目标检测是计算机视觉领域中的一个重要问题,它需要从图像或视频中检测出物体的位置和类别。近年来,深度学习技术在目标检测领域取得了显著的进展,其中一个重要的方法是基于YOLO(You Only Look Once)算法的目标检测。 YOLO算法的优点是速度快,但是在检测小物体和密集物体方面存在一定的问题。因此,本文将介绍一些改进的YOLO目标检测方法,以提高其性能和效率。 一、多尺度训练 YOL
腐蚀和膨胀demo1 # 腐蚀 import cv2 import numpy as np img = cv2.imread("./atm.jpg") k = np.ones((3, 3), np.uint8) cv2.imshow("img", img) dst = cv2.erode(img, k) cv2.imshow("dst", dst) cv2.waitKey() cv2.destr
0. 简介 对于基于环视视觉的3D检测而言,目前已经有很多文章了。因为基于视觉的3D检测任务是自动驾驶系统感知的基本任务,然而,使用单目相机的2D传感器输入数据来实现相当好的3D BEV(鸟瞰图)性能不是一项容易的任务。这篇文章《Surround-View Vision-based 3D Detection for Autonomous Driving: A Survey》就是围绕着现有的基于视觉
滤波器 demo1 # 均值滤波器 import cv2 # 读取原图 img = cv2.imread("./atm.jpg") img = cv2.resize(img, None,None, 0.5, 0.5) # 使用大小为3×3的滤波核进行滤波 dst1 = cv2.blur(img, (3, 3)) # 使用大小为5×5的滤波核进行滤波 dst2 = cv2.blur(img, (5
模板匹配 demo1 # 单模板匹配 import cv2 img = cv2.imread("./rh.png") template = cv2.imread("./template.png") img = cv2.resize(img, None, None, 0.5, 0.5) height, width, c = template.shape # 按照标准平方差方式匹配 result
0. 简介 由于点云的不规则数据形式以及散点的稀疏性,当前的方法难以从点云中提取高判别性的特征,在大规模环境中使用激光雷达进行全局定位仍是一个难以解决的问题。《BVMatch: Lidar-Based Place Recognition Using Bird’s-Eye View Images》一文中将点云表示为鸟瞰(Bird’s eye View, BEV)图像,从图像特征构建的角度设计了一个二
概述 椭圆检测是图像处理中的一个重要问题,其目的是从图像中检测出可能存在的椭圆。在实际的应用中,椭圆常常被用来描述物体的形状或者得到物体的尺寸信息。 传统的椭圆检测方法通常采用二维Hough变换,在求解过程中需要处理大量的数据,并且计算复杂度高,导致速度较慢,难以实现实时处理。相比之下,一维Hough变换不仅计算量小,而且可以更快地检测出椭圆。 一维Hough变换原理 一维Hough变换的基本思
图像的运算 demo1 import cv2 import numpy as np mask = np.zeros((150, 150, 3), np.uint8) mask[50:100, 20:80, :] = 255 cv2.imshow("mask1", mask) mask[:, :, :] = 255 mask[50:100, 20:80, :] = 0 cv2.imshow("mas
图像的阈值处理 demo1 # 二值化处理黑白渐变图 import cv2 img = cv2.imread("./img.png", 0) # 二值化处理 t1, dst = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) cv2.imshow("img", img) cv2.imshow("dst", dst) cv2.waitKey() cv2
图像的几何变换 demo1 # dsize实现缩放 import cv2 img = cv2.imread("./cat.jpg") dst1 = cv2.resize(img, (100, 100)) dst2 = cv2.resize(img, (400, 400)) # cv2.imshow("img", img) # cv2.imshow("dst1", dst1) # cv2.imsho
