

引言
本实验基于FNC(全卷积神经网络)及PASCAL-VOC数据集做图像语义分割。图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。
图像分类是图像级别的:图像中的局部抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。
图像语义分割是像素级别的:与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。本实验就基于FNC做图像语义分割。
 其实验结果如图2-4所示:
其实验结果如图2-4所示:
卷积神经网络
卷积神经网络(CNN)是一种经典的深度学习架构,受生物自然视觉认知机制启发而来。1959年,Hubel & Wiesel 发现,猫对于物体的感知在视觉皮层中是分层处理的。受此启发,1980年 Kunihiko Fukushima 提出了CNN的前身——neocognitron 。 20世纪 90 年代,LeCun等人发表论文,确立了CNN的现代结构,后来又对其进行完善。他们设计了一种多层的人工神经网络,取名叫做LeNet-5,可以对手写数字做分类。和其他神经网络一样, LeNet-5 也能使用反向传播算法训练。 卷积神经网络能够得出原始图像的有效特征,因而其能够直接从原始像素中,经过极少的预处理,识别视觉层面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力不足等因素,卷积神经网络并未得到科学界的重视。 进入21世纪后,随着科学的发展,计算机的计算能力也逐渐得到了巨大的提升,而卷积神经网络的在图像分类问题上的应用也开始逐渐得到人们的重视。ImageNet是被誉为图像分类领域里的奥林匹克比赛,2012年,通过卷积神经网络构建的图像分类算法在这场比赛中脱颖而出,将图像分类识别的准确度一下提升了许多,卷积神经网络,也因此死灰复燃,再次得到了学术界的关注。 此后,卷积神经网络也在不断地被计算机科学家们优化着,出现了诸如GoogLeNet、VGG等较之前更为优秀结构。计算机图像分类能力也因此得到巨大提升,这是这种强大的图像分类、处理能力的诞生,才推动了现代深度增强学习的发展。 卷积神经网络的基本结构一般包括三层,特征提取层,特征映射层,以及全连接层。对特征提取层来讲,每一个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。当该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;对特征映射层来讲,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。最后,还包括一层全连接层。 卷积神经网络主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于卷积神经网络的特征检测层通过训练数据进行学习,所以在使用卷积神经网络时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。 卷积神经网络的三种组成部分:卷积层、池化层,以及全连接层如图2-1所示,该图展示了一个较为完整的卷积神经网络结构图。
卷积层
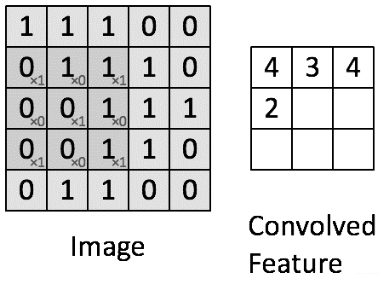
卷积神经网络处理的对象是图片,而图片在计算机上又是以像素值的形式存取的。对于彩色图片来说,通常其具有RGB三个通道,对于灰色通道来讲,其只有一个灰度值通道。当知道了图像每一个像素点的值,我们就能还原出图像的原貌。而卷积神经网络,就是对这些像素值进行处理的,本质上还是进行数值的计算。 图2-2展示了一个简明的卷积计算。左侧方框中,标有0和1的方框是我们的数据,这里,我们将其当作图像像素值,图中较深阴影部分,即为卷积核,卷积核在图像滚动,每滚动一次,计算一次卷积核的值与对应位置像素值的乘积,再相加。得到图片右侧的卷积特征(Convolved Feature)。
池化层
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做,面临计算量的挑战。例如:对于一个 96×96 像素的图像,假设我们已经学习得到了400个定义在8×8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例都会得到一个 892 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。 为了解决这个问题,我们需要对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化。全连接层
为了使我们的卷积神经网络能够起到分类器的作用,一般地,我们需要在卷积神经网络的后面来添加全连接层。如果说卷积层、池化层等操作是将原始数据映射至隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。优化算法与反向传播算法
以梯度下降法为代表的很多优化算法可以用来解决上述的最小化问题。诸如AdamOptimizer,RMSPropOptimizer等优化器,在神经网络框架TensorFlow、Keras中都可以直接调用,本课题中,我们选用AdamOptimizer对神经网络进行优化。 Adam 的全称为Adaptive moment estimation,即自适应矩估计。在概率论中,矩的含义是:如果一个随机变量 X 服从某个分布,X 的一阶矩是E ( X ) E(X)E(X),也就是样本平均值,X 的二阶矩即为E ( X 2 ) E(X^{2})E(X2),也就是样本平方的平均值。Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。Adam 也是基于梯度下降的方法,但是每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定。 在优化过程中,这些算法通常需要求解偏导数。反向传播算法就是用来计算这些偏导数的。 1986年,深度学习之父Hinton,和他的合作者发表了论文Learning Representations by Back-propagating errors, 首次系统地描述了如何利用反向传播算法(Backpropagation)有训练神经网络. 从这一年开始,反向传播算法在有监督的神经网络算法中占着核心地位。它描述了如何利用错误信息,从最后一层(输出层)开始到第一个隐层,逐步调整权值参数,达到学习的目的。 反向传播算法是目前用来训练人工神经网络(ANN)的最常用且最有效的算法。其主要思想是: (1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程; (2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层; (3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。FCN网络结构
