

0x00 往期博文
《HelloOriginBot::使用Python编写Joy手柄功能包》
0x01 项目介绍
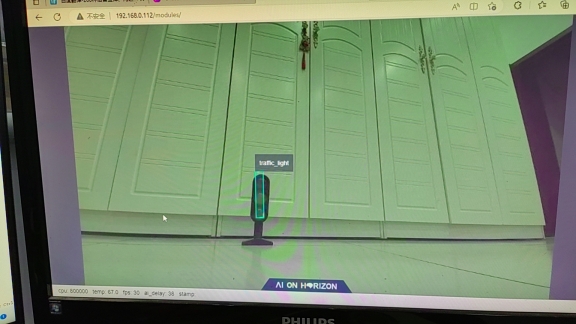
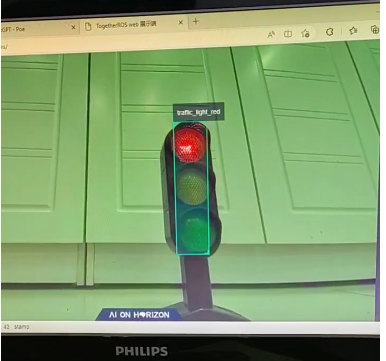
在智慧交通的场景下,一定有红绿灯的身影。如何帮助机器人识别交通标识红绿灯,成了计算机视觉一个重要问题。基于PPYOLO算法,本项目针对该红绿灯设计了一个目标检测模型,可实时通过视觉检测出红绿灯当前的信号状态,并且利用地平线旭日X3派5TPOS的算力,和地平线机器人开发平台的快捷部署能力进行部署。后续可以配合机器人用于智慧交通、nav导航的APP设计。
在地平线机器人开发平台(tros)上运行的红绿灯识别应用,帧数30FPS,可达到实时性要求。

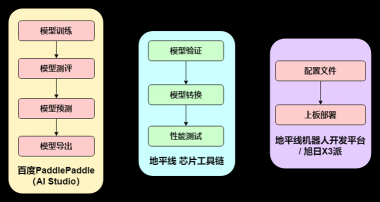
0x02 整体开发部署流程
使用 PaddleDetection 开发套件快速进行落地应用。
模型选择如下:
参考文章:
0x03 数据采集
Originbot 小车启动 mipi 摄像头采集图像,并发布 /image_raw 话题;
# 启动mipi摄像头采集图像,并发布 /image_raw 图像
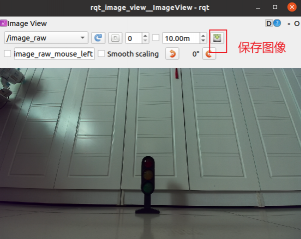
ros2 launch originbot_demo camera.launch.pyPC端使用 rqt_image_view 订阅 /image_raw 并显示图像;
# 在开发机上订阅 /image_raw,显示图像
ros2 run rqt_image_view rqt_image_view手动调整小车位置,手动保存欲采集的交通灯信号图像。
最终效果,各个距离、角度,四种状态(无亮灯、红、绿、黄)的信号灯图片如下,只采集了83张;

