

算法思想
提出 Deep Many-Tasks 方法来对一个图片进行多任务车辆分析,包括车辆检测,部分定位,可见性描述和 3D维度估计。
论文的主要贡献包括三个方面:
使用图像车辆的特征点来编码 3D 车辆信息。因为车辆具有已知的形状,可以用单目图像重构 3D 车辆信息。我们的方法还可以在车辆部件被遮挡,截断等情况下定位到车辆部件,使用回归的方法而不是 part detector. 预测 hidden parts 的位置对 3D 信息的恢复很有帮助。我们使用一个 3D vehicle 数据集,由具有真实维度的 3D meshes 组成,即具有 3D 框的数据集。每一个 3D model 都有一些顶点,对应于车轮等部件,对每一个 model 来说,这些顶点组成了一个 3D shape. 这个方法的主要思想是在 input image 中恢复这些 3D points 的映射。2D/3D matching 在 2D shape 和选择的 3D shape进行,以恢复车辆的方向和 3D location.
Deep Coarse-to-fine Many-Task 网络。首先使用 RPN 网络产生 corase 2D bounding box,之后迭代产生精细化 bounding box. 六个任务共享特征向量:region proposal , detection , 2D box regression , part location , part visibility , 3D template prediction.
使用 3D models 来生成 image 的标签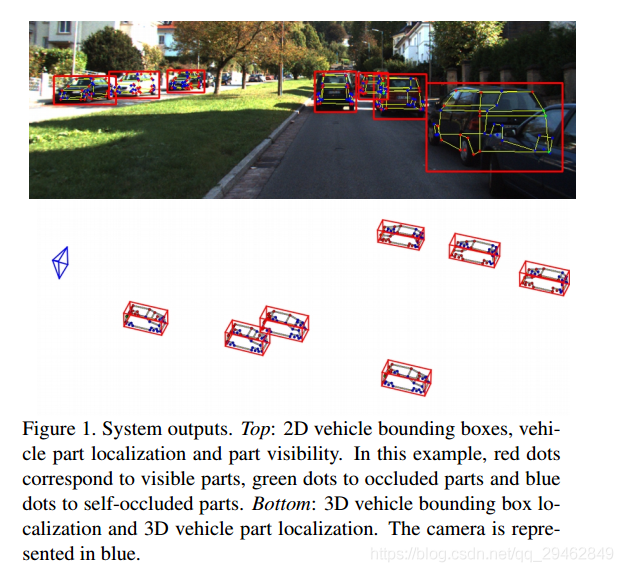
网络结构
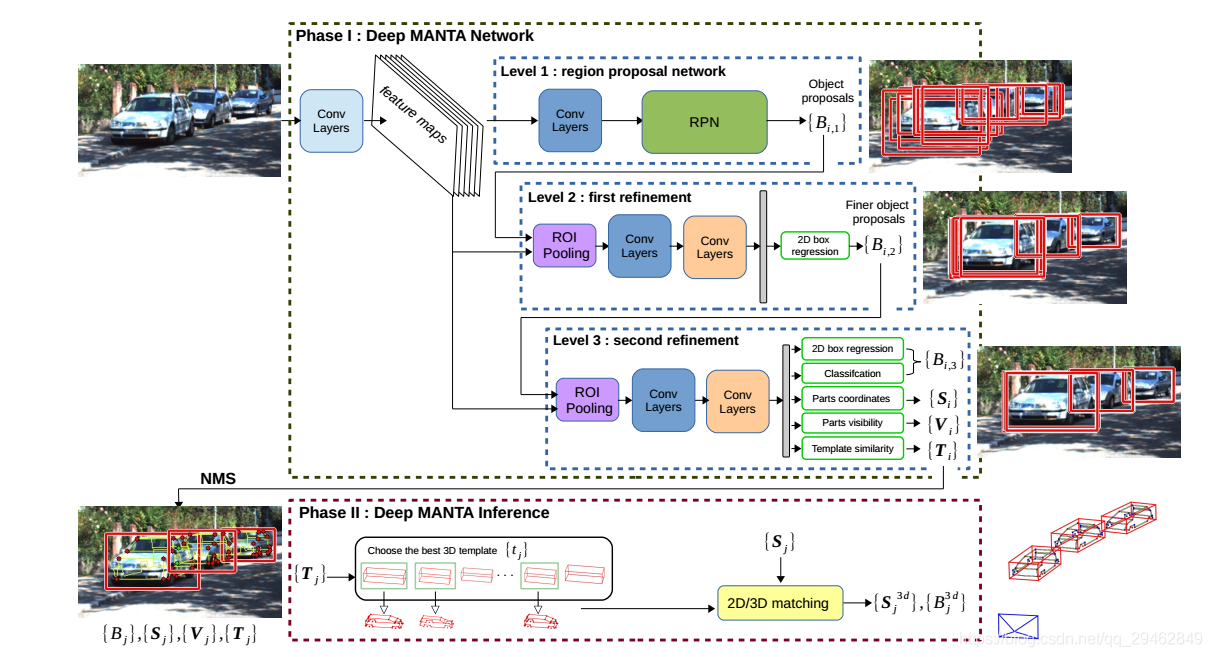
上图即是本代码所用的网络,主要包括PhaseI,Phase II。
Phase I 一共分为Level1、Level2、Level3三个层次。Level1是RPN层,负责2d box的推荐,Level2是对Level1推荐的box进一步进行微调,Level3是基于Level2和共享特征进一步回归出五个模块,分别是2D box regression、Classification、Parts coordinates、Parts visibility、Template similarity五部分,下面将会逐渐介绍这些部分。
Phase I
2D box regression 和Classification
这里的2D box regression和classification和普通的物体检测网络相似。
Parts coordinates
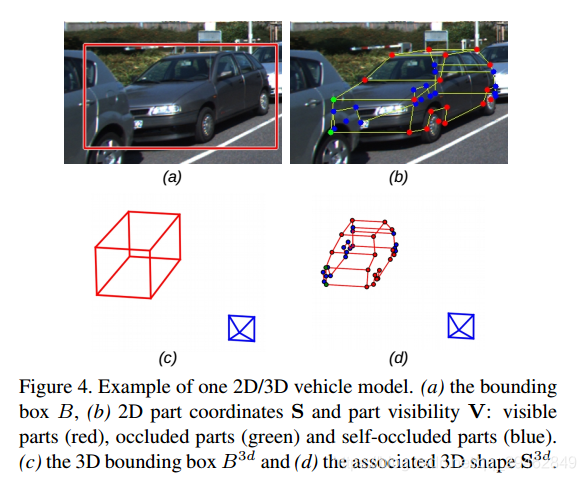
