

前言
在上一篇主要了解了语义分割,实例分割,全景分割的区别,以及labelme标注的数据进行转换,这边文章主要是通过deeplabV3+ 构建自己的语义分割平台
一、deeplabV3+
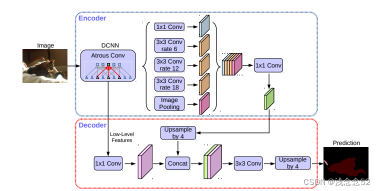
上图所示,是deeplabV3+的主体框架,简单来说就是编码,解码的过程。将输入的图片通过DCNN深度卷积神经网络,获得两个有效的特征层(浅层)(深层)对深层特征层进行ASPP(利用不同膨胀率的膨胀卷积进行特征提取,然后对特征进行堆叠,通过1X1卷积调整通道数,得到最终的特征)将高语义的特征信息经过上采样与浅层特征进行特征融合,在进行3X3的卷积,然后通过1*1卷积进行通道数的调整,调整成num_class(分类数)进行上采样使得最终输出层,宽高与输入图片一样,得到每一个像素点的每一个种类。
二、数据准备
1.我们首先要对数据进行一些处理

JPEGImages 存放的是图片
SegmentationClass 存放的是mask掩码图像

ImageSets 存放是一些txt文件

三、修改代码
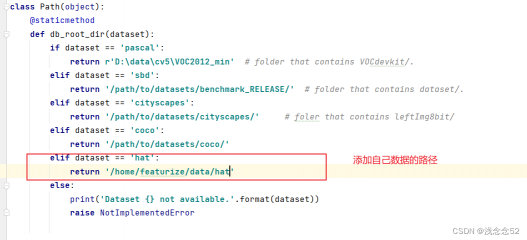
1.根目录下的mypath.py文件
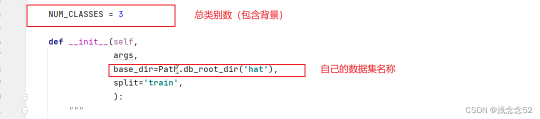
2.dataloaders\datasets创建自己的数据集文件hat.py
复制这一路径下的pascal.py文件
3.dataloaders/utils.py

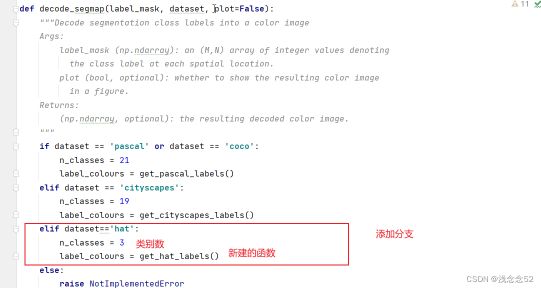
4.dataloaders/__init__.py

5.train.py

四、开始训练
一些主要的参数


然后就可以直接训练了:

也可以搭载服务器进行训练,可以看我之前的文章。
五、测试
训练完成之后,就可以进行测试了,下面直接看代码。
import torch
from modeling.deeplab_v3_50_modify_256 import deeplab_v3_50
import glob
import cv2
import os
from modeling.deeplab import *
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from utils.saver import save_colored_mask
num_class=3
path = 'test_image'
out_path='out_image'
test_images = glob.glob(os.path.join(path,"*.jpg"))
composed_transforms = transforms.Compose([transforms.ToTensor()])
totensor = transforms.ToTensor()
model=DeepLab(num_classes=num_class,backbone='drn')
model.load_state_dict(torch.load(r'D:\xiangmu\deeplaV3_run\run_hat\hat\deeplab-drn\model_best.pth.tar')['state_dict'])
model.eval()
def Normalize(img,mean,std):
img = np.array(img).astype(np.float32)
img /= 255.0
img -= mean
img /=std
return img
for test_image in test_images:
name=os.path.basename(test_image)
name=name.replace('jpg','png')
img = Image.open(test_image)
img_norm = Normalize(img,mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225))
img_resize = cv2.resize(img_norm,(513,513))
compose = composed_transforms(img_resize).unsqueeze(0)
out = model(compose)
pred=torch.argmax(out,1)[0].numpy()
H,W=img_norm.shape[0],img_norm.shape[1]
pred_orgin=cv2.resize(pred,(W,H),interpolation=cv2.INTER_NEAREST)
out_file=os.path.join(out_path,name)
save_colored_mask(pred_orgin,out_file)
print('save {} 测试完成'.format(out_file))
测试的结果:




评论(0)
您还未登录,请登录后发表或查看评论