

以前用刚性词级边界框训练的方法在以任意形状表示文本区域方面存在局限性。论文提出了一种新的场景文本检测方法,通过探索每个字符和字符之间的亲和力来有效地检测文本区域。为了克服缺乏单个字符级别注释的问题,论文提出的框架既利用了合成图像的给定字符级别注释,也利用了通过学习的临时模型获得的真实图像的估计字符级别地面实况。为了估计字符之间的亲和力,网络使用新提出的亲和力表示进行训练。对六个基准的广泛实验,包括在自然图像中包含高度弯曲文本的 TotalText 和 CTW-1500 数据集,表明我们的字符级文本检测显着优于最先进的检测器。根据结果,我们提出的方法保证了检测复杂场景文本图像的高度灵活性,例如任意方向、弯曲或变形的文本。
https://arxiv.org/pdf/1904.01941.pdf
https://arxiv.org/pdf/1904.01941.pdf
场景文本检测因其众多的应用而在计算机视觉领域引起了广泛关注,例如即时翻译、图像检索、场景解析、地理定位和盲导航。 最近,基于深度学习的场景文本检测器显示出了良好的性能。这些方法主要训练他们的网络来定位词级边界框。 但是,它们可能会在例如弯曲、变形或极长的文本,这些文本很难用单个边界框检测到。 或者,在通过以自下而上的方式链接连续字符来处理具有挑战性的文本时,字符级意识具有许多优势。 幸运的是,现有的大多数文本数据集都没有提供字符级别的注释,而获取字符级别的基本事实所需的工作成本太高

