

文章目录
深度学习图像分类(十):ResNeXt,ResNest...
前言
一、ResNeXt
1. Motivation
2. Model Architecture
3. Why it works?
二、ResNeSt
1. SKNet
2. ResNet 与 ResNeSt
总结
前言
由于ResNet在神经网络里的地位实在是无可撼动,其paper引用量在CV界位居第一。
因此,基于ResNet也有很多变体,单单其变种就有几十种,其中最知名的当属ResNeXt, SENet, GENet, SKNet,CBAM等等。其中尤以ResNeXt, SENet与SKNet最为人知。而亚马逊出品的这篇ResNeSt一经开源同样引起了不小的轰动。 这个博文的目的就是介绍这些变体,这将会是一个持续更新的博文
另外,有很多经典的网络也是受到ResNet的启发提出的,比如DenseNet,又或是FractalNet等等
一、ResNeXt
1. Motivation
问题背景:
传统的提高模型的准确率时,都是加深或加宽网络,但是随着超参数数量的增加(人为设定调节的参数,比如channels数,filter size等等),调参难度、网络设计难度和计算开销也会增加,超参数很多时很难保证每个超参数最优。
网络超参数的针对性比较强(特定数据集需要的超参往往不一样),当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
ResNeXt要在提高准确率的同时,基本不改变或降低模型的复杂度,同时还减少了超参数的数量。使用的方法是分组卷积,关于分组卷积我在MobileNet系列文章中有详细讲解(传送门)关于如何减少参数量请移步上述链接,下面将在第三小节解释一下分组卷积的有效性。
ResNeXt的可扩展性更强,更简单、更模块化、超参数更少,相同参数下的结果更好,ResNeXt-101的准确度相当于ResNet-200的,而且计算量减半。
2. Model Architecture
非常的简单:将resnet中3*3的卷积,替换为分组卷积。然后就没有了。。。。
说实话就这个点换我是发不出来paper的,可见讲好故事有多重要。
论文里增加了一个cardinality的概念(就是group),并讨论了相较于增加网络的宽度和深度,简单的增加group会更好。一句话就是,split-transform-merge。
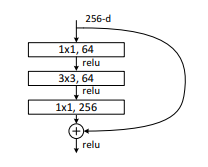
上图是正常的残差快;下图是ResNeXt的残差块。可以看出ResNeXt先对1X1的卷积进行了一个分组(groups=32);注意:ResNeXt残差块经过第一个1X1卷积后的维度是32X4=128,相比原始残差块64的维度来说,是有一个上升的。由于分组卷积可以减少很多参数量,所有这里即便维度上升了,总参数量也是下降的。
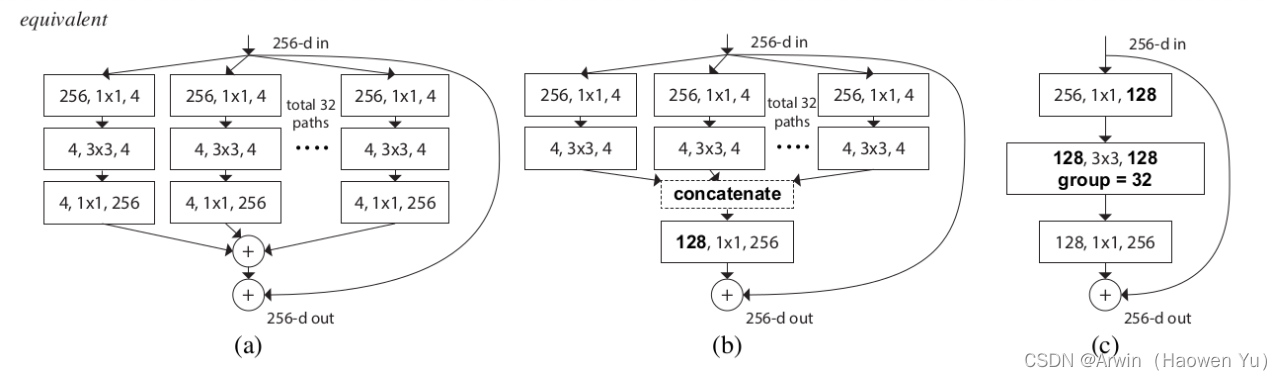
