合优度,也就是拟合效果,通过计算判定系数来反映模型的拟合情况,这一节我们要讨论的是模型的预测能力,也就是测量各实际观测点在直线周围的散布状况,这个量就是标准误差,也叫 M S E MSE MSE。
还记得在机器学习中了解到 M S E MSE MSE是均方误差,在那里叫做:Mean squared error,而这里叫做估计量的标准差:Standard error of estimate。虽然说定义上不同,但是我觉得都大差不差,我是把两种的适用范围混在一起了,本文的标准差计算公式如下: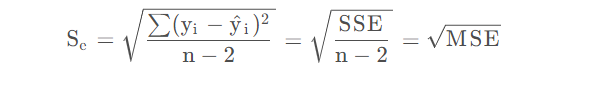
若 S e 的值为0,则说明误差为0,侧面表示了拟合优度很好。
M S E 反映了用估计的回归方程预测因变量 y时预测误差的大小。
显著性检验
没错,又是显著性检验,这已经是本文第二次接触显著性检验了,在前面说要检验相关系数的可靠性,在这里也需要检验回归系数的可靠性。不仅仅要检验回归系数的可靠性,还需要检验线性关系的可靠性,是不是很多?其实不需要担心这么多,这些东西计算机会帮我们计算好。
在前面说过,在根据样本来拟合回归方程时,实际上已经假定变量 x 与 y 之间存在线性关系,即 y = β 0 + β 1 ,并假定误差项 ε 是一个服从正态分布的随机变量,且对不同的 ε 都有相同的方差,但这些假设是否成立,需要检验才能证实。
线性关系的检验
第一个需要检验的就是自变量 x和因变量 y之间的线性关系是否显著,或者说,它们是否满足假定的条件。所有的检验方法都需要构建一个检验统计量,在这里统计量的构建是以回归平方和 S S R 以及残差平方和 S S E为基础的。将 S S R 除以其相应的自由度(自变量的个数 k ,一元回归中的 k 等于1)后的结果称为均方回归,记为 M S R,我们在这里关心的是线性关系显著,所以备择假设应该就是 x 和 y 满足线性关系,那么原假设就是 x 和 y 不满足线性关系,具体步骤如下:

线性关系的检验其实就是方差分析,关于两者的关系参考这篇文章方差分析与回归的关系
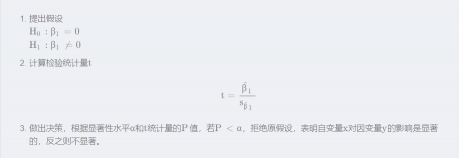
回归系数的检验
回归系数的显著性检验就是要检验自变量对因变量的影响是否显著的问题。其实就是检验回归系数是否等于0,详细步骤如下:
回归方程的预测
经过一系列的假设检验等等,终于找到合适和回归方程,现在我们可以使用这个方程进行预测。有人说,预测这不是很简单嘛,给定一个 x 值,把 x 带入回归方程直接计算不就行了嘛。没错就是这么简单,但是除此之外,我们还可以计算区间估计值,而这个区间估计值又分为两种:置信区间和预测区间。
置信区间
对于一个特定的 x 0 值,求出 y 的平均值的估计区间就是区间估计。一般来说, E ( y 0 ) 在 1 − α 置信水平下的置信区间可以表示为: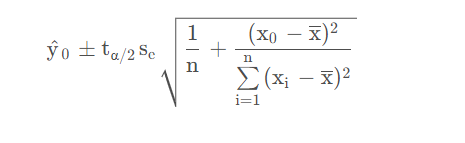
上面的 s e 是均方残差。 t α 是通过查表得到的。
预测区间

可以看到预测区间和置信区间的计算公式是非常的相似,只是预测区间中多了一个1。因此对于同一个 x 0 ,这两个区间的宽度也是不一样的,预测区间要比置信区间宽一些。
预测区间和置信区间的关系
至于为什么会有两个区间,这一点开始是比较困惑我的,预测区间和置信区间该怎么选呢?
在网上看到一个不错的回答:
预测区间:95%的预测区间,意味着,在此总体中随机抽取100个样本,其中大概有95个的个别值会落在这个区间
置信区间:95%的置信区间,意味着,从总体中随机抽取若干样本,其平均值会落在这个范围
一般来说,置信区间的参考意义更大,我们在平时做题的时候接触的基本上都是置信区间。
总结
相关系数和线性回归的内容肯定不止这么一点,这里也没把所有的内容都一一列出,我只是挑选了最基础最重要的部分。



评论(0)
您还未登录,请登录后发表或查看评论