使用 CRAFT 进行字符级检测的可视化。(a) 我们提出的框架预测的热图。 (b) 各种形状文本的检测结果。
在论文中,提出了一种新颖的文本检测器,可以定位单个字符区域并将检测到的字符链接到文本实例。 我们的框架,称为CRAFT(Character Region Awareness For Text detection),设计有一个卷积神经网络,产生字符区域得分和亲和力得分。 区域分数用于定位图像中的单个字符,而亲和力分数用于将每个字符分组为单个实例。 为了弥补字符级注释的不足,我们提出了一个弱监督学习框架,用于估计现有真实单词级数据集中的字符。
在深度学习出现之前,场景文本检测的主要趋势是自下而上,其中主要使用手工制作的特征——例如 MSER 或 SWT——作为基本组件。 最近,通过采用流行的对象检测/分割方法,如 SSD、Faster R-CNN 和 FCN,提出了基于深度学习的文本检测器。
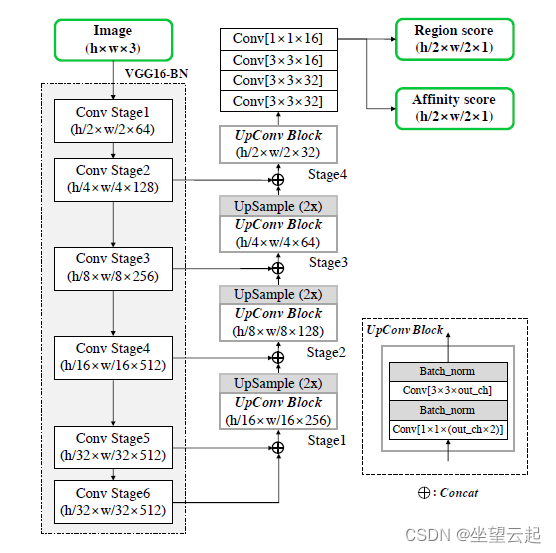
采用基于 VGG-16 并具有批量标准化的全卷积网络架构作为主干。 模型在解码部分有跳跃连接,这与 U-net 相似,因为它聚合了低级特征。 最终输出有两个通道作为分数图:区域分数和亲和力分数。 网络架构如下图所示。
主要目标是在自然图像中精确定位每个单独的字符。 为此训练了一个深度神经网络来预测字符区域和字符之间的亲和力。 由于没有可用的公共字符级数据集,因此该模型以弱监督方式进行训练。
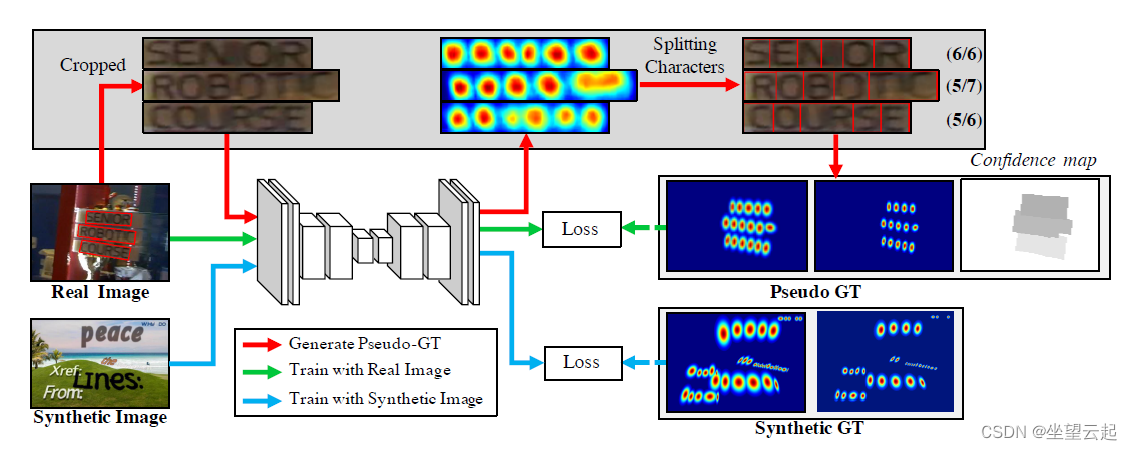
所提出方法的整体训练流程示意图。 以弱监督方式使用真实图像和合成图像进行训练。
对于每个训练图像,为区域得分和具有字符级边界框的亲和力得分生成地面实况标签。 区域分数表示给定像素是字符中心的概率,亲和度分数表示相邻字符之间空间的中心概率。
与合成数据集不同,数据集中的真实图像通常具有单词级别的注释。 在这里,我们以弱监督的方式从每个词级注释生成字符框,如上图所示。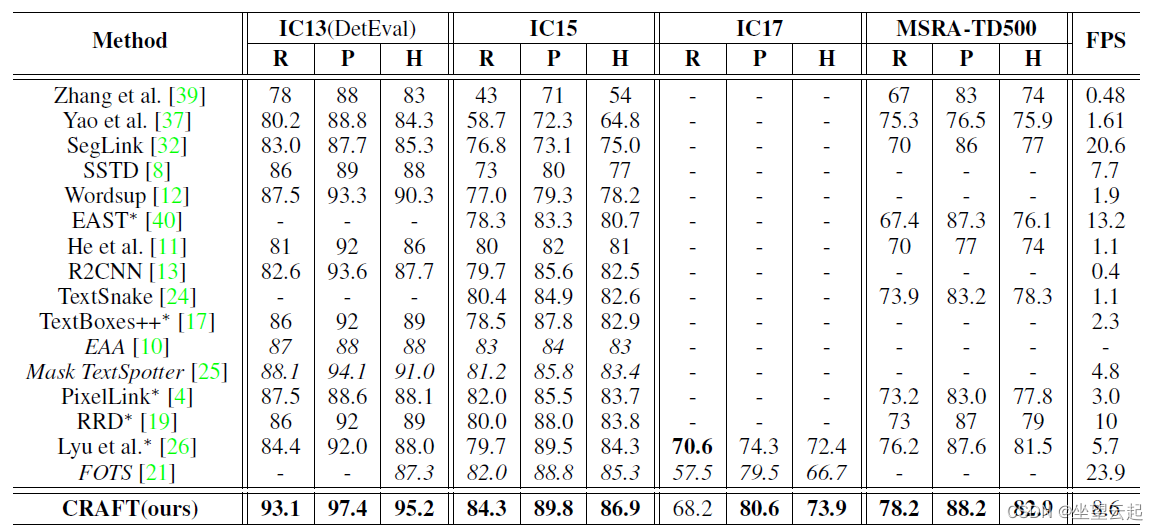
即使没有给出字符级注释,它也可以检测单个字符。 所提出的方法提供了字符区域分数和字符亲和力分数,它们一起以自下而上的方式完全覆盖了各种文本形状。 由于提供字符级注释的真实数据集很少见,因此我们提出了一种弱监督学习方法,该方法可以从临时模型生成伪真实数据。 CRAFT 在大多数公共数据集上展示了最先进的性能,并通过展示这些性能而无需微调来展示泛化能力。 未来希望以端到端的方式用识别模型训练我们的模型,看看 CRAFT 的性能、鲁棒性和通用性是否转化为更好的场景文本识别系统,可以应用于更一般的场景。



评论(0)
您还未登录,请登录后发表或查看评论