ResNeXt结合了inception与resnet的优点,大家看上图就可以发现,renest优点值得自然就是残差链接;至于inception指的是多个特征图融合,值得注意的是inception里由于多个特征图是由多个不同尺寸的卷积核得到了,因此很容易就可以让人联想到它的意义----多尺度特征图的融合。那么,ResNeXt中的多个拼接的特征图是由 相同尺寸 的卷积核得到了,它的意义又是什么?见下一小节详解
值得注意的是,上图其实本来想说的事情是这三个小图中的操作产生的的作用是等效的:详细说,图(a)是先分组卷积再相加(add),最后加上残差链接;图(b)是先分组,再拼接(concat),再通过1X1卷积升维,最后再加上残差链接; 图(c)是先1X1升维,再分组卷积,再1X1升维。因此,在工程实践上直接采用最简单的(c)方式实现。
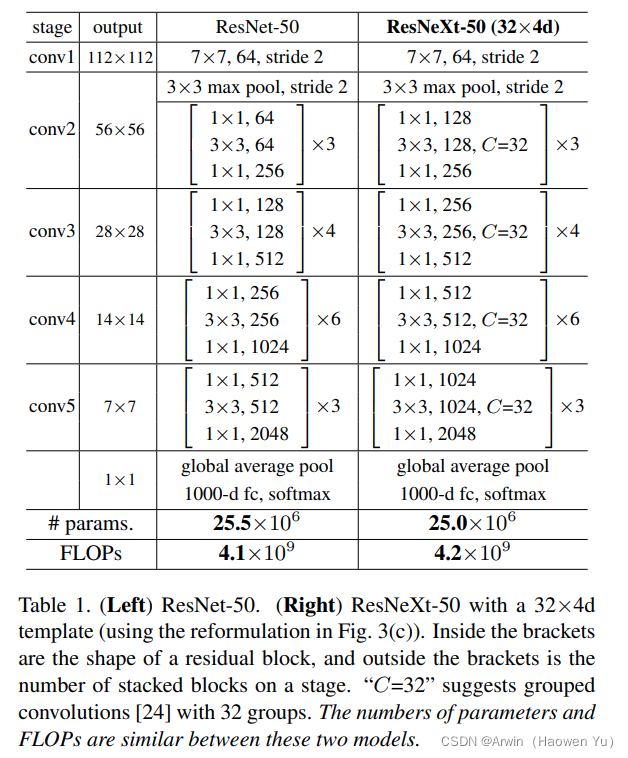
这里给出ResNeXt的详细网络结构如图:
3. Why it works?
ResNext中引入cardinality,实际上仍然还是一个Group的概念。想探究ResNeXt奏效的原因,其实就要思考分组卷积的奏效原因了。
众所周知,在卷积的过程中设计多个卷积核的作用是期望每个卷积核能够学到feature map里的不同特征。类比一下人类,我们在思考问题的时候,最好从多个角度思考;同理,在卷积核提取特征时,我们也希望可以从不同的角度提取特征(多个卷积核就是多个不同的角度)。为啥讲这个?因为分组卷积其实就是在更低的维度里做这件事情。
不同的组之间实际上是不同的subspace,而他们的确能学到更多样的特征表示。这一点是有迹可循的,可以追溯到AlexNet提出的时候(AlexNet把网络分成两组,其实这样做的目的是硬件不行,通过分组以减少显存,但是却发现下面这种比较神奇的事情,也算是无心为之的发型),两组sub-networks一组倾向于学习黑白的信息(下图上半部分),而另一组倾向于学习到彩色的信息 (下图下半部分)。
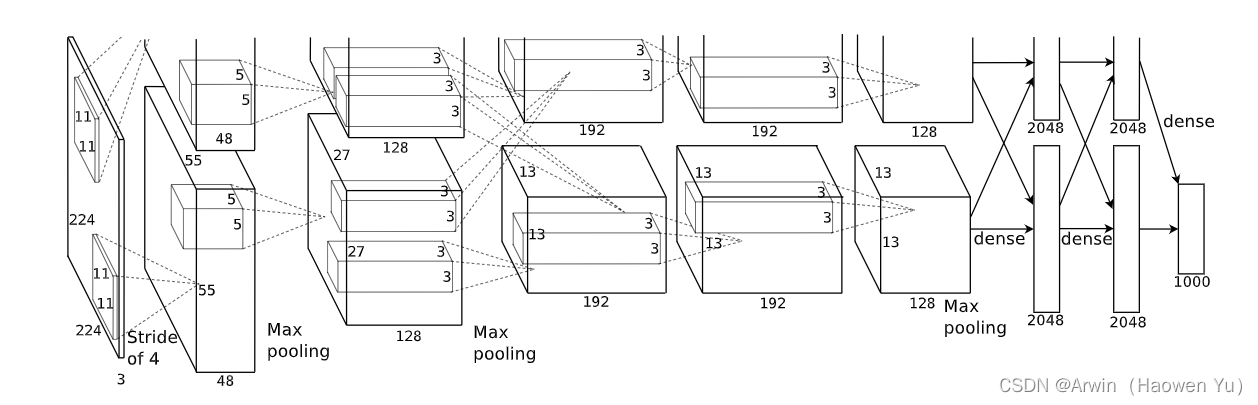

AlexNet 论文中没有明确指出的是卷积组更重要的副作用,即它们可以学习更多样的表示。其实现在看来,相比分组卷积带来的参数量减少这一好处,分组卷积可以学习更多元的特征表示这一好处先的更加重要;因为,后面的研究发现,分组卷积即便能减少大量参数,但是其在硬件上的实际运行时间并没有很快。
其实,多说一点,该思路沿用到Transformer里就有了multi-head attention (其实是一个思路,大家细品一下, kernel, head和cardinality是不是本质上一样?)
由此可以看到,ResNeXt或者Multi-head Attention,相比于原始的ResNet或者Single-head Attention会具有更强的表征能力,这里引用一下Transformer原文的一句:Multi-head attention allows the model to jointly attend to information from different representation subspaces.这句话很简洁的表达了cardinality以及number of heads的作用。