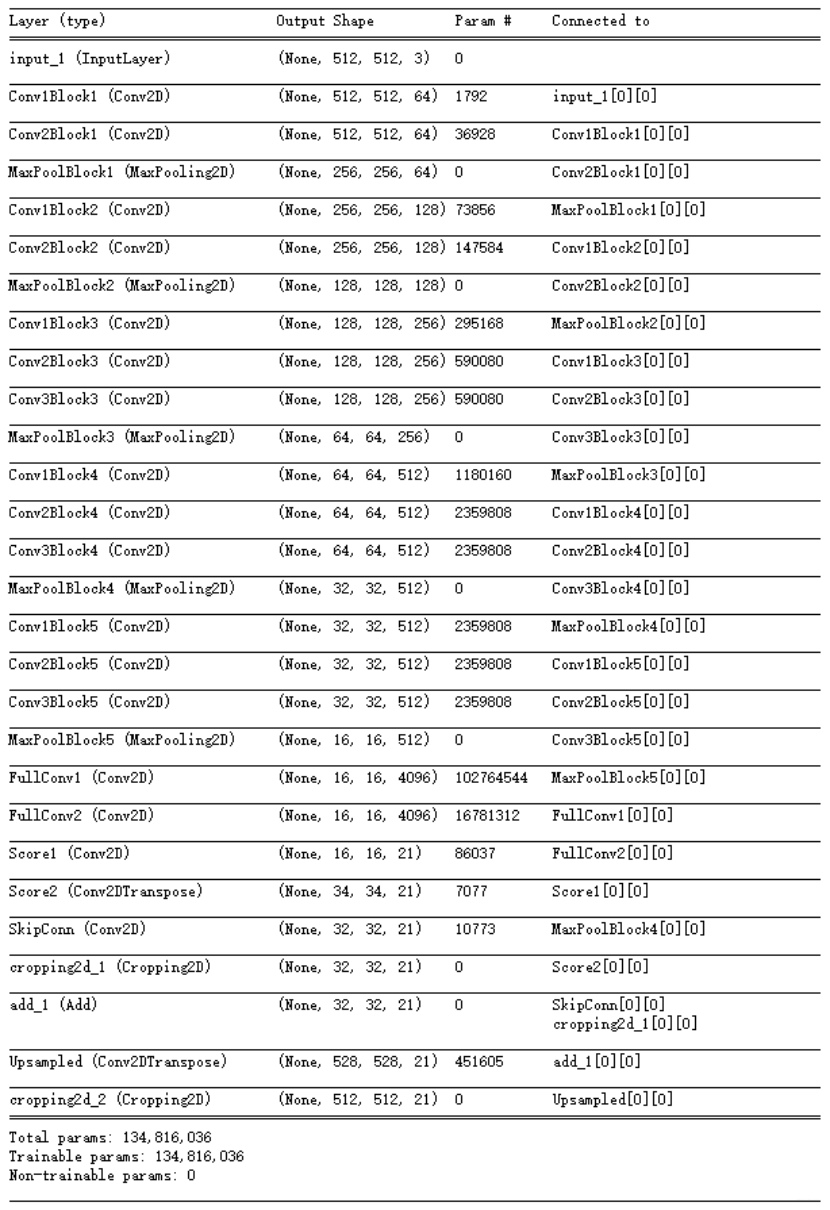
1.image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2 (conv只提特征,pool进行下降操作) 2.pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4 3.pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8 4.pool3 feature再经过多个conv+一个max pooling变为pool4 feature,宽高变为1/16 5.pool4 feature再经过多个conv+一个max pooling变为pool5 feature,宽高变为1/32 直接对pool4 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。FCN网络结构的Python代码解析
对输入图像做卷积,卷积核个数为64个,卷积核大小为(3, 3),过滤的模式为same,做两次这样的卷积,之后为空域信号施加最大值池化,池化窗口大小为(2, 2)将使图片在两个维度上均变为原长的一半,激活函数选择ReLu,得到layer_3:layer_1 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv1Block1')(input_image)
layer_2 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv2Block1')(layer_1)
layer_3 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock1')(layer_2)
layer_4 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv1Block2')(layer_3)
layer_5 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv2Block2')(layer_4)
layer_6 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock2')(layer_5)
layer_7 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv1Block3')(layer_6)
layer_8 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv2Block3')(layer_7)
layer_9 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv3Block3')(layer_8)
layer_10 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock3')(layer_9)
layer_11 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block4')(layer_10)
layer_12 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block4')(layer_11)
layer_13 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block4')(layer_12)
layer_14 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock4')(layer_13)
layer_15 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block5')(layer_14)
layer_16 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block5')(layer_15)
layer_17 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block5')(layer_16)
layer_18 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock5')(layer_17)
#Making the network fully convolutional
layer_19=Convolution2D(4096,kernel_size=(7,7),padding="same",activation="relu",name="FullConv1")(layer_18)
layer_20=Convolution2D(4096,kernel_size=(1,1),padding="same",activation="relu",name="FullConv2")(layer_19)
#For obtaining the semantic segmentation scores
layer_21=Convolution2D(21,kernel_size=(1,1),padding="same",activation="relu",name="Score1")(layer_20)
layer_22 = Deconvolution2D(21,kernel_size=(4,4),strides = (2,2),padding = "valid",activation=None,name = "Score2")(layer_21)