未来改进方案:
1、 用于训练的数据集图片过少,没有涵盖大部分小车姿态下的红绿灯图像,准确率仅为70%,需要小车扭动姿态 (原地转圈) 寻找红绿灯;
<解决方案 :> 控制小车以不同角度和距离观察红绿灯,并录制视频,逐帧标注加大数据量;
0x04 数据标注
使用 '精灵标注助手' 进行数据标注,categories 如下:
0: traffic_light
1: traffic_light_red
2: traffic_light_yellow
3: traffic_light_green
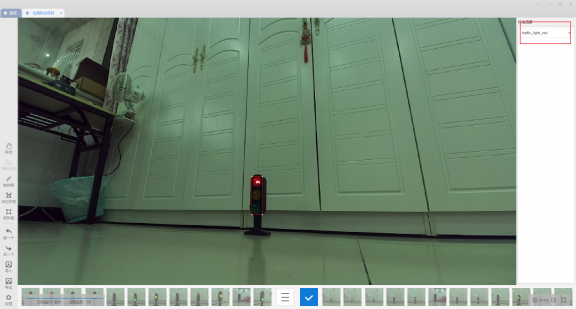
0x05 数据增强
使用 roboflow 平台进行数据增强;
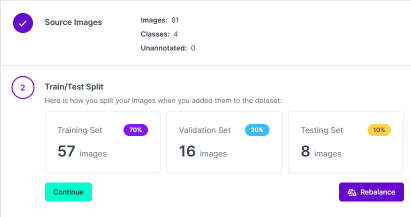
1\ 上传原始数据集81张图像,平台自动按比例分成 Traing Set,Vaildation Set, Testing Set;
2\ 添加前处理;
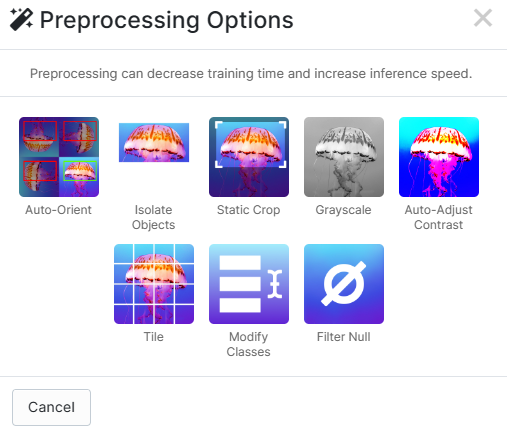
您还可以添加更多的前处理选项,例如:
auto orient : 自动定向;
isolate objects : 部分对象;
static crop : 静态裁剪;
grayscale : 灰度;
auto-adjust contrast : 自动调整对比度;
tile : 网格?
3\ 添加数据增强选项;
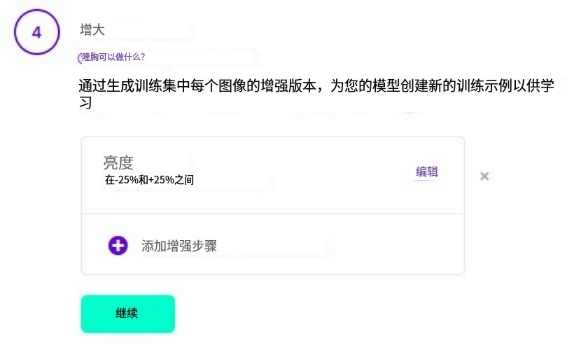 .
.
本项目只对 '亮度' 进行增强,以适应相对昏暗和曝光的环境。
除此之外您还可使用以下数据增强选项:

4\ 导出数据集;