ResNeXt既有残缺结构(便于训练), 又对特征层进行了concat(对特征多角度理解)。这就类似于模型融合了,把具有不同优点的子模型融合在一起,效果的更好。另外,这种分组的操作或许能起到网络正则化的作用。
二、ResNeSt
ResNeSt是亚马逊的李沐团队的paper,最近在各个任务上刷榜了,但却被ECCV2020 strong reject了,在知乎上也是引起了热议,据李沐说这个网络花了一百万刀!(主要用于做各种各样的实验)。我看完以后感觉是ResNeXt + SKNet的组合,训练网络的很多tricks在工程上还是很有意义的。
至于paper被拒的原因,这里满足一下各位好奇宝宝们,引用一下review里的原话:“It more likes to combine ResNeXt-D and SKNet together and do not introduce new points from the perspective of attention.” 话里话外的意思就是这个研究是之前算法的组合,模型层次没有创新点。但是,我寻思ResNeXt不也是这样吗…当然,这并不是说这个研究没有价值;反而由于paper里的大量实验,这篇paper的工程价值非常大,不是水文!
1. SKNet
人家review也说了,ResNeSt看上去像ResNeXt-D 和 SKNet 的结合体,ResNeXt刚刚讲了,那么这里就讲一下SKNet(SENet的孪生兄弟,SENet不熟悉的可以翻我之前的博文,传送门)
Selective Kernel Networks 启发自皮质神经元根据不同的刺激可动态调节其自身的receptive field,是结合了SE operator,Merge-and-Run Mappings,以及 attention on inception block 思想的产物。
从设计理念上来讲也比较simple,即对所有的尺寸大于1的卷积核进行 Selective Kernel 改造,充分利用group/depthwise卷积带来的较小的理论参数量和flops的红利,从而使增加多路的特征融合与动态选择,但实际group/depthwise的加速优化目前还不是特别好,导致实际速度还是略有一些慢的。
抛开channel级别的attention的引入(源于SENet),此前介绍过两个比较朴素且有效的架构:ResNeXt 和 Inception。前者特点是用组卷积轻量化了尺寸大于1的卷积核;后者特点是多路的multiple kernel设计融合了不同尺寸的特征。那么,SKNet设计的一大出发点就是看是否能够combine两者的特色。那么从哪里入手呢?我们且看从ResNet到ResNeXt中的计算量分布:
从ResNet到ResNeXt,尺寸大于1的卷积计算量从原来52.9%的占比下降到了6.6%,几乎下降了一个数量级,但却让ResNeXt的分类性能提升了。从这个观察出发,我们可以引申出这么几个点:
1) 首先,这证明了ResNet的参数量很可能存在冗余;其次,计算量占比下降到这种程度都能够有明显提升,是否在稍微召回一些 > 1 kernel的计算量也能得到进一步的增强,得到更好的trade-off?
