

权重的初始值
在神经网络的学习中,权重的初始值特别重要。设定什么样的权重初始值,经常关系到神经网络的学习能否成功。
将权重初始值设为0的话,将无法正确进行学习。为什么不能将权重初始值设成一样的值呢?这是因为在误差反向传播法中,所有的权重值都会进行相同的更新。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值。
反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
各层的激活值的分布都要求有适当的广度。为什么呢?因为通过在各层间传递多样性的数据,神经网络可以进行高效的学习。反过来,如果传递的是有所偏向的数据,就会出现梯度消失或者“表现力受限”的问题,导致学习可能无法顺利进行。
Batch Normalization
Batch Norm有以下优点:
• 可以使学习快速进行(可以增大学习率)。
• 不那么依赖初始值(对于初始值不用那么敏感)。
• 抑制过拟合(降低Dropout等的必要性)。
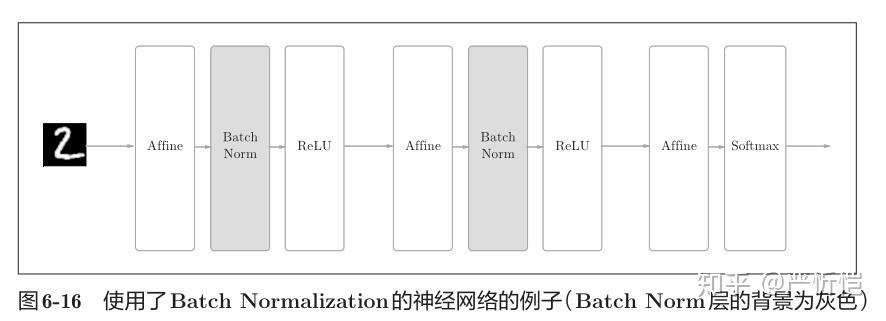
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即BatchNormalization层(下文简称Batch Norm层),如图6-16所示。
用数学式表示的话,如下所示。
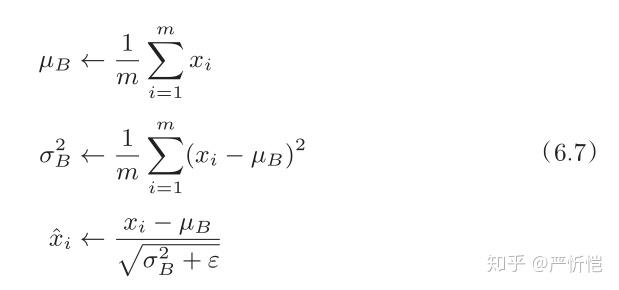