数据从原始的81张,增强到了 195 张;
0x06 模型训练
参考文章:
1\ 上传数据集至Ai studio 项目的 //PaddleDetection/dataset/traffic_coco下;
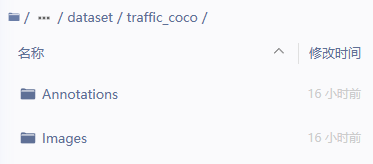
2\ Annotations 对应 roboflow 导出的 训练集,验证集,测试集的三个json文件;Images下存放全集(三个集)图像;
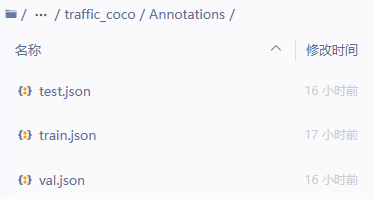
3\ 模型训练;
一行代码, pp 很方便落地;
# 2) 模型训练
!python tools/train.py -c configs/ppyolo/ppyolo_r18vd_coco.yml --eval4\ 模型评估;
# 3)模型评估
!python tools/eval.py -c configs/ppyolo/ppyolo_r18vd_coco.yml -o use_gpu=true weights=output/ppyolo_r18vd_coco/best_model.pdparams5\ 模型预测;
# 4) 模型预测
# 单张图片预测
!python tools/infer.py -c configs/ppyolo/ppyolo_r18vd_coco.yml --infer_img=dataset/traffic_coco/Images/38_0_png.rf.0965ed887ee7a999a14d0c9d34f81a93.jpg -o weights=output/ppyolo_r18vd_coco/best_model.pdparams
0x07 模型导出
参考文章:
1\ 导出paddle模型;
由于Paddle模型导出包含了模型后处理部分,而地平线dnn处理只对模型部分进行BPU转换,因此需要Paddle模型进行处理。
主要分为两步:去掉检测后处理部分(NMS)、调整输出各通道位置;
不必关心,文档中都给出了脚本,直接执行即可;聚焦应用层;
2\ 导出ONNX模型;
得到和地平线工具链兼容的 ppyolo_traffic.onnx 模型;
0x08 使用Docker搭建工具链环境
1\ 环境搭建
地平线 XJ3 芯片工具链 版本发布及Filezilla使用教程 (horizon.ai)
下载OE(open explor)天工开物工具包,和 cpu_docker 镜像;
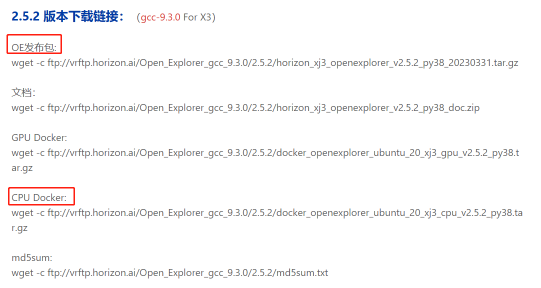
2\ windows11 安装 docker Desktop;
略
3\ 加载 docker 镜像;
docker load -i 'H:\0x05 OriginBot\x3 OS\docker_openexplorer_ubuntu_20_xj3_cpu_v2.5.2_py38.tar.gz'4\ 挂载OE开发包,创建并启动容器;
docker run -it -d -v "H:\0x05 OriginBot\x3 OS\horizon_xj3_open_explorer_v2.5.2-py38_20230331\ddk\samples":/data --name "horizon" edb84072ae7b
5\ 在Docker中进入OE开发包的 data\ai_toolchain\horizon_model_convert_sample\04_detection\02_yolov3_darknet53 路径;
ppyolov3 所以使用 '02_yolov3_darknet53' 这个demo;
6\ 备份 mapper 文件夹;
7\ 按步骤执行 sh 脚本;
0x09 工具链量化
1\ 01_check.sh :: 检查 BPU是否支持 模型层、算子;
set -e -v
cd $(dirname $0) || exit
# onnx 模型
model_type="onnx"
# ai_studio 导出的模型放在该路径下
onnx_model="./model/ppyolo_traffic.onnx"
march="bernoulli2"
hb_mapper checker --model-type ${model_type} \
--model ${onnx_model} \
--march ${march}sudo bash 01_check.sh 或者 ./01_check.sh 执行检查脚本,出现以下内容表示检查完成,并显示算子支持情况,不支持的算子将会在CPU上运行。 CPU + BPU = 异构混合模型?
2\ 02_preprocess.sh 生成前处理数据集,用于标定数据;
set -e -v
cd $(dirname $0) || exit
python3 ../../../data_preprocess.py \
--src_dir ./model/calibration_data \
--dst_dir ./calibration_data_rgb_f32 \
--pic_ext .rgb \
--read_mode opencv \
--saved_data_type float32./model/calibration_data 下放置 100 张在Ai studio上训练用的图像,执行此脚本会自动标定用的图像;
3\ 03_build.sh 量化生成 *.bin 模型,用于板端部署;
set -e -v
cd $(dirname $0)
config_file="./ppyolo3_config.yaml"
model_type="onnx"
# build model
hb_mapper makertbin --config ${config_file} \
--model-type ${model_type}ppyolo3_config.yaml 文件如下:
# 模型转化相关的参数
model_parameters:
# onnx浮点网络数据模型文件
onnx_model: "./model/ppyolo_traffic.onnx"
# 适用BPU架构
march: "bernoulli2"
# 指定模型转换过程中是否输出各层的中间结果,如果为True,则输出所有层的中间输出结果,
layer_out_dump: False
# 日志文件的输出控制参数,
# debug输出模型转换的详细信息
# info只输出关键信息
# warn输出警告和错误级别以上的信息
log_level: 'debug'
# 模型转换输出的结果的存放目录
working_dir: 'model_output'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'ppyolo_traffic_416x416_nv12'
# 模型输入相关参数, 若输入多个节点, 则应使用';'进行分隔, 使用默认缺省设置则写None
input_parameters:
# (可不填) 模型输入的节点名称, 此名称应与模型文件中的名称一致, 否则会报错, 不填则会使用模型文件中的节点名称
input_name: "image"
# 网络实际执行时,输入给网络的数据格式,包括 nv12/rgb/bgr/yuv444/gray/featuremap,
# 如果输入的数据为yuv444, 模型训练用的是bgr(NCHW),则hb_mapper将自动插入YUV到BGR(NCHW)转化操作
input_type_rt: 'nv12'
# 转换后混合异构模型需要适配的输入数据排布,可设置为:NHWC/NCHW
# 若input_type_rt配置为nv12,则此处参数不需要配置
input_layout_rt: 'NHWC'
# 网络训练时输入的数据格式,可选的值为rgb/bgr/gray/featuremap/yuv444
input_type_train: 'rgb'
# 网络训练时输入的数据排布, 可选值为 NHWC/NCHW
input_layout_train: 'NCHW'
# 模型网络的输入大小, 以'x'分隔, 不填则会使用模型文件中的网络输入大小,否则会覆盖模型文件中输入大小
input_shape: '1x3x416x416'
# 网络输入的预处理方法,主要有以下几种:
# no_preprocess 不做任何操作
# data_mean 减去通道均值mean_value
# data_scale 对图像像素乘以data_scale系数
# data_mean_and_scale 减去通道均值后再乘以scale系数
norm_type: 'data_mean_and_scale'
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
mean_value: 123.68 116.28 103.53
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔
scale_value: 0.0171 0.0175 0.0174
calibration_parameters:
# 模型量化的参考图像的存放目录,图片格式支持JPEG、BMP等格式,输入的图片
# 应该是使用的典型场景,一般是从测试集中选择20~100张图片,另外输入
# 的图片要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 若有多个输入节点, 则应使用';'进行分隔
cal_data_dir: './calibration_data_rgb_f32'
# 如果输入的图片文件尺寸和模型训练的尺寸不一致时,并且preprocess_on为true,
# 则将采用默认预处理方法(skimage resize),
# 将输入图片缩放或者裁减到指定尺寸,否则,需要用户提前把图片处理为训练时的尺寸
preprocess_on: False
# 模型量化的算法类型,支持kl、max、default、load,通常采用default即可满足要求, 若为QAT导出的模型, 则应选择load
calibration_type: 'kl'
# 编译器相关参数
compiler_parameters:
# 编译策略,支持bandwidth和latency两种优化模式;
# bandwidth以优化ddr的访问带宽为目标;
# latency以优化推理时间为目标
compile_mode: 'latency'
# 设置debug为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR带宽占用等
debug: False
# 编译模型指定核数,不指定默认编译单核模型, 若编译双核模型,将下边注释打开即可
core_num: 2
# 优化等级可选范围为O0~O3
# O0不做任何优化, 编译速度最快,优化程度最低,
# O1-O3随着优化等级提高,预期编译后的模型的执行速度会更快,但是所需编译时间也会变长。
# 推荐用O2做最快验证
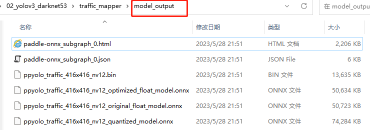
optimize_level: 'O2'执行脚本后得到:
*.html为模型分析:

BPU双核运行49FPS,20ms延迟;
生成文件说明:
original:原始浮点数 onnx 模型;
quantized_model : 量化为int8 的 onnx模型,与 *.bin 精度一致;
*.bin 板端部署用;
04\ 不需要再执行 04_inference.sh 、 05_evaluate.sh 有bug,后处理代码不一致;
ppyolov3 输出两层, yolov3 输出 3层,提示数组越界;
0x0A 上板运行
参考:
dnn_node_example · develop · HHP / box / hobot_dnn · GitLab (horizon.ai)
1\ 将 ppyolo_traffic_416x416_nv12.bin 文件拷贝到小车的 ./config 文件夹下;
2\ ppyoloworkconfig.json 内容如下:
{
"model_file": "config/ppyolo_traffic_416x416_nv12.bin",
"model_name": "ppyolo_traffic_416x416_nv12",
"dnn_Parser": "yolov3",
"model_output_count": 2,
"class_num": 5,
"cls_names_list": "config/traffic_coco.list",
"strides": [32, 16],
"anchors_table": [[[2.53125, 2.5625], [4.21875, 5.28125], [10.75, 9.96875]], [[0.625, 0.875], [1.4375, 1.6875], [2.3125, 3.625]]],
"score_threshold": 0.3,
"nms_threshold": 0.45,
"nms_top_k": 500
}
model_name 与 工具链 ppyolo3_config.yaml :: output_model_file_prefix 参数一致;
修改 class_nun 为 5; (在 roboflow 生成分类时出现的bug,有两个 traffic_light 标签; 正常应该为 4 ,不影响最终运行效果;)
3\ traffic_coco.list 内容如下:
0
traffic_light
traffic_light_green
traffic_light_red
traffic_light_yellowbugs:
class_nun 为 5,第一行设为0不会在检测中出现。
序号顺序错误,疑似板端 '前处理配置' 中颜色通道设置错误,导致识别错误,这里直接修改了序号顺序,正常运行;
4\ 执行以下命令,开始实时检测;
ros2 launch dnn_node_example hobot_dnn_node_example.launch.py \
config_file:=config/ppyoloworkconfig.json \
msg_pub_topic_name:=ai_msg_mono2d_traffic_detection \
image_width:=960 image_height:=5445\ PC端web登录小车ip,可查看识别效果;

评论(0)
您还未登录,请登录后发表或查看评论