绘制图形和文字 demo1 # 绘制线段 import cv2 import numpy as np # 创建一个300×300 3通道的图像 canvas = np.ones((300, 300, 3), np.uint8)*255 # 绘制一条直线起点坐标为(50, 50)终点坐标为(250,50),颜色的BGR值为(255, 0, 0)(蓝色),粗细为5 canvas = cv2.line(
色彩空间和通道 demo1 import cv2 hsv_image = cv2.imread("./img.png") cv2.imshow("img", hsv_image) hsv_image = cv2.cvtColor(hsv_image, cv2.COLOR_BGR2HSV) h, s, v = cv2.split(hsv_image) cv2.imshow("B", h) cv2
open cv 入门 像素的操作 demo1 import cv2 import os import numpy as np # 1、读取图像 # imread()方法 # 设置图像的路径 Path = "./img.png" # 设置读取颜色类型默认是1代表彩色图 0 代表灰度图 # 彩色图 flag = 1 # 灰度图 #flag = 0 # 读取图像,返回值是一个图像对象 image
出处:https://blog.csdn.net/m0_66307842/article/details/128571685?spm=1001.2014.3001.5501作者:流继承 Ⅰ. 模版匹配和霍夫变换 0x00 模板匹配 原理所谓的模板匹配,就是在给定的图片中查找和模板最相似的区域,该算法的输入包括模板和图片,整个任务的思路就是按照滑窗的思路不断的移动模板图片,计算其与图像中对应区域
出处:https://blog.csdn.net/m0_66307842/article/details/128570468?spm=1001.2014.3001.5501作者:流继承 Ⅰ. 边缘检测算法 0x01.Canny边缘检测 Canny边缘检测算法是由4步构成,分别介绍如下: 第一步:噪声去除由于边缘检测很容易受到噪声的影响,所以首先使用高斯滤波器去除噪声,在图像平滑那一章节中已经介绍
OpenCV基本操作主要介绍图像的基础操作,包括: 图像的IO操作,读取和保存方法 在图像上绘制几何图形 怎么获取图像的属性 怎么访问图像的像素,进行通道分离,合并等 怎么实现颜色空间的变换 图像的算术运算图像的基础操作学习目标 掌握图像的读取和保存方法 能够使用OpenCV在图像上绘制几何图形 能够访问图像的像素 能够获取图像的属性,并进行通道的分离和合并 能够实现颜色空间的变换 读
0. 简介 Camera与LiDAR之间的外部标定研究正朝着更精确、更自动、更通用的方向发展,由于很多方法在标定中采用了深度学习,因此大大减少了对场景的限制。然而,数据驱动方法具有传输能力低的缺点。除非进行额外的训练,否则它无法适应数据集的变化。随着基础模型的出现,这个问题可以得到显著缓解,通过使用分割任意模型(Segment Anything Model,SAM),我们这次提出了一种新的激光雷达
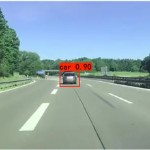
项目成果图 目标检测YOLOv5是一种计算机视觉算法,它是YOLO(You Only Look Once)系列算法的最新版本,由Joseph Redmon和Alexey Bochkovskiy等人开发。它是一种单阶段目标检测算法,可以在图像中检测出多个物体,并输出它们的类别和位置信息。相比于以往的YOLO版本,YOLOv5具有更高的检测精度和更快的速度 网络架构YOLOv5使用了一种新的检测架
概述与简介 RT-DETR是一种实时目标检测模型,它结合了两种经典的目标检测方法:Transformer和DETR(Detection Transformer)。Transformer是一种用于序列建模的神经网络架构,最初是用于自然语言处理,但已经被证明在计算机视觉领域也非常有效。DETR是一种端到端的目标检测模型,它将目标检测任务转换为一个对象查询问题,并使用Transformer进行解决。R
姿态识别技术是一种基于计算机视觉的人体姿态分析方法,可以通过分析人体的姿态,提取出人体的关键点和骨架信息,并对人体的姿态进行建模和识别。随着深度学习技术的发展,近年来姿态识别技术得到了广泛的应用和研究,其中Pose是一种基于深度学习的姿态识别工具包。本篇博客将介绍Pose的原理和方法,并探讨其在姿态识别领域的应用。目前识别手势,举左手 右手 双手 叉腰等姿态 一、 Pose的原理Pose是开发的
第三方账号登入
看不清?点击更换

















第三方账号登入
QQ 微博 微信