

目标检测 YOLOv5 训练操作
1. 数据配置
1.1. 工具安装
1.2. 数据准备
1.2.1. 建立文件夹和基础文件
1.2.2. 编辑类别种类
1.2.3. 放置标注图片
1.3. 数据标注
1.4. 数据转换
1.5. 修改配置
1.5.1. 修改数据配置文件
1.5.2. 修改模型配置文件
2. 训练配置
2.1. 参数设置
2.2. 执行训练
3. 检测效果
1. 数据配置
1.1. 工具安装
Labelimg 是一款开源的数据标注工具,可以标注三种格式:
- VOC标签格式,保存为xml文件
- yolo标签格式,保存为txt文件
- createML标签格式,保存为json格式
安装也比较简单:
$ pip3 install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2. 数据准备
1.2.1. 建立文件夹和基础文件
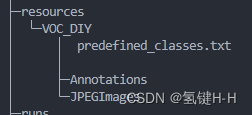
先在主目录建立一个 resources 文件夹,专门用来存放总的训练数据
然后在该目录下建立一个 VOC_DIY 文件夹,用于这次训练的数据文件夹
在这里面建立一个 JPEGImages 文件夹存放需要打标签的图片文件
再建立一个 Annotations 文件夹存放标注的标签文件
最后创建一个名为 predefined_classes.txt 的 txt 文件来存放所要标注的类别名称
最终结构如下:
1.2.2. 编辑类别种类
假设任务是需要一个检测人和手表的任务,那么目标只有两个
先编辑 predefined_classes.txt 文件,定义的类别种类:
person
watche
1.2.3. 放置标注图片
然后把待标注的图片放在 JPEGImages 文件夹中,这里演示只用10张:

实际应用时需要更多更好的数据,数量和质量都很重要
1.3. 数据标注
路径切换到yolov5\resources\VOC_DIY数据集文件夹中来
在该地址启动 labelimg
$ labelimg JPEGImages predefined_classes.txt基础的配置和使用参考网上随便搜一下就好了,如《labelImg使用教程》
主要设置:
- Auto Save mode:切换到下一张图的时候,会自动保存标签。
- Display Labels:显示标注框和标签
- Advanced Mode:标注的十字架悬浮在窗口上
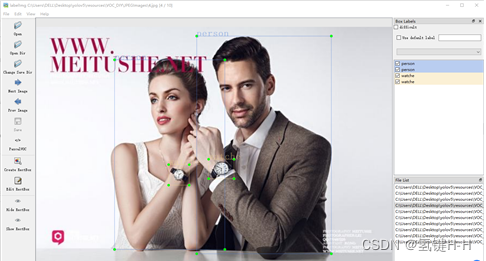
标注好了之后,可以在 Annotations 文件夹中查看:

1.4. 数据转换
目标检测的数据集资源标签的格式一般都是VOC(xml格式)
刚刚labelimg默认配置的也是,不过也可以自己设置为 yolo(txt格式)
现在就需要对xml格式的标签文件转换为txt文件
同时将数据集需要划分为训练集和验证集
路径切回工程主目录,建立一个 voc2yolo.py 文件实现以上所述功能
import xml.etree.ElementTree as ET
import os
import random
from shutil import rmtree, copyfile
classes = ["person", "watche"]
TRAIN_RATIO = 0.8
VOC_PATH = 'resources/VOC_DIY/'
CLEAR_HISTORICAL_DATA = True
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(VOC_PATH + 'Annotations/%s.xml' % image_id)
out_file = open(VOC_PATH + 'YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
work_sapce_dir = os.path.join(os.getcwd(), VOC_PATH).replace('/','\\')
annotation_dir = os.path.join(work_sapce_dir, "Annotations/").replace('/','\\')
image_dir = os.path.join(work_sapce_dir, "JPEGImages/").replace('/','\\')
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/").replace('/','\\')
yolov5_images_dir = os.path.join(work_sapce_dir, "images/").replace('/','\\')
yolov5_labels_dir = os.path.join(work_sapce_dir, "labels/").replace('/','\\')
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/").replace('/','\\')
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/").replace('/','\\')
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/").replace('/','\\')
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/").replace('/','\\')
dir_list = [yolo_labels_dir, yolov5_images_dir, yolov5_labels_dir,
yolov5_images_train_dir, yolov5_images_test_dir,
yolov5_labels_train_dir, yolov5_labels_test_dir]
for dir in dir_list:
if not os.path.isdir(dir):
os.mkdir(dir)
elif CLEAR_HISTORICAL_DATA is True:
rmtree(dir)
os.mkdir(dir)
print("Clean {}".format(dir))
train_file = open(os.path.join(work_sapce_dir, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(work_sapce_dir, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(work_sapce_dir, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(work_sapce_dir, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir)
list_imgs.sort()
random.shuffle(list_imgs)
imgs_len = len(list_imgs)
for i in range(0, imgs_len):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
if i <= TRAIN_RATIO * imgs_len:
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention)
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention)
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
print("\r进度:{:3d} %".format(int((i + 1) / imgs_len * 100)), end='', flush=True)
train_file.close()
test_file.close()
input("\n输入任意键退出")
运行该文件就可以得到所需的训练集和验证集了

