

计算机视觉基础
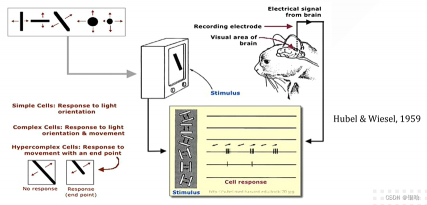
起源:生物视觉
用电极去刺激猫的控制视觉的大脑皮层 , 给一些图像给猫看,观察哪些图像对猫的视觉神经元会产生反应对大脑皮层产生刺激后,神经元细胞会产生移动,但其中我们发现对面向边缘移动的细胞有更复杂的功能,传递更复杂的视觉信息
计算机视觉处理的概念:
计算机图像处理:简称CV ,简单来理解就是代替人眼实现对目标的识别、分类、跟踪及场景理解。
它是指数字图像处理,指将图像信号转换成数字信号并利用计算机对其进行处理的过程,是通过计算机对图像进行去除噪声、增强、复原、分割、提取特征等处理方法和技术。
发展历程
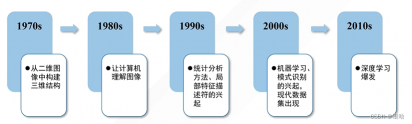
四大发展阶段:
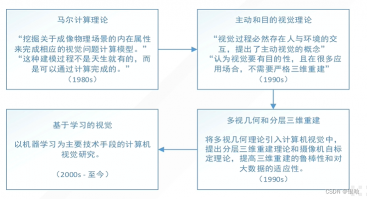
关键词提取:
- 马尔计算理论:
挖掘图像的内在属性-> 计算视觉模型- 主动和目的视觉理论:
人与环境交互-> 主动视觉
视觉目的性 -> 不需要三维重建- 多视几何和分层三维重建
多视几何理论+ 分层三维重建理论+摄像机自标定理论 -> 三维重建- 基于视觉
机器学习、深度学习
什么是数字图像?
一副图像可以定义为一个二维函数f(x,y) ,其中x,y 是空间平面坐标,而在任何空间坐标处的幅值f 称为该点处的强度或灰度。
- 当x,y和灰度值是有限的离散值时,该图像被称为数字图像。

图像与矩阵
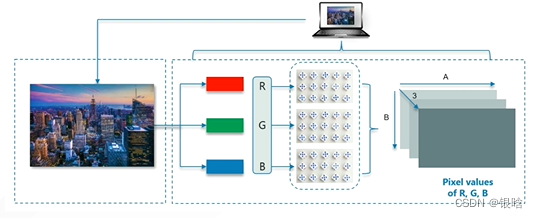
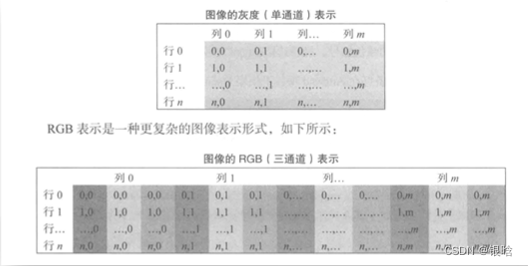
图片时通过像素拼接而成的,我们常说的分辨率指的是图像像素的数量,比如分辨率为1024*720 的一张图片就是在长度上的像素点为1024个,高度720个。每一个像素点在计算机存储的信息是它的RGB(红、绿、蓝组成的三原色,数值范围在[0-255]) ,将这些RGB以矩阵数据的方式存储在硬盘当中。
- 灰度图像只有1个通道(单原色),读取矩阵的shape为【x,y】,坐标【x,y】就是图像x行y列的像素值。
- RGB图像有三个通道(三原色),读取矩阵的shape为[x,y,3]
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
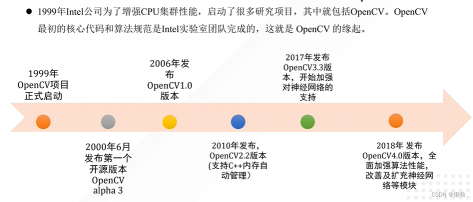
OpenCV简介
OpenCV — 开源计算机视觉库(Open Source Computer Vision Libary)
- OpenCV是基于BSD许可发行的跨平台计算机视觉库,可以在Win、Linux、mac 系统上运行
- 采用C++编写,轻量级且高效
发展历程
图像、视频基本操作
图像去噪
图像去噪是指减少数字图像中噪声的过程。现实中数字图像在数字化和传输过程中常受到成像设备与外部环境干扰等影响,称为含噪图像或噪声图像。


图像增强
有目的地增强图像的整体或局部特征特性,将原来不清晰的图像变得清晰起来或强调某些感兴趣的特征,扩大图像中不同物体之间的差别,抑制不感兴趣的特征,使之改善图像质量、丰富信息量、加强图像判读和识别效果