2) 因为本身计算量占比已经非常小,所以可以在这个部分尝试引入同样轻量的多路(multiple path)设计去召回这些计算量;
3) 结合这些,完全可以在模型中实现用动态attention机制建模multiple kernel selection,并且只会在此之上带来很小的理论计算。简单一句话总结一下,即是用multiple scale feature汇总的信息来channel-wise地指导如何分配侧重使用哪个kernel的表征,下面引出正主:
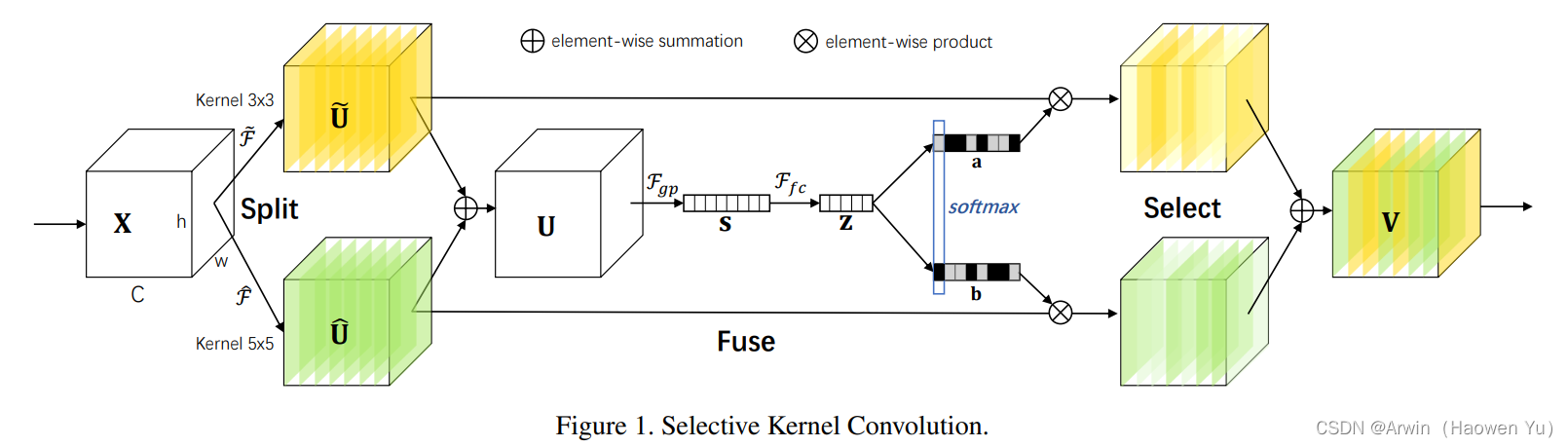

看公式可能有点头晕,这里贴个代码辅助大家理解一下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SKConv(nn.Module):
def __init__(self,in_channels,r=16,L=32):
'''
Parameters
----------
in_channles : TYPE
输入通道数.
bratches : TYPE
分支数.
r : TYPE, optional
缩减率中的r. The default is 16.
L : TYPE, optional
Z中神经元个数的下限. The default is 32.