layer_23 = Cropping2D(cropping=((0,2),(0,2)))(layer_22)
skip_con=Convolution2D(21,kernel_size=(1,1),padding="same",activation=None, name="SkipConn")
summed=add(inputs = [skip_con(layer_14),layer_23])
layer_24=Deconvolution2D(21,kernel_size=(32,32),strides=(16,16),padding="valid",activation = None,name = "Upsampled")
crop = Cropping2D(cropping = ((0,16),(0,16)))
model = Model(inputs = input_image, outputs = crop(layer_24(summed)))
model = Model(inputs = input_image, outputs = crop(layer_24(summed)))
model.summary()
model.load_weights("weights.h5")
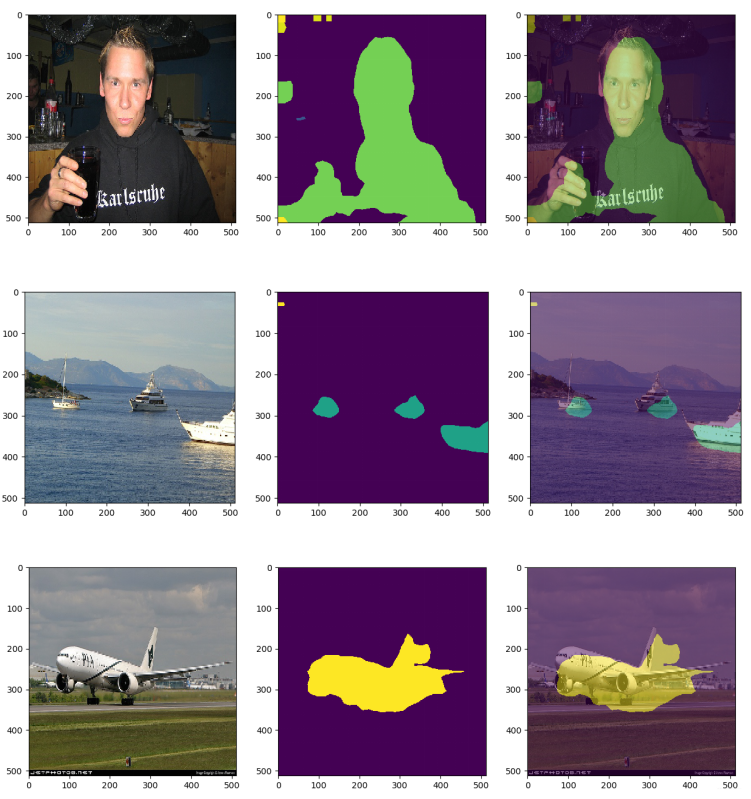
test_image = Image.open('TestingImages/2007_000170.jpg')
test_image = test_image.resize((512,512))
image_arr = np.array(test_image).astype(np.float32)
image_arr = np.expand_dims(image_arr, axis=0)
preds=model.predict(image_arr)
imclass = np.argmax(preds, axis=3)[0,:,:]
plt.figure(figsize = (15, 7))
plt.subplot(1,3,1)
plt.imshow( np.asarray(test_image) )
plt.subplot(1,3,2)
plt.imshow( imclass )
2plt.subplot(1,3,3)
plt.imshow( np.asarray(test_image) )
masked_imclass = np.ma.masked_where(imclass == 0, imclass)
plt.imshow( imclass, alpha=0.5 )
plt.show()
import numpy as np
from keras.models import Model
from keras.layers import Convolution2D, MaxPooling2D, Deconvolution2D, Cropping2D
from keras.layers import Input, add
import matplotlib.pyplot as plt
from PIL import Image
input_image = Input(shape = (512,512,3))
# Block 1
layer_1 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv1Block1')(input_image)
layer_2 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv2Block1')(layer_1)
layer_3 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock1')(layer_2)
# Block 2
layer_4 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv1Block2')(layer_3)
layer_5 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv2Block2')(layer_4)
layer_6 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock2')(layer_5)
#Block 3
layer_7 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv1Block3')(layer_6)
layer_8 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv2Block3')(layer_7)
layer_9 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv3Block3')(layer_8)
layer_10 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock3')(layer_9)
#Block 4
layer_11 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block4')(layer_10)
layer_12 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block4')(layer_11)
layer_13 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block4')(layer_12)
layer_14 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock4')(layer_13)
#Block 5
layer_15 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block5')(layer_14)
layer_16 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block5')(layer_15)
layer_17 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block5')(layer_16)
