

1 关于gallery和probe的介绍
在人脸识别中评价指标中仅仅通过准确率是无法评价一个模型性能的,因为准确率无法体现出人脸识别中最重要的指标通过率和拒绝率(参考),而通过率、拒绝率的计算就会设计到gallery和probe的概念,往下继续看吧。
1、首先来看下单词的意思:
gallery:画廊
probe:探针、调查
2、下面从具体使用gallery和probe的场景介绍什么着两个东西具体是什么
1)gallery
在评价人脸识别模型的时候,通常需要构建一个很大的人脸数据库(百万级别),人脸数据库就是每个人注册一张人脸图片,并和为其绑定一个身份ID,这样就构建了一个巨大的人脸识别数据库,这个数据库就是gallery!测试的时候需要,就是拿一张人脸图片与注册数据库中的人脸一个一个去比对(一般比对的都是提取好的特征)
2)probe
probe原意:探针、调查。这里博主就通俗地翻译为查询集,就是说,我们在测试的时候是在probe中选取元素来到gallery寻找的,最终测试阶段对模型性能的评估是根据probe中元素查询的效果来反映的。
注意1:gallery是只有测试集才有的,因为训练的时候我们的期望是模型能根据两张标注好的图像更好地提取特征,以及判断相似度。这个过程的数据来源是标注好的图像,目标仅仅是训练模型对提供的图片的特征提取能力,也就不需要gallery来提供参考。
注意2:根据查询的probe是否在gallery中,又可以把probe中的数据分成pg和pn,后面我们在继续介绍人脸识别的评价指标!
参考:https://www.zhihu.com/question/38194429
参考:https://blog.csdn.net/weixin_44273380/article/details/108949031 # 这篇博客对gallery和probe解释的比较准确,
参考:https://blog.csdn.net/fzthao/article/details/60320780
参考:https://blog.csdn.net/Roland2014/article/details/78912169
2 二分类常用评价指标
在介绍人脸识别评价指标之前,我们先来回顾一下分类评价指标
2.1 二分类常用的评价指标
1、二分类算法常用的评价指标,他们都是基于混淆矩阵的度量标准:
TP(True Postives):真阳性 / 真正例:分类器把正例正确的分类/预测为正例
FN(False Negatives):假阴性 / 伪负例:分类器把正例错误的分类/预测为负例
TN(True Negatives):真阴性 / 真负例:分类器把负例正确的分类/预测为负例
FP(False Postives):假阳性 / 伪正例:分类器把负例错误的分类/预测为正例
所以上面,可以叫阳性、阴性 或 正例、负例

实际正例数量+实际负例数量=测试数据集大小/样本总数=TP+TN+FP+FN
这四个基础指标的组合,就可以得到其他的指标!
2、相关计算
P = TP+FN:表示实际为正样例的数目
N = TN+FP:表示实际为负样例的数目
True、False:描述的是分类器预测(判断)的是否正确
Positive、Negative:是分类器的分类结果,如果正例为1,负例为-1,即:positive=1,negative=-1,用1表示True,-1表示False,例如:
TP:实际类别标签为=1*1=1正例
FP:实际类别标签为=(-1)*1=-1负例
FN:实际类别标签为=(-1)*(-1)=1正例
TN:实际类别标签为=1*(-1)=1负例
3、真假阳性率,真假阴性率(参考):
真阳性率TPR(TruePositiveRate) = 正样本被预测为正样本数 / 所有正样本实际数 = TP / (TP + FN) = TP / P = sensitivity = recall
假阳性率 FPR(FalsePositiveRate)=正样本被错误预测为负样本 / 所有负样本 = FP / (TN+FP )=FP / N
真阴性率TNR(TrueNegativeRate) = 负样本被预测为负样本 / 所有负样本= TN / ( TN + FP) = TN / (TN+FP)=TN / N
假阴性率FNR(FalseNegativeRate)= 正样本被预测为负样本 / 所有正样本 = FN / ( TP + FN)=FN /P
2.2 混淆矩阵
1、混淆矩阵就是基于TP、TN、FP、FN四个指标计算的(参考)
| n=192 | predicted:1 | predicted:0 |
|---|---|---|
| actual:1 | 118(TP) | 12(FN) |
| actual:0 | 47(FP) | 15(TN) |
在混淆矩阵中,如果你看到所有的值都位于斜对角线上时,表示该模型对分类性能非常好,对正样本和负样本全部预测正确!

