

我眼中的SLAM
从最开始接触SLAM已经3年了,从二维激光SLAM到三维激光SLAM,再到视觉SLAM,都有一些接触,现将简单梳理一下SLAM的各个模块的功能以及实现方式,为本系列文章起到个总领作用。
1 SLAM是什么
SLAM(simultaneous localization and mapping)的中文翻译为 同步定位与地图构建。目的有2个,一个是进行定位,一个是进行周围环境的地图的构建,二者相互依赖,只有同时进行求解才能够解决这个问题。
为什么一定要同时进行求解呢?
人通过眼睛,通过手部等肢体的触摸进行感知,从而了解周围的环境,人的大脑自动的为周围环境进行了模型搭建(地图构建),所以人可以做到闭着眼睛通过感觉拿到水杯等物体。同时,人可以通过眼睛的感知,知道自己的手处于水杯的前方(定位),通过再向前伸手就可以碰到水杯,所以,当人看着水杯的时候,几乎所有人都可以准确的拿到水杯。
机器人想要屋子里进行导航,也是同样的道理。首先通过激光雷达,摄像头等传感器确定了周围环境的地图(地图构建),当机器人向前走了1米,这时候再将周围的环境建成地图,而且要将地图准确地放到之前建的地图的相应位置处(定位)。
定位,是通过将当前传感器感知到的环境信息与构建好的环境地图进行匹配,确定机器人在当前地图中的位置,只有地图准确了,定位才能够准确。
地图构建,通过将当前传感器感知到的环境信息构建成地图,这时的地图是要放到机器人当前位置处的,所以只有定位准确了,构建的地图才能够与真实环境相符合。
所以定位与地图构建,二者相互依赖,必须要同时进行求解才能构建好地图。
2 SLAM的目的或应用是什么
个人认为SLAM最大的应用就是建图,通过SLAM的处理,获得一个能够在之后继续使用的地图。而由于SLAM本身包含了定位,当不保存地图的时候,SLAM也可以当成个定位算法来用。
- 二维激光SLAM构建的二维栅格地图,可以用来做机器人的定位与导航。
- 三维激光SLAM构建的三维点云地图,可以用来做无人车的定位与导航,也可以用来做三维建模。
- 视觉SLAM构建的稀疏点云地图,可以用来做定位。
- 视觉SLAM构建的半稠密与稠密的点云地图,可以用来做定位与导航,也可以用来做VR领域的交互场景,也可以用来做三维建模。
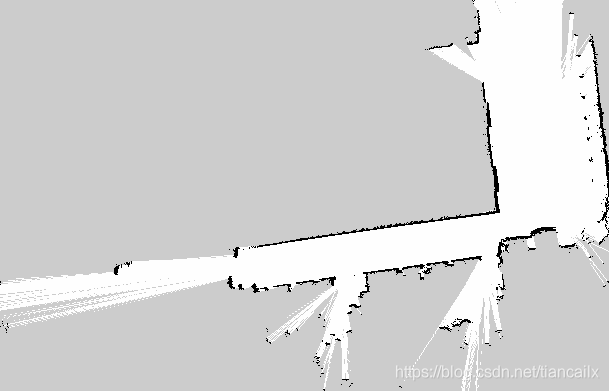
上图为二维激光SLAM构建的二维栅格地图

上图为三维激光SLAM构建的三维点云地图
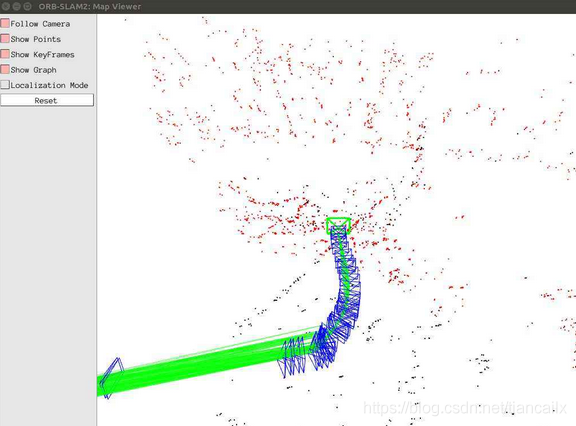
上图为视觉SLAM(ORB-SLAM2)构建的稀疏点云地图