这个意思是特征点坐标,其实在这里是这样子的,一个车被定义了有36个特征点,这个数量是作者在论文中定义的。这个分支部分主要预测ROI 区域内的36个特征点在二维图像上的坐标。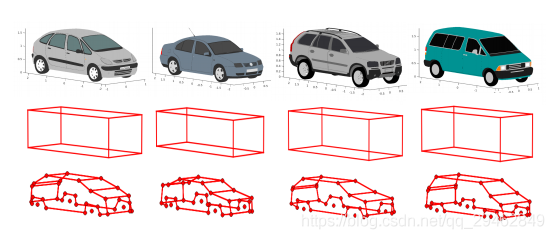
Parts visibility
上部分预测出了每个特征点在二维图像上的坐标,但是不能保证每个特征点是否可见,parts visibility正是判断每个特征点是否可见,这样可以最大程度上还原车辆真实遮挡情况。
Template similarity
这个是模板相似性,线下的模板库中一共有103个model,每个model的3d box的长宽高已知,这里的Template similarity其实就是预测出的3d box的长宽高的相对值,在这里,比如以1为单位,预测出的w、h、l值可能为0.3,0.5,1, 那么就可以在数据库中找到一个模型,w、h、l的比值和这个最相似,那么就把改模型确认为检测出的模型。
注意:因为实际道路上的汽车模型本身就那么多,数据库现有的103个模型已经基本上覆盖到了各种各样的模型了,所以基本上可以查找出。
这里的Phase II其实就是对Phase I产生的结果进行计算,最终输出3D box和特征点的3d 坐标。上面已经讲到,通过Template similarity可以找到对应的模型,这个模型的标签有3d box大小、坐标、角度、以及36个特征点的坐标。 (cx; cy; cz; θ; t) is the 3D bounding box characterized by its 3D center (cx; cy; cz), its orientation θ and its 3D template t = (w; h; l) corresponding to its 3D real size. (xk; yk; zk) is the vehicle 3D part coordinates in the 3D real word coordinate system.
这样,我们可以得到计算出的模型是哪个,世界坐标系下的3d box的长宽高是多少,特征点在世界坐标系下的坐标。采样时,其实已经知道某个模型相对于相机坐标系下的姿态,该模型在2d姿态下的对应特征点坐标也已经知道。
假定模型在制作的时候,相对于拍摄相机坐标系的变换关系为R,T,实际计算时的相机坐标系为R1,T1,那么给定二维对应点坐标和三维对应点坐标,剩下的就是pnp求解了:
[ x , y , 1 ] = K ∗ [ R , T ] ∗ [ X , Y , Z , 1 ] ∗ [ R 1 , T 1 ]
求出后,检测出的汽车在相机坐标下的所有参数都迎刃而解。
")


评论(0)
您还未登录,请登录后发表或查看评论