当然TP、FP、TN、FN,混淆矩阵在多分类中同样适用,具体计算操作可以参考这篇博客(参考)
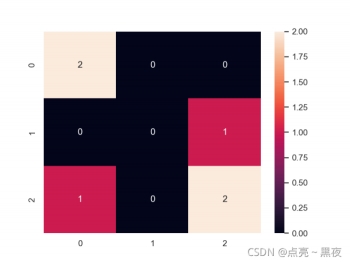
画混淆矩阵:右侧的颜色条深浅,表示被预测为某一类的数量多少,因此一般也可以通过混淆矩阵查看样本是否均衡!
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
y_true = [2, 1, 0, 1, 2, 0]
y_pred = [2, 0, 0, 1, 2, 1]
C1 = confusion_matrix(y_true, y_pred)
print(C1)
'''
[[1 1 0]
[1 1 0]
[0 0 2]]
'''
y_true = ["cat", "ant", "cat", "cat", "ant", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"]
# 0 代表ant 1代表bird 2代表cat
C2 = confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
print(C2)
'''
[[2 0 0]
[0 0 1]
[1 0 2]]
'''
sns.set()
f, ax = plt.subplots()
sns.heatmap(C2, annot=True, ax=ax) #画热力图
plt.show()
y_true = [“cat”, “ant”, “cat”, “cat”, “ant”, “bird”]
y_pred = [“ant”, “ant”, “cat”, “cat”, “ant”, “cat”]
| 样本数=6 | ant-predict 0 | bird_predict 1 | cat_predict 2 |
|---|---|---|---|
| ant_actual 0 | 2 | 0 | 0 |
| bird_actual 1 | 0 | 0 | 1 |
| cat_actual 2 | 1 | 0 | 2 |
通过绘制的混淆矩阵可以看出:
- 混淆矩阵上所有的数加起来刚好是样本数6=2+0+0 +0+0+1 + 1+0+2
- 0 代表的是ant,实际ant,且被预测为ant的数量是2,从我们给出的测试数据中也是可以看到的
- 混淆矩阵的颜色深浅表示数量多少!
2.3 评价指标
1)正确率(accuracy rate)
正确率是最常见的评价指标:正确率是被分对的样本数在所有样本数中的占比,通常来说,正确率越高,分类器越好!
accuracy_rate= (TP+TN ) / (TP+TN+FP+FN)=(TP+TN)/(P+N)=(正确的预测为正例TP+正确的预测为负例TN) / 所有的正样本和负样本
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
accuracy_rate=(FP+FN)/(P+N)=(错误的预测为正例FP+错误的预测为负例FN)/所有的正样本和负样本
error_rate=1−accuracy
3)灵敏度(sensitivity)= 真阳性率
灵敏度(sensitivity):表示的是所有正例被分对的比例,衡量了分类器对正例的识别能力。
灵敏度(sensitivity)=TP/(TP+FN)=TP/P
4)特异性(specificity)
特异性(specificity):表示的是所有负例被分对的比例,衡量了分类器对负例的识别能力。
特异性(specificity)= TN/(TN+FP)=TP/N
5)精度(precision)
精度(precision):精度是精确性的度量,表示被正确分为正例在所有被分为例中的比例,当然也是精度越高越好!