layer_18 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock5')(layer_17)
#Making the network fully convolutional
layer_19 = Convolution2D(4096,kernel_size=(7,7),padding = "same",activation = "relu",name = "FullConv1")(layer_18)
layer_20 = Convolution2D(4096,kernel_size=(1,1),padding = "same",activation = "relu",name = "FullConv2")(layer_19)
#For obtaining the semantic segmentation scores
layer_21 = Convolution2D(21,kernel_size=(1,1),padding="same",activation="relu",name = "Score1")(layer_20)
layer_22 = Deconvolution2D(21,kernel_size=(4,4),strides = (2,2),padding = "valid",activation=None,name = "Score2")(layer_21)
#Cropping the image to make it compatible for addition
layer_23 = Cropping2D(cropping=((0,2),(0,2)))(layer_22)
#Adding a skip connection
skip_con = Convolution2D(21,kernel_size=(1,1),padding = "same",activation=None, name = "SkipConn")
#Adding the layers
summed = add(inputs = [skip_con(layer_14),layer_23])
#Upsampling the output
layer_24 = Deconvolution2D(21,kernel_size=(32,32),strides = (16,16),padding = "valid",activation = None,name = "Upsampled")
#Cropping the output to match the input size
crop = Cropping2D(cropping = ((0,16),(0,16)))
#Defining the model with the layers
model = Model(inputs = input_image, outputs = crop(layer_24(summed)))
model.summary()
model.load_weights("weights.h5")
test_image = Image.open('TestingImages/2007_000256.jpg')
test_image = test_image.resize((512,512))
image_arr = np.array(test_image).astype(np.float32)
image_arr = np.expand_dims(image_arr, axis=0)
preds=model.predict(image_arr)
imclass = np.argmax(preds, axis=3)[0,:,:]
plt.figure(figsize = (15, 7))
plt.subplot(1,3,1)
plt.imshow( np.asarray(test_image) )
plt.subplot(1,3,2)
plt.imshow( imclass )
plt.subplot(1,3,3)
plt.imshow( np.asarray(test_image) )
masked_imclass = np.ma.masked_where(imclass == 0, imclass)
plt.imshow( imclass, alpha=0.5 )
plt.show()
1.import numpy as np
2.from keras.models import Model
3.from keras.layers import Convolution2D, MaxPooling2D, Deconvolution2D, Cropping2D
4.from keras.layers import Input, add
import matplotlib.pyplot as plt
from PIL import Image
input_image = Input(shape = (512,512,3))
# Block 1
layer_1 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv1Block1')(input_image)
layer_2 = Convolution2D(64, (3, 3), activation='relu', padding='same', name='Conv2Block1')(layer_1)
layer_3 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock1')(layer_2)
# Block 2
layer_4 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv1Block2')(layer_3)
layer_5 = Convolution2D(128, (3, 3), activation='relu', padding='same', name='Conv2Block2')(layer_4)
layer_6 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock2')(layer_5)
#Block 3
layer_7 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv1Block3')(layer_6)