图像修补
图像修补技术,即去除图像中的小噪声或者划痕,这种技术的思想就是使用坏点周围的像素点取代坏点


图像分割
图像分割方法主要分为以下几类:
- 基于阈值的分割方法
- 基于区域的分割方法
- 基于边缘的分割方法
- 基于特定理论的分割方法
从数学的角度来看,图像分割是将数字图像划分成互不相交的区域的过程,也是一个标记的过程,即把属于统一区域的像素赋予相同的编号
- 不同的色块标识不同的物体

- 根据颜色阈值进行划分、提取

图像颜色通道分离(RGB分离)
RGB(Red Green Blue)三个通道的分量进行分别调整和显示,可以更好的观察一些图像材料的特征,进行图像处理

- 将一个彩色的图片分离成三原色,然后进行提取特征
图像二值化
图像的像素点的灰度值设置成0(黑)或255(白) ,也就是将整个图像呈现出明显的黑白效果的过程

滤波
滤波属于信号处理的概念,图像本身可以看成一个二维信号,其中像素点灰度值的高低代表信号强弱。
- 图像灰度变化剧烈的点是高频信号
- 图像灰度变化不大的点就是低频信号
根据图像的高频与低频的特征,我们可以设计高通、低通的滤波器。
- 高通滤波器可以检测图像中尖锐、变化明显的地方(提取边缘)
- 低通滤波器可以让图像变得光滑,滤除图像中的噪声(平滑图像)
- 均值滤波、高斯滤波、中值滤波

- 平滑:每个像素的值取周围像素的平均值。结果就是图像模糊化。
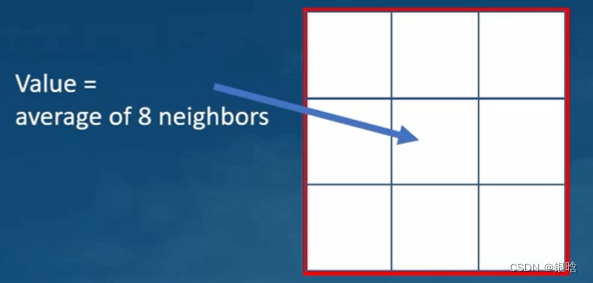
- 锐化:反向处理每一个像素与周围像素的差异。结果就是物体的边缘被强化放大(最极端的情况就是黑白图像,白色突出了所以的边缘)

图像特征提取
图像特征包括颜色特征、纹理特征、形状特征和空间关系特征。即一幅图像能表现其独特性或者易于识别性的区域。
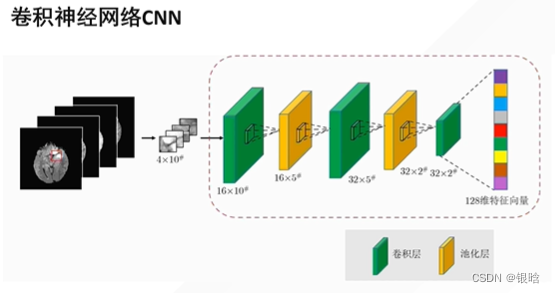
本质是一个特征提取的过程

特征匹配
特征匹配的方法是先找出特征显著的特征点,然后再分别描述两幅图像的特征点,形成特征描述符,最后比较两个特征描述符的相似程度来判断是否为同一个图像。
- 特征点相似的进行连接

视频处理
根据视频中捕获的图像与数据库中的图像进行匹配,返回相似的图像

基于OpenCV的图像读取与显示
- imread() : 图像读入函数
imread(filename , flags)
filename:图片的路径
flags:所读取图片的颜色类型
1.cv.IMREAD_COLOR : 读入彩色图像,忽略透明度,是默认参数
2.cv.IMREAD_GRAYSCALE : 读入灰度图像
3.cv.IMREAD_UNCHANGED : 读入一幅图像包括图像的alpha通道
----------------------------------
imshow():显示图片函数
----------------------------------
imwrite(filename , img):
filename:输出后的文件名
img:要保存的图片,保存图片的格式由文件名决定
1.cv2.imwrite("test.png",img)# 保存为png格式
2.cv2.imwrite("test.jpg",img) # 保存为jpg格式
视频的读取
- 本地摄像头实时捕获摄像头视频
inport cv2 as cv
cap = cv.VideoCapture(0) #捕获摄像头
#只要摄像头打开就一直接收画面
while cap.isOpened():
status , frame = cap.read()#读取摄像头帧
# 判断是否捕获到摄像头的下一帧的画面
if status:
#按键检查
k=cv.waitKey(25)&0XFF
key = chr(k)
if key == 'q':
break
cv.imshow('vedio',frame)
#结束
cv.destoryWindow('vedio')
- 255是白色 ,0是黑色
RGB三原色赋值(R= , G= ,B=)
物体边缘的像素急剧变化,所以我们能看见物体的边缘
如何加速视频处理进程
一个视频的数据量非常庞大,每一帧的数据量为 1920x1080 大约200w个像素 每个像素用RGB三原色表示,每个像素大约占3个字节,那么一张图片的大小为 1920 x 1080 x 3 = 6220800 bytes = 6.2MB
- 为了保证视频的流畅,每秒最少25帧,所以6.2 x 25 = 155MB /Second
- 1 Minute = 9.3GB
我们想要瞬间在互联网上获取这么大的数据量,而且视频源源不断的生成,根本不可能。
各位观众老爷根本不会运行卡顿的,要杀人的喔!
- 压缩!这个词跃然纸上,用最少的空间存储最大的数据
- Google可以做到 将 9.3GB压缩到 71.9MB/Minute
如何实现
冗余
- 空间冗余
几张图片的颜色大致一样,我们并不需要每次重新存储重复/相似的像素,只需要存储这些像素的平均值