精度(precision)=TP /(TP+FP)
6)召回率(recall),又被称(TPR),真阳性率、查全率、TAR
召回率(recall):是覆盖面的度量,度量有多少个正例被分成正例,和灵敏度是一样的!
recall=TP /(TP+FN)=TP/P=sensitivity
7)其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
8)精度和召回率反应了分类器性能的两个方面,因此需要综合考虑查准率(precision)和查全率(recall)(参考)前面的指标介绍完了,下面再开始介绍ROC曲线和PR曲线:
1、P-R曲线(precision-recall 曲线)
PR曲线是Precision Recall Curve的简称,描述的是precision和recall之间的关系,以recall为横坐标,precision为纵坐标绘制的曲线。该曲线的所对应的面积AUC实际上是目标检测中常用的评价指标平均精度(Average Precision, AP)。AP越高,说明模型性能越好。
以查准率为纵轴,查全率为横轴作图, 就得到查准率-查全率曲线, 简称 “P-R曲线”, 显示该曲线的图称为 “P-R图”
纵轴是:查准率(precision)= TP / (TP + FP)
横轴是:查全率(recall)= 真阳性率 = TP / TP + FN
坐标值:
坐标值:(查全率,查准率)=(recall,precision)
在实际的模型评估中,单用Precision或者Recall来评价模型是不完整的,评价模型时必须用Precision/Recall两个值。这里介绍三种使用方法,来说面如何取precision 和 recall的一个平衡值,作为模型评估的标准(参考):
- 平衡点(Break-Even Point,BEP)
- F1度量
- F1度量的一般化形式。
BEP是查准率和查全率曲线中查准率=查全率时的取值,如下
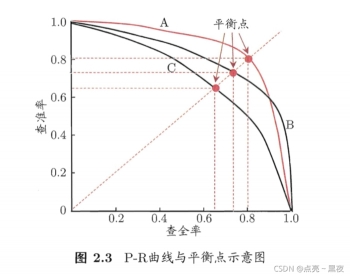
图片来源:https://www.cnblogs.com/nowgood/p/APdefinite.html
P-R曲线与平衡点,从图中可以看出效果:
A>B>C # 即越靠近右上角的平衡点,对应的precision和recall代表当前模型比较好!
一般来说,若一个 P-R 曲线被另一个 P-R 曲线 完全”包住”的话,则后者的性能优于前者(面积越大, 性能越好吧).
F1度量的准则是:F1值越大算法性能越好,公式如下:

在一些实际使用中,可能会对查准率或者查全率有偏重,比如:逃犯信息检索系统中,更希望尽量少的漏掉逃犯,此时的查全率比较重要。会有下面F1的一般形式。
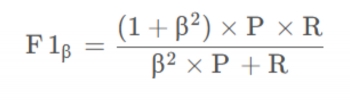
当!$\beta>1$时查全率(recall)重要,!$\beta<1$时查准率(precision)重要
2、ROC曲线(Receiver Operating Characteristic Curve)
ROC曲线是(Receiver Operating Characteristic Curve,受试者工作特征曲线)的简称,是以灵敏度(真阳性率)为纵坐标,以1减去特异性(假阳性率)为横坐标绘制的性能评价曲线。可以将不同模型对同一数据集的ROC曲线绘制在同一笛卡尔坐标系中,ROC曲线越靠近左上角,说明其对应模型越可靠。也可以通过ROC曲线下面的面积(Area Under Curve, AUC)来评价模型,AUC越大,模型越可靠。
纵轴:灵敏度(sensitivity)=真阳性率=recall=TP / (TP+FN) = TP / P
横轴:1-特异性(specificity)=(假阳性率)= 1 - TN / (TN + FP ) = 1 - TN / N = FP / (TN+FP)=FP / N
坐标值:(1-特异性,灵敏度)= (1 - 特异性,recall)
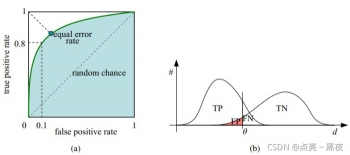
如何画ROC曲线(参考)
3、AUC(Area Under Curve)
ROC曲线下的面积就是AUC,可以用AUC围成的面积越大,模型越可靠!
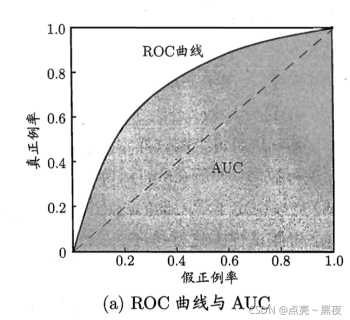
4、ROC曲线和P-R去向有什么联系和不同 ?(参考)
相同点:首先从定义上PR曲线的R值是等于ROC曲线中的TPR值(真阳性率=召回率recall),都是用来评价分类器的性能的.
