

从第一章中了解到强化学习中,智能体通过和环境进行交互获得信息。这个交互过程可以通过马尔可夫决策过程来表示,所以了解一下什么是MDP至关重要。
不过在了解马尔可夫决策过程之前,先要一些预备知识,它们分别叫马尔可夫性质、马尔可夫过程/马尔可夫链、马尔可夫奖励过程。
马尔可夫性质(Markov property):如果一个状态的下一个状态只取决于当前状态,跟它当前状态之前的状态都没有关系。换句话说:未来的转移跟过去是独立的,只取决于现在。
给定一个状态的历史概念(其实就是过去状态的一个集合表示):
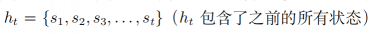
马尔可夫链(Markov Chain):一个状态转移链,从起始状态到结束状态。代表状态转换过程。
状态转移有很多种表示形式:
表示法1:图解法(图中包括状态之间发生转移的关系以及状态转移对应的回报值)

表示法2:状态转移矩阵法(矩阵维度等于状态,矩阵值为转移概率,以条件概率形式表示)
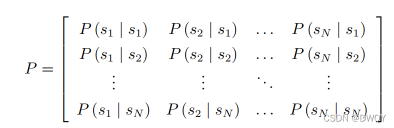
马尔可夫过程(Markov Process):其实书中并没有和马尔可夫链做太大的区分,对于RL来说,只需要明确它们都是表示存在状态转移就可以。但实际上还是有不同的,马尔科夫链更广泛一点,具体内容可以参考:马尔可夫链_百度百科 (baidu.com)
举个马尔可夫链的例子:s3,s2,s3,s2,s1。从头到尾的执行过程就可以叫做马尔可夫过程。
马尔可夫奖励过程(Markov reward process)=马尔可夫链+奖励函数
那什么是奖励函数呢?在前面的概论中,了解到RL过程中状态转移会有奖励。这个奖励函数就是这个奖励的一种表示。之前是概念性的,现在用数学化的方式来表达一下。
回报(return):当前状态及之后状态的总收益,一般把之后的状态打折扣。如下,回报常用G表示:
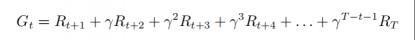
ps:上式中R就是奖励函数
回报是针对每一个状态的,从上一章中了解到。价值函数是用来判断策略好坏的。那有没有办法去衡量一个状态的价值呢?方法当然有,其实就是价值函数的分类之一:状态价值函数(state-value function)。对于马尔可夫过程而言,状态价值函数定义为回报的期望:
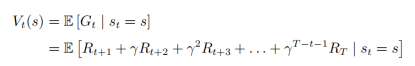