2. 时间冗余
图像只是随着时间而进行移动,并未发生变化,直接使用前面图片存储的像素值就行了

I 帧:上一帧的图像
P帧:下一帧的图像
B帧:I帧如何转换为P帧的转换方法,大小为1/2 I帧的大小

3. 编码和解码
编码器 - > 解码器
视频文件:实际上是兼容其他文件的一个容器 ,比特率、分辨率、编解码器
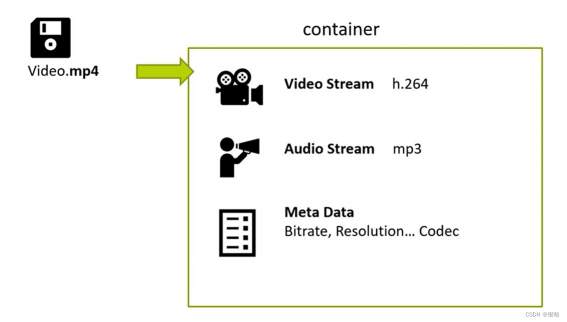
视频处理的任务:
- 处理存储在缓存器中海量的数据(每一帧)
- 两帧进行对比,观察变化
Intel GPU

-
EU:执行单元,可视为微型处理器,执行3D图形渲染等任务
-
快速视频同步技术 : 快速视频处理,同时解码20个高清视频流,或者编码12个高清视频流
视频处理流程

- 解码视频流
解码从多个渠道获得的视频流
- 预处理
如果图像质量不太好,我们需要改变图像质量,通过锐化等操作
如果图像很大,深度学习一般学习的是较小的图像,因此我们可以压缩图像、裁剪图像,让图像变小
还可以选择跳过几个帧,或者推理所以的帧
- 推理
第一阶段:我们有一个图像
第二阶段:使用深度学习模型进行推理
第三阶段:获得推理结果,这是一辆黑色的车
第四阶段:使用另一个模型来检测车牌第五阶段:获得最后的结果

4. 处理图像结果
例如:在被检查到的图像的边缘加上框框以标识
5.视频编码
保存所有的帧,进行压缩后发射
- 注意以上操作都是基于每一帧的操作,还有跨帧的操作
跨帧:
跟踪:如果相同的对象在视频中移动,我们了解这是想识别图像,我们在识别之后,我们没必要去重新检测它,节省大量资源
保存:例如在零售便利店内,我们的视频用来监控和检测顾客的异常行为,但是如果顾客没有发生异常行为,我们的视频还需要记录么?
Media-SDK
主要用来做视频的编解码、以及视频处理
Opencv DLDT : 主要用于深度学习的推理加速
opencv:能以上所有活,但是需要调整media-sdk

总结
了解了计算机视觉的基础吧,因为其他的代码根本看不懂,所以学点基础的吧。
常识
- 视频占互联网流量的80%
- 视频是一系列连续的图像,这些图像的移动速度足够的快,让我们的视觉感受到了连续、平滑的效果
- 每个图像都是由一组像素值组成的,每个像素都有自己的像素值或RGB三原色的值
- 我们可以操纵图像完成模糊、锐化等工作
- 我们可以查找图像的特征(边、线、角)
- 视频流传输的数据非常大
- 视频压缩利用图像的冗余性,将相同的图像进行压缩
视觉
- 视觉分析 = 图像处理+计算机视觉 + AI 推理
- 视频分析流程是向多个场景运用的负载
- 视频分析最耗费资源的操作就是对视频的每一个操作需要在每一帧上进行



评论(0)
您还未登录,请登录后发表或查看评论