layer_8 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv2Block3')(layer_7)
layer_9 = Convolution2D(256, (3, 3), activation='relu', padding='same', name='Conv3Block3')(layer_8)
layer_10 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock3')(layer_9)
#Block 4
layer_11 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block4')(layer_10)
layer_12 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block4')(layer_11)
layer_13 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block4')(layer_12)
layer_14 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock4')(layer_13)
#Block 5
layer_15 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv1Block5')(layer_14)
layer_16 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv2Block5')(layer_15)
layer_17 = Convolution2D(512, (3, 3), activation='relu', padding='same', name='Conv3Block5')(layer_16)
layer_18 = MaxPooling2D((2, 2), strides=(2, 2), name='MaxPoolBlock5')(layer_17)
#Making the network fully convolutional
layer_19 = Convolution2D(4096,kernel_size=(7,7),padding = "same",activation = "relu",name = "FullConv1")(layer_18)
layer_20 = Convolution2D(4096,kernel_size=(1,1),padding = "same",activation = "relu",name = "FullConv2")(layer_19)
#For obtaining the semantic segmentation scores
layer_21 = Convolution2D(21,kernel_size=(1,1),padding="same",activation="relu",name = "Score1")(layer_20)
layer_22 = Deconvolution2D(21,kernel_size=(4,4),strides = (2,2),padding = "valid",activation=None,name = "Score2")(layer_21)
#Cropping the image to make it compatible for addition
layer_23 = Cropping2D(cropping=((0,2),(0,2)))(layer_22)
#Adding a skip connection
skip_con = Convolution2D(21,kernel_size=(1,1),padding = "same",activation=None, name = "SkipConn")
#Adding the layers
summed = add(inputs = [skip_con(layer_14),layer_23])
#Upsampling the output
layer_24 = Deconvolution2D(21,kernel_size=(32,32),strides = (16,16),padding = "valid",activation = None,name = "Upsampled")
#Cropping the output to match the input size
crop = Cropping2D(cropping = ((0,16),(0,16)))
#Defining the model with the layers
model = Model(inputs = input_image, outputs = crop(layer_24(summed)))
model.summary()
model.load_weights("weights.h5")
test_image = Image.open('TestingImages/2007_000256.jpg')
test_image = test_image.resize((512,512))
image_arr = np.array(test_image).astype(np.float32)
image_arr = np.expand_dims(image_arr, axis=0)
preds=model.predict(image_arr)
imclass = np.argmax(preds, axis=3)[0,:,:]
plt.figure(figsize = (15, 7))
plt.subplot(1,3,1)
plt.imshow( np.asarray(test_image) )
plt.subplot(1,3,2)
plt.imshow( imclass )
plt.subplot(1,3,3)
plt.imshow( np.asarray(test_image) )
masked_imclass = np.ma.masked_where(imclass == 0, imclass)
plt.imshow( imclass, alpha=0.5 )
plt.show()ee



评论(0)
您还未登录,请登录后发表或查看评论