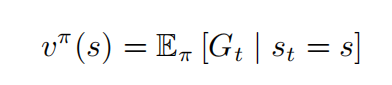

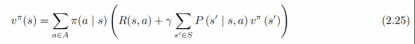
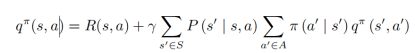
对于贝尔曼方程的推导比较难以理解,直接啃书本可能会懵。这里推荐一个视频课,我觉得讲的很清楚(直接去看,不要多说,看了就会):
【强化学习】马尔科夫决策过程【白板推导系列】_哔哩哔哩_bilibili
学的时候直接找这个就行,为了证明我会了,我也会手动推理一遍。并在旁边标上注释。可以作为学习参考:贝尔曼最优方程(Bellman optimality equation)推导如下:因为我们的目标是最优策略,所以贝尔曼最优方程就是从最优的角度出发。推导前后关系。
现在,明确了贝尔曼方程。继续往下看:上式也是马尔可夫奖励函数的推导式,那现在来看看如何求解马尔可夫奖励函数的价值,有两种方式,分别对应了两种情况:
1)解析解:对应状态量较小使用的主要思想是把整体矩阵化,在此不进行推导了。只摆出结论:
其中V代表价值,I代表单位矩阵,γ代表折扣因子,P代表状态转移矩阵,R代表每个状态的回报(因为其中有求逆的操作,复杂度较高,状态数过多代表矩阵维度过高,不易计算)
2)迭代解:对应状态量较大
迭代求解的方法有很多种,在此简单介绍下(后面会多次详细的使用这些方法):
(1)蒙特卡洛法(MC):进行一次实验,产生一次轨迹。得到一次奖励。多次实验取平均,作为价值。伪代码如下:(2)动态规划法(DP):迭代中关注状态变化,等到状态变化不大时,更新停止,再计算当前状态对应的价值。伪代码如下:(3)时序差分法(TD): MC中需要完成一次完成的奖励采样才能得到结论,那如果存在一些限制,无法结束。能否通过相邻两个状态的变化就求解出想要的内容呢?这就是时序差分干的事情。在此给一个思想,后面会详细的介绍相关内容的。ps:动态规划法中涉及到一个概念:自举,这是一种思想,指根据其他估算值来更新估算值。重点是估算值,说明就不是准确的。下面介绍一些概念,从概念引出要介绍的内容:策略评估:计算状态价值函数的过程叫做策略评估。另外一种含义是预测当前采取的策略最终会产生多少的价值预测和控制(马尔可夫决策过程里面的两个关键问题):预测指给定一个马尔可夫决策过程<S,A,P,R,γ>及一个策略Π,去计算它的价值函数(两个输入一个输出)控制指我们去寻找一个最佳的策略,然后同时输出它的最佳价值函数和最佳策略(一个输入两个输出)比较两者区别,预测要策略已知,控制是策略未知。两者之间的存在递进关系,在RL中一般是先解决预测问题,然后再解决控制问题。马尔可夫决策过程控制:已有一个马尔可夫决策过程,确定最佳策略和最佳价值函数。最佳策略和最佳价值函数之间有什么关系吗?其实它们是一个东西,取到了最佳策略就对应的是最佳价值函数。一般求的话是先取得最佳的价值函数,然后问题转变成如何得到最佳策略,通过的方式就是Q函数极大化。啥意思呢?直白点儿说最优策略就是每步动作都是价值最大的,那就从所有的动作中选择一个最大的,以这个动作作为策略的一部分就OK了。当然这个只是概念上的一种方法,具体怎么实现呢?寻找最佳策略有个专业术语叫做:策略搜索。最简单的办法就是穷举,然后根据回报选一个最佳策略。但效率很低,常用的两种方法是策略迭代和价值迭代
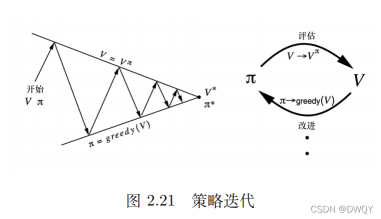
策略迭代:
策略迭代由两部分组成:策略评估+策略改进策略评估:已有一个策略Π,计算这个策略的价值函数V策略改进:得到价值函数V,通过奖励函数和状态转移计算Q函数。通过最大化Q生成新策略。价值迭代:价值迭代算法的精髓是不停地去迭代贝尔曼最优方程,到最后会趋向于最佳策略,策略迭代与值迭代都属于强化学习里面策略求解中的动态规划方法如果到这儿还不太清楚策略迭代和价值迭代也不用着急,具体的内容还在后面,我在网上找了一些相关的内容,可以看一看,提前学习一下下:策略迭代流程:策略迭代的目的是寻找最优策略,方法是不断更新策略。更新策略的方法是不断选择状态价值最高的策略。让状态价值变高的方法是选择正确的状态。这是反向过程,首先根据状态计算状态的价值,让价值收敛就是选择出具有最高价值的状态/确定了新策略的评估函数。利用评估函数,确定每一个状态选择每一个动作的价值。选择价值最高的动作,将这个动作作为策略。这个策略比之前的有所改进。价值迭代流程:价值迭代的目的是寻找最优策略和最大价值函数。进行价值函数更新时就直接选择最好的。策略迭代中利用的是收敛即可,这里是要尝试所有状态的所有动作,选择其中最大的价值。并将这个期望价值函数作为当前状态的价值函数,然后收敛就行。利用最有价值函数和状态转移概率计算出最优动作,这就是最优策略
参考: 策略迭代与值迭代的区别_dadadaplz的博客-CSDN博客_值迭代和策略迭代区别
老规矩,课后题来!2-1 折扣因子有三个作用:1)防止无穷奖励 2)倾向与当前奖励 3)表达不确定性
2-2 解析解求解的时候计算了矩阵的逆,矩阵的维度是状态数,状态数过多时,求解时间复杂度很高
2-3 贝尔曼方程的推导写了一遍,我觉得我掌握一种就够了(狗头保命)
2-4 决策过程比奖励过程多了一个决策的动作层
2-5 马尔可夫奖励比马尔可夫过程结构上多了每次状态转移的奖励
2-6 价值迭代和策略迭代,策略迭代只寻找最优策略,价值迭代寻找最优策略及最优价值函数2-1 马尔可夫过程指状态转移过程,而且下一时刻状态只取决于当前状态,与当前状态前面的状态无关。马尔可夫决策过程指马尔可夫奖励过程+策略选择。 最重要的性质只有相邻状态间存在相关性
2-2 策略迭代和价值迭代
2-3 ?????
2-42-5 都是最优情况下,按照最优的唯一性,最佳价值函数和最优策略对应的应该是相同情况2-6 当n越来越大时,方差应该是变大的。这点类比于MC和TD的关系,MC相当于n趋近于无穷,MC的方差更大。类似MC的期望更小,n越大,期望也会越小学完MDP这一章,我们明确了要寻找最佳策略,给了策略迭代和价值迭代的方法。本文介绍了思想,但是它们具体是怎么实现的呢?且听下回分说。因作者水平有限,如果错误之处,请在下方评论区指正,谢谢!


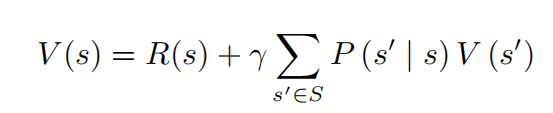



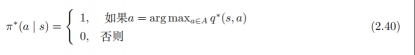




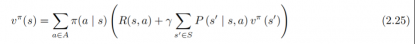
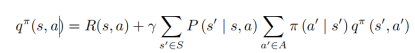



评论(0)
您还未登录,请登录后发表或查看评论