


之前的文章介绍过卡尔曼滤波算法进行定位,我们知道kalman算法适合用于线性的高斯分布的状态环境中,我们也介绍了EKF,来解决在非高斯和非线性环境下的机器人定位算法。但是他们在现实应用中存在计算量,内存消耗上不是很高效。这就引出了MCL算法。
粒子滤波很粗浅的说就是一开始在地图空间很均匀的撒一把粒子,然后通过获取机器人的motion来移动粒子,比如机器人向前移动了一米,所有的粒子也就向前移动一米,不管现在这个粒子的位置对不对。使用每个粒子所处位置模拟一个传感器信息跟观察到的传感器信息(一般是激光)作对比,从而赋给每个粒子一个概率。之后根据生成的概率来重新生成粒子,概率越高的生成的概率越大。这样的迭代之后,所有的粒子会慢慢地收敛到一起,机器人的确切位置也就被推算出来了
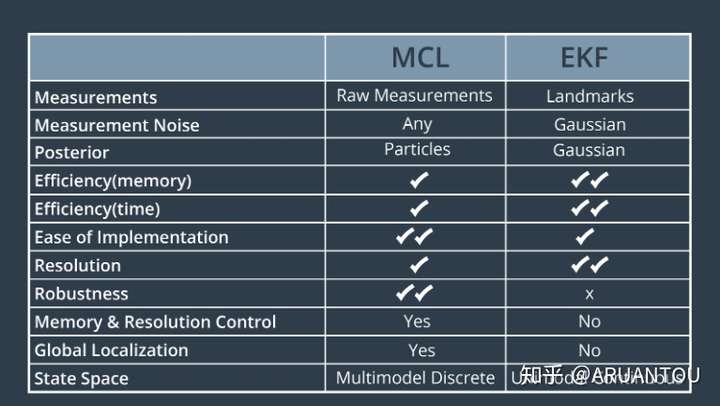
MCL VS EKF
MCL的计算步骤:
1. Randomly generate a bunch of particles
Particles can have position, heading, and/or whatever other state variable you need to estimate. Each has a weight (probability) indicating how likely it matches the actual state of the system. Initialize each with the same weight.
2. Predict next state of the particles
Move the particles based on how you predict the real system is behaving.
3. Update
Update the weighting of the particles based on the measurement. Particles that closely match the measurements are weighted higher than particles which don't match the measurements very well.
4. Resample
Discard highly improbable particle and replace them with copies of the more probable particles.
5. Compute Estimate
Optionally, compute weighted mean and covariance of the set of particles to get a state estimate.
粒子滤波的基本步骤为上面所述的5步,其本质是使用一组有限的加权随机样本(粒子)来近似表征任意状态的后验概率密度。粒子滤波的优势在于对复杂问题的求解上,比如高度的非线性、非高斯动态系统的状态递推估计或概率推理问题。
伪代码:

具体分析下这5步:
第一步:随机生成M个粒子(这些粒子都是有算计的方向和位置)
第二步:根据小车的运动参数(里程计,速度等)来估算每一个粒子基于 的
的预测位置。这里的预测与KF的算法相同。
第三步:根据传感器的测量数据,计算出每一个粒子的权重。(权重计算方式有很多,简单的理解可以认为是和真实传感器测量值之间的差别大小,比如说当前的一个例子的预测位置和测量目标之前的距离和 差别大, 越大权重越小,小的权重说明距离真实的位置)。随后更新每一个粒子的状态。
第四步:重采样,从所有粒子中根据新的权重值获取M个粒子。
之后不断重复上面的4步来实现定位的效果。
通过一个实例来感觉下:
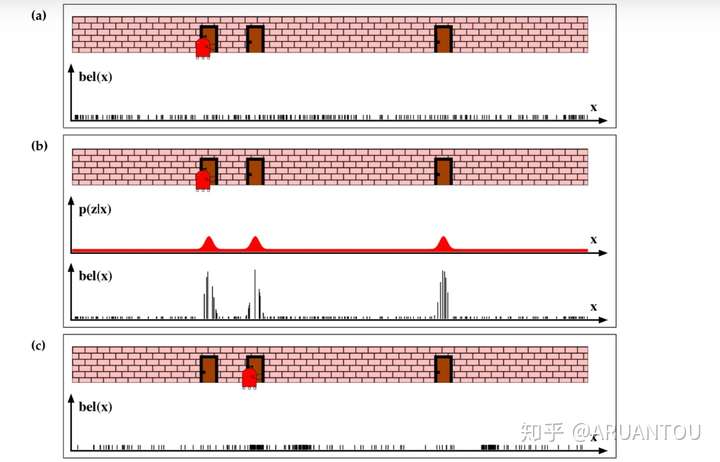
a)图, 我们看到机器人初始在一个门的位置,但是这时候机器人并不知道它自己在哪,这时候我们初始化所有的粒子,并且所有粒子的权重都是一样的。
b)图,这时候机器人通过传感器得知面前是一个门,这时候可以看到和门比较近的粒子的权重都提高了。
c)图,进行重采样之后,机器人移动后,我们可以看到采样后的粒子都集中在原来靠近门的这些粒子点。就是图中黑色密集的位置。
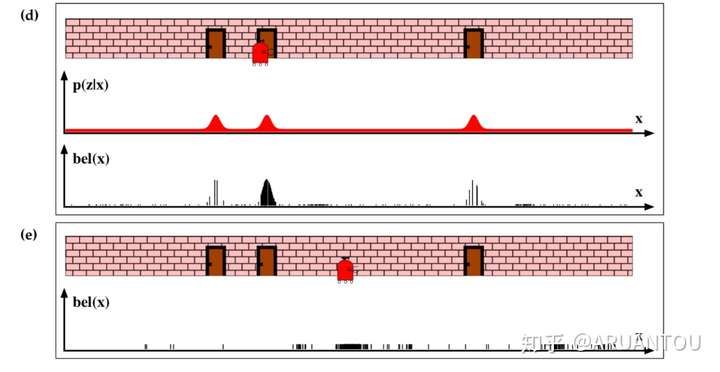
继续看D)图,这时候机器人重新感知,得知面前还是一个门,这时候,原来采样的靠近门的粒子权重变大。从图中已经看到主要的采样点已经集中在第二个门的位置了,机器人现在就知道自己的位置是在第二个门了。
之后在e)图中,冲采样,再次移动机器人,就可以知道机器人这次移动到的位置在中间了。
最后看下实例图,感受下粒子滤波的定位:
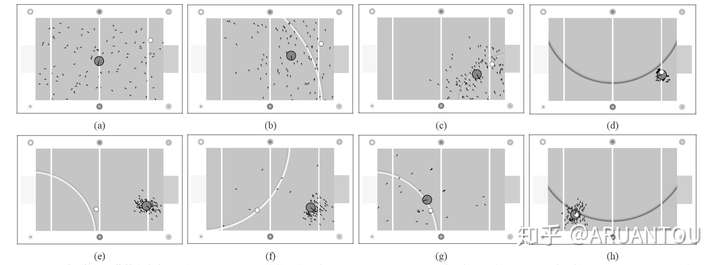
重采样的方式有很多,计算权重的方式也是,这里就不多介绍了,可以google!!



评论(0)
您还未登录,请登录后发表或查看评论