

CNN-VGG
1 . 图像识别的过程
-
**获取原始信息:**通过传感器将获取到的外界信息(比如图像)转换为计算机可以处理的信号。
-
**预处理:**对图像进行平移变换、旋转、去噪声…操作,目的是加强图像中的感兴趣特征。
-
**特征抽取与特征选择:**是指在模式识别中,需要进行特征的抽取和选择。特征抽取和选择在图像识别过程中是非常关键的技术之一。
-
**分类器设计:**是指通过训练而得到一种识别规则,通过此识别规则可以得到一种特征分类,使图像识别
技术能够得到高识别率。分类决策是指在特征空间中对被识别对象进行分类,从而更好地识别所研究的
对象具体属于哪一类。
2. 分类与检测
分类: 分类即为给定一张图片,能够完成将其判定为某个类别的工作。
检测: 检测即为将给定类别的对象在图片中找出来,并给出在图片中的存在区域的工作。

3. VGG神经网络
常见的CNN(卷积神经网络)

笔者上一篇博客所提到的AlexNet是最经典的CNN模型,而VGG是基于AlexNet进行过改进的网络模型,后面发展出来的这几个分支的(不同色块不同分支)都有各自的优化特点,而VGG的特点是网络很深,达到了16-19层,并且用了小卷积核(3x3)
VGG19(数字代表层数,每层又包含一定的卷积、池化、全连接等操作)如下
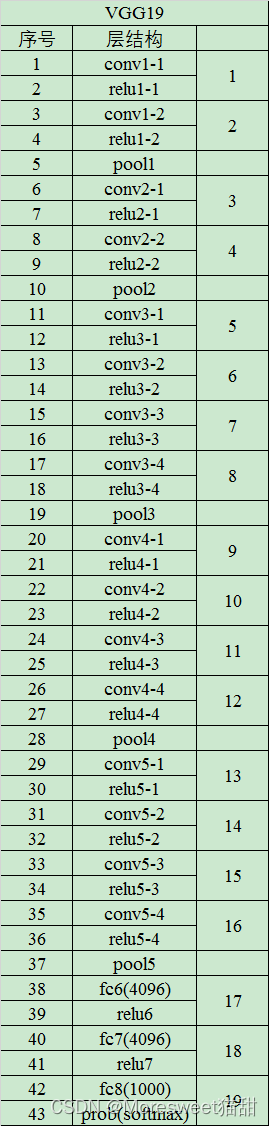
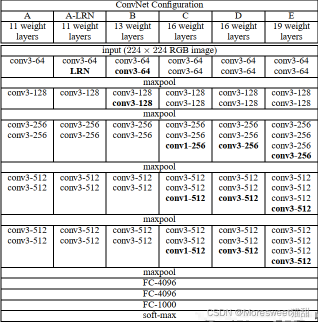
下面以VGG16为例进行分析:
vgg16网络结构含有参数的网络层一共有16层,即13个卷积层,5个池化层,3个全连接层,不包括激活层。(注:池化层不包含参数,故VGG16的16计算不包含无参数的层,只计算了卷积层和全连接层)
例子:
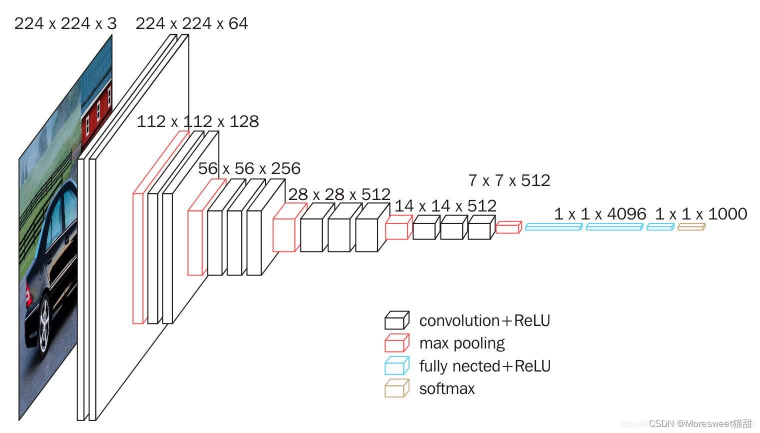
逐层分析:
输入图片为(224,224,3)即分辨率224x224的三通道图片信息,如果图片大小不同需要resize
通道数计算公式:N=(W-F+2P)/S + 1
conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为
(112,112,64)。
conv2两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再2X2最大池化,输出
net为(56,56,128)。
conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net
为(28,28,256)。
conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net
为(14,14,512)。
conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net
为(7,7,512)。
利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。最后输出的就是每个类的预测。
VGG的优化策略思想
使用卷积层代替全连接层
全连接层的计算方式其实就是卷积核大小为feature map大小的卷积,使用卷积层代替全连接层的办法就是将卷积核设为输入空间大小。
为什么要如此操作,因为很多计算机资源(如CUDA)对卷积操作进行了处理,能够加速,而FC却不能,故而能够提高效率。
例如VGG16第一个全连接层的输入是7x7x512,输出为1x1x4096,这可以用一个卷积核大小7x7, 步长
(stride)为1, 没有填补(padding),输出通道数4096的卷积层等效表示,其输出为1x1x4096,和全连
接层等价。后续的全连接层可以用1x1卷积等效替代。
1x1卷积
1x1卷积能够实现特征通道的升维和降维,这样使用卷积核的个数就是输出的通道数,相比池化层并不能改变通道数,其只能实现feature map的降维。
个人学习笔记,仅交流学习,转载请注明出处!



评论(0)
您还未登录,请登录后发表或查看评论