

一、强化学习描述
1. 算法定义
强化学习算法是在不确定环境中,通过与环境的不断交互,来不断优化自身策略的算法。
2. 算法特点
- 数据是序列分布而非独立同分布
- agent的行为会影响后续的数据分布
- 没有supervisor,仅仅是每幕最后的reword
- 无法立即获得反馈,feedback是延迟的
整个过程是一个序列,比如金融投资,比如控制机器人移动等。整个决策序列最终是要实现综合的reward最大化。无法确定当前的每一步action,是否会在未来的某个时刻给你带来巨大的正向reward。在经过算法训练之后,可能出现牺牲当前的即时reward来谋取未来的长远reward.
强化学习问题定义在马尔可夫决策过程之上。一个MDP是 < S , A , R , P , γ > <S,A,R,P,\gamma> <S,A,R,P,γ>的五元组。
关于马尔可夫决策模型,我们详细参见博客:link
3. 关于reward
特点
- R t R_t Rt是可以量化的回馈信号
- 表示agent在该时刻动作的好坏
- agent的任务是最大化累计reward
意义
整个强化学习的基础就是reward hypothesis
当前所有的强化学习研究目标,最终都可以用最大化期望累计reward来表示。
4. 关于state
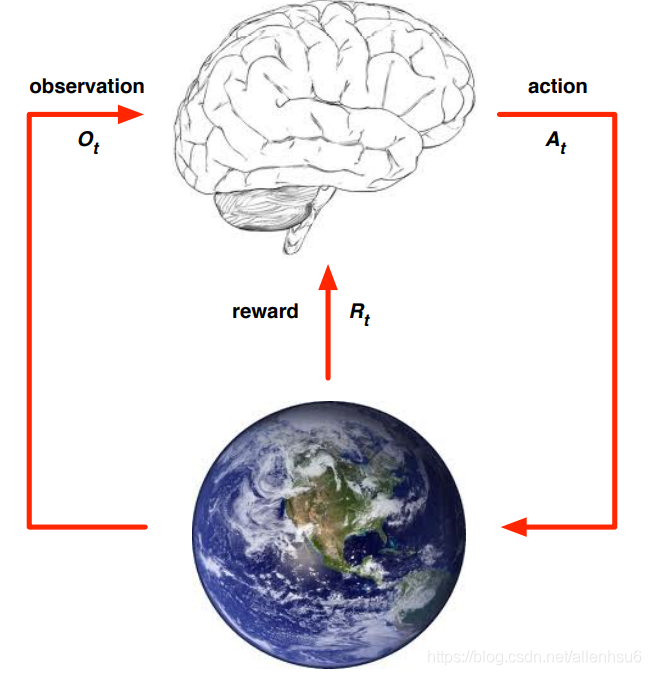
agent依据当前环境的观测 O t O_t Ot + 当前的reward R t R_t Rt,选择action A t A_t At去执行.
环境可以当作是互相博弈的另外一个agent,当 A t A_t At发生后,环境的state会变化,生成新的 O t + 1 O_{t+1} Ot+1、 R t + 1 R_{t+1} Rt+1
state用来表示整个系统当前情况,包括过去发生的所有History,我们分别看下环境和agent的state变化。
对于一辆在路上行驶的车而言,在RL的世界,车本身属于agent,周围所有的其他车,人,建筑物都属于环境。
state通常可以用马尔可夫性进行处理。
4.1 environment state
- 环境提供的observation与reward的信息的数据表示
- 环境的state有时并不是agent可见的
- 即使 S t e S_t^e Ste对agent可见,其中也包含一些不相关或噪声信息
环境state没那么重要。相反,机器人本身观测到的环境状态才是最重要的。
4.2 agent state
- S t a S^a_t Sta是agent内部状态的表示
- agent选择用于action的信息
- 用于强化学习算法的一些信息
- 是基于历史information的一个函数 S t a = f ( H t ) S^a_t=f(H_t) Sta=f(Ht)
这个agent state才是最重要的。而且,我们到底如何model来实现最优的对环境state的表征,这件事情很难。也就是上述公式中的 f f f很难找到最好的符合agent需求的形式。
5. 关于观测
5.1 Fully Observable Environments
O t = S t a = S t e O_t=S^a_t=S^e_t Ot=Sta=Ste
通常这是一个MDP的过程。如上说述,state的表征很重要,MDP在这里能够发挥巨大的作用。
5.2 Partially Observable Environments
ange必须自己构建属于自己的 S t a S^a_t Sta,通常有如下的构建方法:
- 直接用历史数据(历史是已经发生的,是确定的): S t a = H t = O 1 , R 1 , A 1 , . . . , A t − 1 , O t , R t S^a_t=H_t = O_1,R_1,A_1,...,A_{t-1},O_t,R_t Sta=Ht=O1,R1,A1,...,At−1,Ot,Rt
- 使用环境的状态的置信度belief表示: S t a = ( P [ S t e = s 1 ] , . . . , P [ S t e = s n ] ) S^a_t = (P[S^e_t=s^1],...,P[S^e_t=s^n]) Sta=(P[Ste=s1],...,P[Ste=sn])
- RNN网络: S t a = σ ( S t − 1 a W s + O t W o ) S^a_t=\sigma(S^a_{t-1}W_s+O_tW_o) Sta=σ(St−1aWs+OtWo)
二、强化学习中智能体的组成部分
第一部分的内容,我们还停留在强化学习的定义上。还在说明强化学习这个武器是怎样与现实生活中的应用场景进行配对的。这部分,我们来深入agent,思考面对建立好的强化学习,agent如何来解决问题。