上图为视觉SLAM构建稠密点云地图
3 SLAM的三个模块
众所周知,目前阶段,SLAM的框架大体上已经固定了,分为前端里程计模块,后端优化模块,以及回环检测模块。
接下来,我将简要介绍这三个模块的功能,以及实现每个模块的方法。
3.1 前端里程计
3.1.1 什么是前端里程计
机器人的轮子上有种叫做编码器的传感器,用于测量轮子具体走了多远。前端里程计也是同样的目的,就是为了测量机器人从开始后到现在到底走了多远,与初始位置处的相对距离和相对姿态(位姿)。
3.1.2 怎么实现呢
对于激光SLAM来说,激光雷达的频率一般是10Hz-40Hz之间。我只要确定第一帧雷达数据与第二帧雷达数据的时间间隔内,机器人走了多远,再确定第二帧到第三帧雷达数据的时间间隔内,机器人走了多远(位姿变换),依次类推,我们就可以一直确定机器人到底走了多远,确定机器人当前的位姿与初始时刻的相对位姿。
对于视觉SLAM来说,摄像头的数据是一帧一帧的图像,可能是RGB彩色图像,也可能是彩色图像加上深度图像。一般的处理方法为在图像中提取特征点,然后确定特征点在空间中的坐标值,通过这些特征点,确定机器人在2帧图像间的位姿变换,再确定第二帧图像与第三帧图像间的位姿变换,依次类推,就可以确定了机器人当前的位姿与初始时刻的相对位姿。
上述过程确定了机器人相对于初始时刻以及相对于每帧数据到来时的位姿变换,这个过程就是定位的过程。
3.1.3 具体实现方法
对于激光SLAM来说,求从前一帧雷达数据到当前帧雷达数据间的位姿变换,一般将这个过程称为 扫描匹配(scan-matching) 过程。scan就是雷达的数据,通过与前一帧数据进行匹配,从而确定处位姿变换。
目前的扫描匹配方法为:
- scan-to-scan:雷达数据与雷达数据进行匹配
- scan-to-map:雷达数据与地图进行匹配
- scan-to-submap:雷达数据与子地图进行匹配
- map-to-map:地图与地图进行匹配
对于视觉SLAM来说,求从前一帧图像到当前帧图像间的位姿变换,一般将这个过程称为 BA(Bundle Adjustment),求解BA的方法有很多,由于目前我对视觉SLAM了解不多,不在这里进行更多的说明。
3.2 后端优化
3.2.1 为什么需要后端优化
不管是使用编码器得到的里程计,还是前端计算出来的里程计,都不是完全准确的。
即使选用的编码器十分精确,当轮子在光滑的地面上出现打滑时(数据比实际值偏大)或者在轮子路过了一个坑或者土包时,都会导致里程计的测量值与实际值不匹配。
同样的,由于所有传感器都是存在误差的,我们通过前端里程计计算出来的里程计数值也一定是存在误差的,而且这个误差将随着时间的增长而不断增大。
这将导致机器人的位置与实际的位置相差的越来越大,最终导致机器人的位置与真实的位置不符,不能构建很好的地图。
3.2.2 什么是后端优化
由于前端里程计会有累计误差,那有没有一种方法可以将这种累计误差减小甚至消除掉呢?
这就是后端优化的作用,通过图结构,将机器人的各个位姿以及生成的地图数据,进行联合优化,通过优化求解,将所有的误差平均分散到每个机器人位姿以及每个地图数据上去,当我的优化过程十分完美的时候,这些累计误差可以减小到可以忽略的地步。
对于激光SLAM与视觉SLAM,他们的后端优化过程都是差不多的,都是通过图结构来减小误差,只不过由于传感器的数据类型不同,具体的实现方法也不完全相同。
3.3 回环检测
我们可以通过后端优化来减小位姿,那么,有没有一种比较强的约束来对优化的方程进行约束呢?
答案肯定是存在的,那就是回环检测。
当我们人类从公园的东门出发,转了10分钟之后再回到东门,我们可以轻而易举的分辨出这就是之前我来过的地点,和之前的东门是同一个东门。
但是,对于机器人而言,同样从东门出发,走了10分钟。由于机器人的位姿是通过逐步累加得到的,这样的计算存在累计误差,当机器人再次回到东门时,有可能机器人认为自己还和东门差距20米。这20米就是机器人由于长时间定位产生的偏差。
我们可以通过某种手段,将当前传感器感知的环境信息,与机器人之前构建的地图相对比,如果匹配程度很高,则我们认为,机器人到了一个之前去过的地方,那么当前的位置应该与之前路过这个位置时相距不会太远(约束)。
我们可以将这个约束,输入到后端优化过程中,当做一个新的并且十分强烈的约束,通过这个强烈的约束,当我们进行优化完成后,能够大幅度的进行误差的消除。
4 SLAM的发展
4.1 高精确度地图
这是目前学术研究的重点,很多的工作量都是为了如何构建更准确,更精确的地图。
4.2 长期环境下的建图
人们接触的环境从来没有一成不变的,但是我们每次进行SLAM保存的地图都是不会再变换的,如何在不占资源的情况下,一边运行着导航任务,一边将之前的地图进行更新,也是一个研究重点。目前已经有几家公司可以做到。
4.3 减小计算量
目前的各个SLAM算法都有着不小的计算量,如果要是能够实时运行稠密地图的构建,那么将会把VR领域抬到一个新的高峰。这也是我一直关注这VR领域的原因。
4.4 语义SLAM
人们可以通过眼睛来感知环境的同时,识别出能看到的物体的名字与种类。语义SLAM同样可以做到这样,具有语义标签的环境地图将会对导航产生更大的帮助。
4.5 感知代替SLAM
当机器人的理解能力逐步提升,我们就不需要再去单纯地构建地图,机器人所见即可为一个地图,像人一样的感知周围环境,即可确定自身位置,这就不再需要去保存地图。
总结
本文将我自己理解的激光SLAM与视觉SLAM进行简单说明,由于认知有限,如有错误请见谅,并于评论中告知,十分感谢。
下篇文章将简要介绍本系列文章写的主要方向与要实现的功能。
文章将在 公众号: 从零开始搭SLAM 进行同步更新,欢迎大家关注。



评论(0)
您还未登录,请登录后发表或查看评论