式(6.7)所做的是将mini-batch的输入数据变换为均值为0、方差为1的数据,通过将这个处理插入到激活函数的前面(或者后面),可以减小数据分布的偏向。
接着,Batch Norm层会对正规化后的数据进行缩放和平移的变换,用数学式可以如下表示。
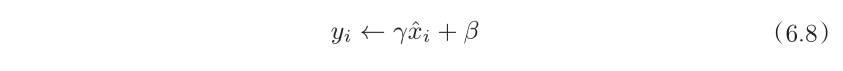
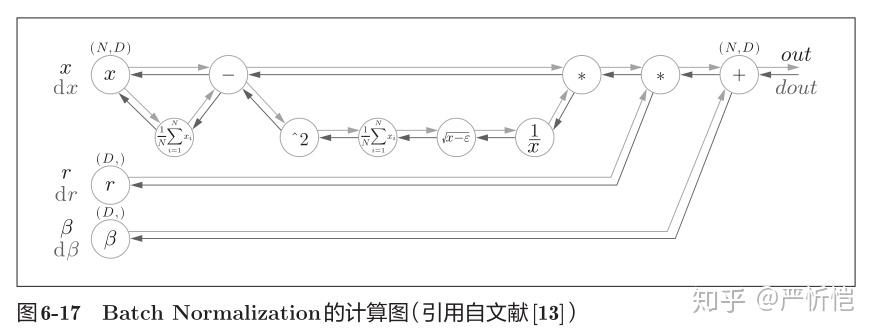
上面就是Batch Norm的算法。这个算法是神经网络上的正向传播。如果使用第5章介绍的计算图,Batch Norm可以表示为图6-17。
使用MNIST数据集观察使用Batch Norm层和不使用Batch Norm层时学习的过程会如何变化,结果如图6-18所示。
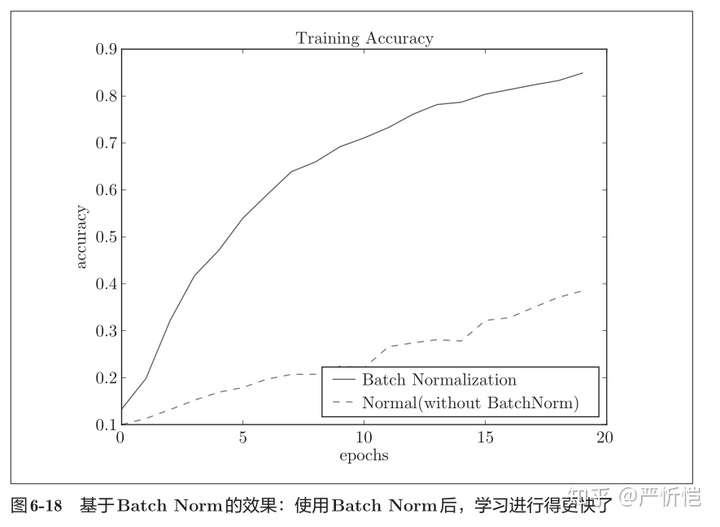
从图6-18的结果可知,使用Batch Norm后,学习进行得更快了。接着,给予不同的初始值尺度,观察学习的过程如何变化。图6-19是权重初始值的标准差为各种不同的值时的学习过程图。
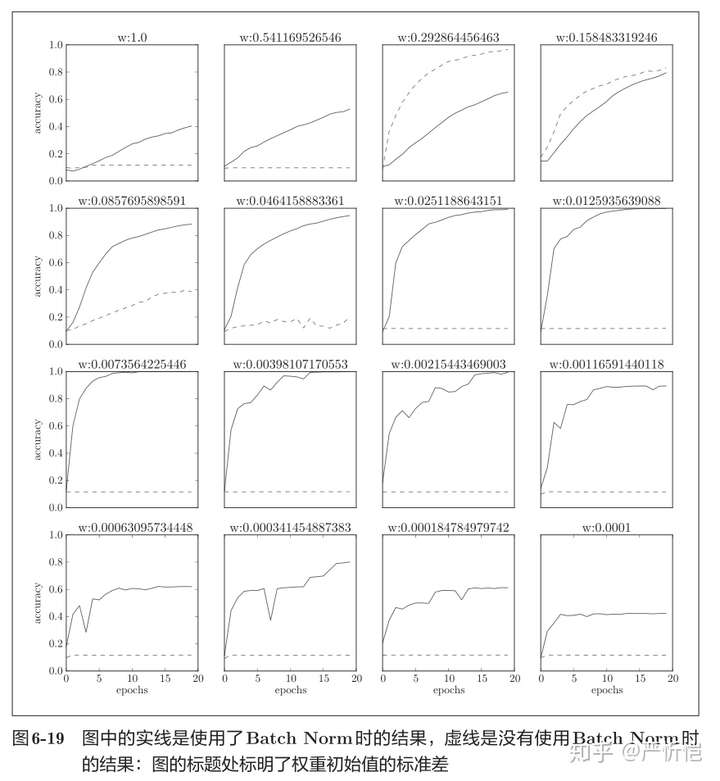
我们发现,几乎所有的情况下都是使用Batch Norm时学习进行得更快。同时也可以发现,实际上,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。综上,通过使用Batch Norm,可以推动学习的进行。并且,对权重初始值变得健壮(“对初始值健壮”表示不那么依赖初始值)。



评论(0)
您还未登录,请登录后发表或查看评论