Agent中可能有的三大组成部分:
- Policy:智能体决策函数
- Value Function:智能体action评价函数
- Model:智能体对环境的建模
注意: 三个部分通常不是必须都要有。
1. policy
策略通常用 π \pi π来表示,用来表征从state到action的函数映射
a = π ( s ) a=\pi(s) a=π(s)
如果用概率语言来描述的话:
π ( a ∣ s ) = p [ A t = a ∣ S t = s ] \pi(a|s)=p[A_t=a|S_t=s] π(a∣s)=p[At=a∣St=s]
2. Value Function
用于评价如果选择不同的action可能对应的不同state的好坏,从而依据状态来选择action. 本质上是在评价选取的策略的好坏。通过尽量把目光放长远来实现最优评价。
可以用如下公式描述:
v π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . ∣ S t = s ] v_{\pi}(s)=E_{\pi}[R_{t+1} +\gamma R_{t+2}+\gamma ^2R_{t+3}+...|S_t=s] vπ(s)=Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]
上述公式可以用文字表述:
基于当前状态 S t S_t St,我们来判断如果选择policy π \pi π的话,可能获得的reward的总和。
具体的,我们可以将value function分别对应到state和action上,分别描述当前的state可能对应的value,以及具体采取某种action后对应的value.
需要注意的是,value function关注的总是future.
3. model
模型用来预测agent接下来的状态。其实就是对环境状态的观测 S t a S^a_t Sta,它反映了从机器人视角出发的在进行action之后,env做出的回馈。用于机器人生成下一次的策略 π \pi π。
比如agent是飞机,model通过分析当前的飞机速度朝向,周围环境的风向等因素,判断下一时刻飞机可能的state.
P P P表示下一个机器人的状态:
P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P^a_{ss'}=P[S_{t+1}=s'|S_t=s,A_t=a] Pss′a=P[St+1=s′∣St=s,At=a]
R表示下一个状态的对应奖励
R s a = E [ R t + 1 ∣ S t = s , A t = a ] R^a_s=E[R_{t+1}|S_t=s,A_t=a] Rsa=E[Rt+1∣St=s,At=a]
三、强化学习的分类
第二节中,我们详细说明了agent可能有的三大模块:policy,value function,model
依据agent这三部分的有与无,我们可以将强化学习的各类方法做一些大致分类。
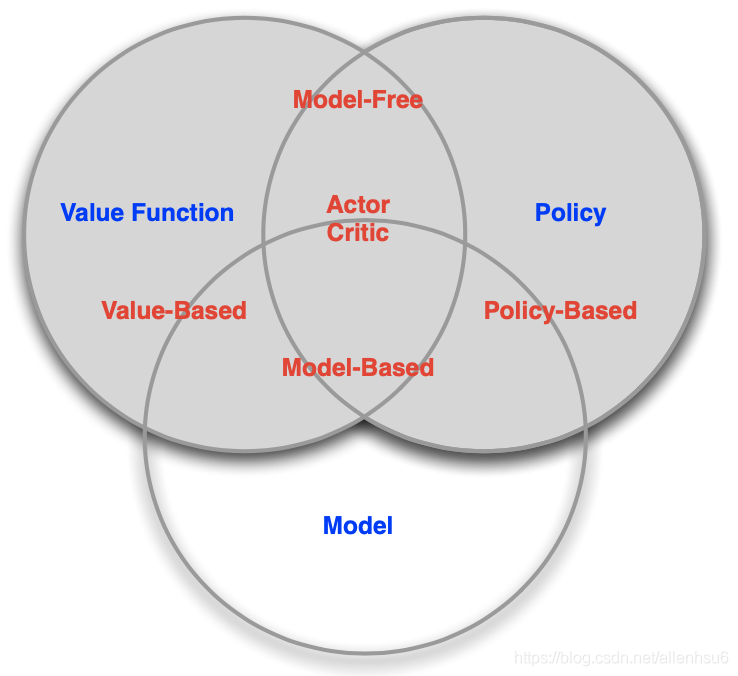
1. value or policy
-
基于value的RL
表征agent内部state or action的value function.
必须包含着value function,policy可有可无 -
基于policy的RL
-
actor critic
既有value 也有policy
2. model or model free
model free 表示我们并不是通过建立model来理解环境。而是直接建立policy或者value function来分析理解环境。
model based 的RL, 首先第一步需要建立对整个环境的model,用于说明环境的工作原理。
四、强化学习中的问题
1. learning and planning

learning问题,首先,在最开始的时候,环境对于agent而言是完全陌生的,agent需要不断与环境进行交互,不断了解、认识、与环境交互来提高policy的效果。
planning(规划)问题,环境的模型对agent是已知的,不变的。我们总是能准确get采取action后对应的环境状态,这其中就没有交互。就可以在第一步实现对整个全局的推演。
2. exploration vs exploitation
举例:

如何平衡EE是强化学习中的重要问题。
3. prediction and control
prediction:给出一个policy
control:在policy中寻找一个最优秀的
个人理解,control对应着value function,prediction对应着policy的生成。



评论(0)
您还未登录,请登录后发表或查看评论