

1. 概述
这次我们一起讨论SuperPoint系列文章的第二篇Toward Geometric Deep SLAM,这篇文章延续了作者清晰的写作思路,读起来很顺畅。
本文是针对SLAM设计的基于深度学习的特征提取方法,主要包括两部分,一是特征点提取网络MagicPoint,二是基于提取的特征点进行位姿估计的网络MagicWarp。特别指出的是,改方法不需要学习描述子,而只提取特征点位置。由于训练网络需要图片之间真实的位姿,作者设计了一个虚拟三维物体的库,通过模拟不同视角并截取相应的图片,得到了所需要的数据集。最终的结果显示MagicPoint在提取特征方面相比于传统方法更具鲁棒性,MagicWarp在位姿估计方面具有更高精度。
2. 算法流程
算法的整体流程如下图所示
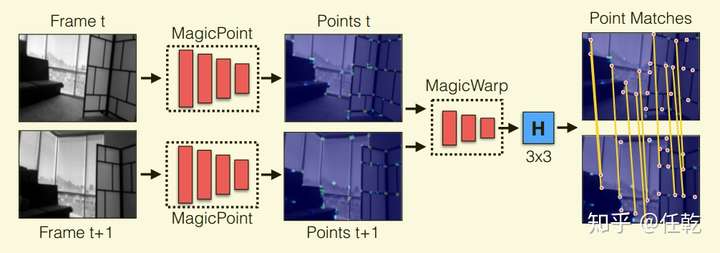
从图中可以看出,该方法首先对两张图片分别使用MagicPoint提取特征点,然后使用MagicWarp把提取的特征点作为输入,对两张图片进行位姿的估计,直接输出一个3X3的转换矩阵。
2.1 MagicPoint网络
MagicPoint的网络结构如下图所示

网络输入的是一张黑白图片,输出的是每个像素为特征点的概率值,所有概率值显示在这张图片上形成热度图,识别出的特征点就是相比于周围的点就会是明显的红色。
MagicPoint的训练数据集是通过虚拟出一些三维物体,然后再对这些物体进行一个视角的图片截取获得的,如下图所示。

这种情况下,所有特征点的真值就是已知的,有了明确的特征点位置,便可以进行网络训练。为了增强其泛化能力,作者还在图片中人为添加了一些噪声和不具有特征点的形状,比如椭圆等。
2.2 MagicWarp
MagicWarp的网络结构如下图所示
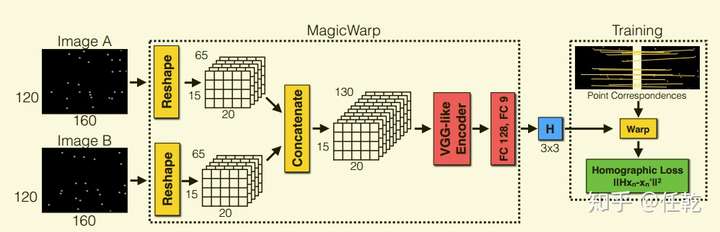
该网络输入的是MagicPoint已经提取过特征点的图片,输出的就是两张图片的相对位姿。同样的,为了使网络能够训练,需要知道真实的相对位姿,作者先按一定角度旋转虚拟的三维物体,并截取对应视角下的图片,这时截取的图片之间的相对位姿就是已知的,网络也就可以训练了。
网络的损失函数如下
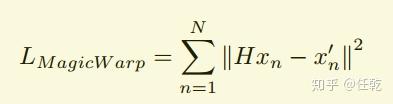
其实就是把一张图片中的特征点投影到另一张图片上,计算其在另一张图片上距离对应的特征点的距离,距离越小,说明转换矩阵H越精确。
3. 实验结果
本文提出了两个网络,这两个网络实际上是相互独立的,所以实验结果自然也就对应的包括两部分,分别是MagicPoint的精度评价和MagicWarp的精度评价。
3.1 MagicPoint精度评价
要评价自然需要先建立一个可以定量表示的指标,本文MagicPoint的指标建立包含两步,第一步如下
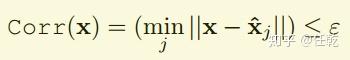
这个公式的意义是先对图片提取特征点,然后针对其中的一个特征点,找到真实特征点中距离其最近的那个点,如果两点之间的距离小于 ,则说明这个点是真实的特征点,此时Corr(X)的值就是1,否则就是0。进一步,如果对提取出的每个特征点提取都做一次这样的运算,不就可以定量评价了吗?不过要注意的是,为了评价指标的统一需要归一化,就是要把计算出的值除以特征点个数,这样这个指标就永远限制在0和
之间。具体式子如下(也即第二步)
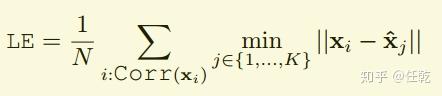
实验测试结果如下

其中mAP代表的是平均预测精度,数值越大越好,MLE代表的是平均定位误差,数值越小越好。可见MagicPoint相比于传统算法精度还是提高不少。
3.2 MagicWarp精度评价
MagicWarp的精度评价指标的计算也是包含两个步骤,其中第一步如下
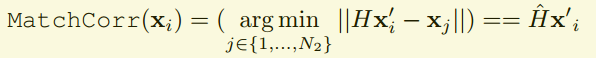
该公式表示的是,在网络输入的两张图片中,按照网络预测出的变换矩阵H,把一张图片中的特征点投影到另一张图片中去,看其在另一张图片中是否能找到对应的特征点。
第二步如下
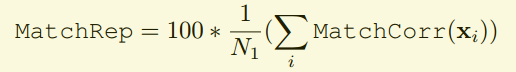
这是对第一步提取的结果进行归一化,把指标限制在0~100的范围内,即输出的就是一个表示正确概率的百分比值。
为了显示效果,作者把特征点最近邻方法得到的匹配结果用来对比(因为没有描述子,所以只能用最近邻了),而且做了可视化对比,如下图所示

从左往右数,图片里左边一列是特征点,第二列是最近邻方法得到的特征点对,第三列是MagicWarp输出的位姿对应的特征点对匹配效果,第四列是真值,第五列是一个改进的MagicWarp,论文里有讲,此处不详细介绍。从结果上可以看出,MagicWarp还是能够给出精确的匹配结果。
4. 总结与思考
作者提出了用于特征点提取的网络MagicPoint和用于位姿匹配的网络MagicWarp,分别与传统方法做了对比,性能上具有明显的优势。特别的,为了训练网络,作者使用了虚拟三维物体模型生成数据集。
一些思考:
为啥只得到旋转矩阵H,而不直接训练网络同时输出旋转和平移?



评论(0)
您还未登录,请登录后发表或查看评论