1.5. 修改配置
1.5.1. 修改数据配置文件
编辑data目录下的相应的yaml文件
找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名为watche.yaml
根据项目实况保留有用信息:
path: ./resources/VOC_DIY
train: # train images (relative to 'path') 8 images
- images/train
val: # val images (relative to 'path') 2 images
- images/val
# Classes
nc: 2 # number of classes
names: ['person', 'watche'] # class names
1.5.2. 修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数
将yolov5s.yaml文件复制一份,然后将其重命名为yolov5_watche.yaml
根据项目实况改个;类型数量就好了:
# nc: 80 # number of classes
nc: 2 # number of classes
2. 训练配置
训练是利用 train.py 文件
2.1. 参数设置
同《YOLOv5 使用入门》一样,主要还是看参数设置:
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
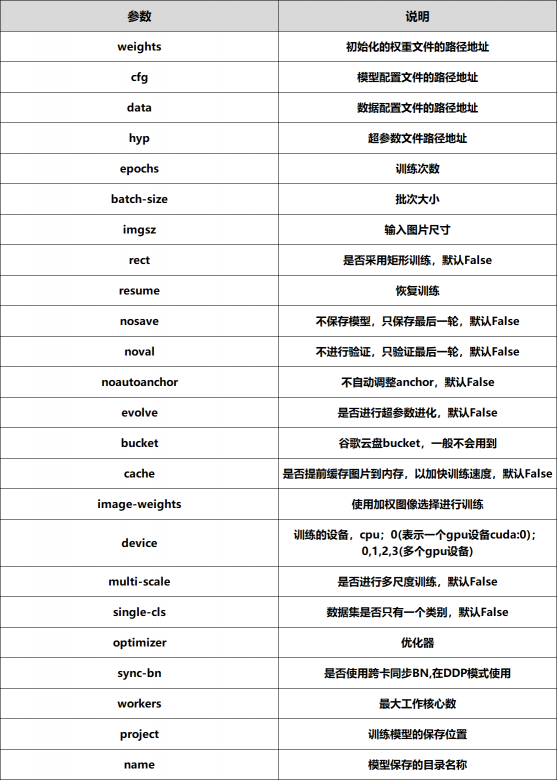
将权重路径、权重配置和数据集配置文件路径修改
parser.add_argument('--weights', type=str, default=ROOT / 'weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s_watche.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/watche.yaml', help='dataset.yaml path')
还有需要改动的一般就是训练次数、批次大小和工作核心数了
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
2.2. 执行训练
配置好后,直接执行
$ python train.py
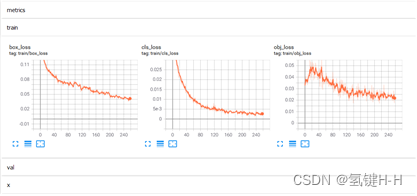
期间可以用 tensorboard 查看参数
$ tensorboard --logdir=runs/train复制显示的网址地址,在浏览器打开查看训练过程
3. 检测效果
训练过程数据和模型存放在 runs\train\exp 文件夹中
一个为最优的权重文件 best.pt,一个为最后一轮训练的权重文件 last.pt
在训练过程中大小在50M左右,不过训完成后处理为14M左右
参考 《YOLOv5 使用入门》,利用验证集的图片数据、刚训练好的模型和数据集配置进行检测:
$ python detect.py --source=resources/VOC_DIY/images/val/7.jpg --weights=runs/train/exp/weights/best.pt --data=data/watche.yaml
效果还是可以的

cls:1, xywh:[0.7656546235084534, 0.6132478713989258, 0.14231498539447784, 0.06410256773233414], conf:0.77
cls:0, xywh:[0.4962049424648285, 0.5197649598121643, 0.7267552018165588, 0.6314102411270142], conf:0.78



评论(0)
您还未登录,请登录后发表或查看评论