'''
nn.Conv2d
super(SKConv,self).__init__()
self.in_channels = in_channels
d = max(round(in_channels/r),L)
self.conv_A = nn.Conv2d(in_channels,in_channels,3,stride=1,padding=1,groups=32,bias=False)
self.bn_A = nn.BatchNorm2d(in_channels)
self.conv_B = nn.Conv2d(in_channels,in_channels,3,stride=1,padding=2,dilation=2,groups=32,bias=False)
self.bn_B = nn.BatchNorm2d(in_channels)
self.globalAvgPool = nn.AdaptiveAvgPool2d((1,1))
self.conv_fc1 = nn.Conv2d(in_channels,d,1,bias=False)
self.bn_fc1 = nn.BatchNorm2d(d)
self.conv_fc2 = nn.Conv2d(d,2*in_channels,1,bias=False) #前一半结果是第一个分支的,后一半结果是第二个分支的
def forward(self,x):
dA = F.relu(self.bn_A(self.conv_A(x)))
dB = F.relu(self.bn_B(self.conv_B(x)))
print(dA.shape)
print(dB.shape)
out = self.globalAvgPool(dA+dB)
out = F.relu(self.bn_fc1(self.conv_fc1(out)))
out = self.conv_fc2(out) # (b,2*in_channels,1,1)
out = out.reshape(-1,2,self.in_channels,1,1)
out = F.softmax(out,1)
dA = dA * out[:,0]
dB = dB * out[:,1]
out = dA + dB
return out
2. ResNet 与 ResNeSt
讲了这么久SKNet,差点忘了正题了…。先来一组对比图。可以看出,各组网络的核心区别,还是在split attention上。
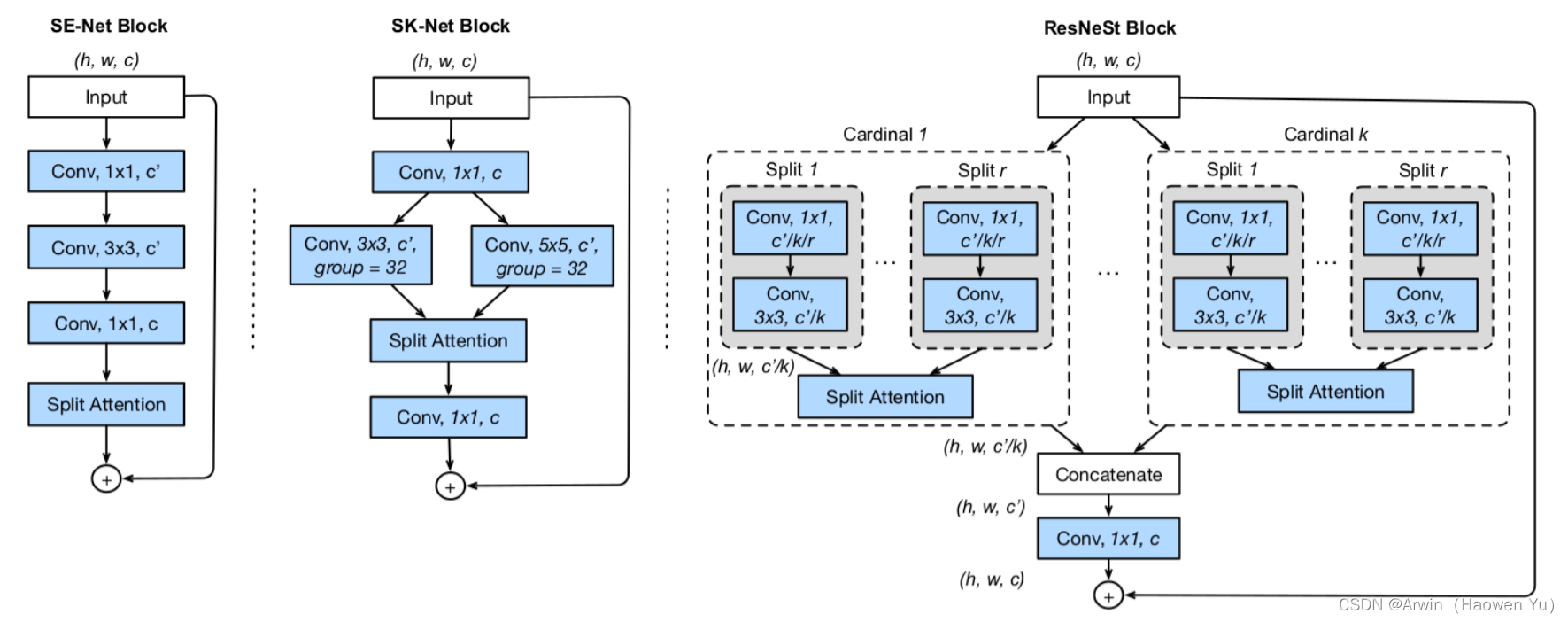
各位小伙伴有没有觉得:ResNeSt是ResNeXt与SKNet的组合?其实这样说并没有错,作者也提到了这篇文章主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。
总结
持续更新ing…



评论(0)
您还未登录,请登录后发表或查看评论