不同点:ROC曲线是单调的而PR曲线不是单调的(根据它能更方便调参), 可以用AUC的值得大小来评价分类器的好坏(是否可以用PR曲线围成面积大小来评价呢?), 正负样本的分布失衡的时候,ROC曲线保持不变,而PR曲线会产生很大的变化。
ROC曲线和PR曲线对比
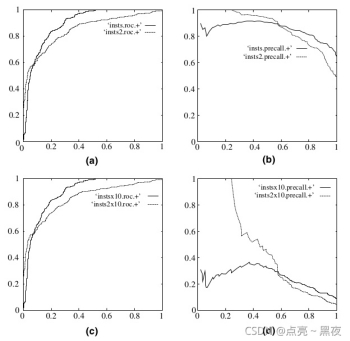
(a) (b) 分别是正反例相等的时候的ROC曲线和PR曲线
© (d) 分别是十倍反例一倍正例的ROC曲线和PR曲线
可以看出,在正负失衡的情况下,从ROC曲线看分类器的表现仍然较好(图c),然而从P-R曲线来看,分类器就表现的很差, 也就是说样本不均衡时, 使用P-R 曲线更能区分不同分类器的性能.事实情况是分类器确实表现的不好,是ROC曲线欺骗了我们。
5、CMC曲线(参考)
CMC曲线全称是Cumulative Match Characteristic (CMC) Curve,也就是累积匹配曲线,同ROC曲线Receiver Operating Characteristic (ROC) curve一样,是模式识别系统,如人脸,指纹,虹膜等的重要评价指标,尤其是在生物特征识别系统中,一般同ROC曲线一起给出,能够综合评价出算法的好坏。
CMC曲线综合反映了分类器的性能,它评价的指标与深度学习当中常用的top1 err和top5 err评价指标一样的意思,不同的是横坐标的Rank表示的是正确率而不是错误率,两者的关系是:
Rank1识别率=1−top1_err
Rank5识别率=1−top5_err
人脸识别评价指标
参考1
参考2:这篇文章写的比较好,能让你快速对人脸识别评价有一个全方位的了解
参考3
3 人脸识别基本概念
3.1 人脸验证(Face Verification 1vs1)
两张图片经过人脸验证系统,判断是否是同一个人,常见的应用有火车站人脸闸机实名验证、手机人脸解锁等。
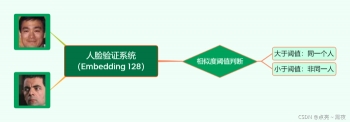
人脸验证测试,需要构建人脸图片对,图片对一般分成:
同一个的人脸的图片对
不同人脸构成的图片对
用于人脸验证测试的识别算法需要计算人脸图片对中两张人脸之间的相似度(表示两张人脸之间的相似程度,值越高表示两张人脸为同一人的概率越高),后通过相似度阈值确定识别算法预测的图片对是否为同一人:
相似度大于阈值:表示预测为同一人
相似度小于阈值:表示预测为不同人
最终识别算法的预测结果会分成以下几种情况:
TP(True Positve):同人对被正确预测为同一人
TN(True Negative):不同人对被预测为不同一人
FP(False Positive):不同人对被错误的预测为同一人
FN(False Negative):同人对被错误的预测为不同人
把同人对看作是正例,把不同人对看作是负例
3.2 人脸辨识 / 识别(Face Identification 1vsN)
1、人脸辨识是指给定一张人脸图片图片,在人脸数据库中检索以确定人脸身份的过程,其流程如下图,人脸辨识测试一般也称谓1vsN测试。
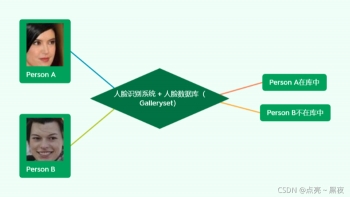
人脸——》人脸识别系统+人脸数据库——》personA(pg)
人脸——》人脸识别系统+人脸数据库——》不在库人脸(pn)
2、人脸辨识测试一般需要构建两个数据集:
GallerySet(入库图片)
PobeSet(测试图片)
其中,GallerySet图片即为上述人脸数据库中的图片,ProbeSet图片为待验证身份的图片。根据ProbeSet图片的ID与GallerySet图片的ID关系可将人脸辨识测试分为开集测试(Open-Set)和闭集测试(Close-Set),其中:
1)开集测试:ProbeSet中存在一些人脸的ID不在Gallery中。PorbeSet数据可以分成两部分:
- 将ProbeSet中ID在Gallery中的图片叫做PG
- 将ProbeSet中ID不在Gallery中的图片叫PN
2)闭集测试:ProbeSet中所有人脸图片的ID都在GallerySet中
如下图:
人脸辨识测试集样例,左边为Gallery,中间为ProbeSet闭集,右边为ProbeSet开集
人脸辨识测试一般是通过ProbeSet图片与GallerySet图片的相似度来判断是否正确,比如,在人脸识别测试中,识别算法预测结果会分成以下几种情况:
TP(True Positve):同人对被正确预测为同一人
TN(True Negative):不同人对被预测为不同一人
FP(False Positive):不同人对被错误的预测为同一人
FN(False Negative):同人对被错误的预测为不同人
4 人脸验证评价方法(1v1测试)
通过判断比对图片的相似度是否大于阈值,常用的性能评估指标有如下几个:
FAR(False Accept Rate):错误接受率 / 误识率 / 误检率 / 认假率
TAR(True Accept Rate):正确接收率 / 召回率 / 查全率
FRR(False Reject Rate):错误拒绝率 / 拒识率 / 漏检率
人脸验正(1v1测试)通过统计不同错误接受率FAR(False Accept Rate,又称误识率)情况下正确的正确接受率TAR(True Accept Rate,又称召回率、查全率)来进行评价。其中:
1、FAR(False Accept Rate)认假率,表示错误的接受比例,与FPR(False Positive Rate)假正例率 / 假阳性率等价,指不是同一个人却被错误的认为是同一个人占所有不是同一个人比较的次数,计算公式如下:

2、TAR(True Accept Rate)表示正确的接受比例,与TPR(True Positive Rate)真正率 / 真阳性率等价,指是同一个人且被正确的认为是同一个人占所有同一个人比较的次数,计算公式如下:

3、FRR(False Reject Rate)错误拒绝率,与FNR(False Negative Rate)假负率 / 假阴性率,指是同一个人但被认为不是同一个人占所有是同一个人比较的次数,计算公式如下:

上面分母说的同人也可以理解为类间,就是同一个人之间,反之也一样!
FRR=FNR=1−TPR=1−TAR=FN /P
一般情况下,我们通过对比感兴趣FAR下的TAR值来分析不同模型的识别性能,如表1,例如!$FAR=[1e-1, 1e-2, 1e-3, 1e-4, 1e-5…]$
5 人脸辨识评价方法(1vN测试)
人脸辨识,根据测试的ProbeSet中图片人的ID是否在GallerySet中分为开集和闭集,那测试自然也分成两种:
闭集测试
开集测试
两种测试的评价方法也会有所不同
5.1 人脸辨识:闭集测试的评价方法
对于GallerySet与ProbeSet闭集进行1vN测试,一般评价方式如下:
每个ProbeSet图片与所有GallerySet图片进行特征比对,获得前TopK个检索结果,若正确ID在检索的所得的TopK个结果中,则正确识别数加1,最终统计命中率,命中率的计算公式:
命中率= 正确识别数N / ProbeSet图片总数
\frac{}{}:如果分母全是中文就会显示不全,如果包含字幕或数字就正常显示,这是bug吗?
一般根据业务需求可关注:Top1、Top30、Top50下的命中率。不同模型可通过如表2所示进行对比,相同TopK下的命中率越高,则代表模型性能越高!
具体操作:
首先明确ProbeSet中的所有图片的ID在GallerySet中都是存在的,具体步骤:
对ProbeSet中的每一张图片根据模型预测出其特征
让ProbeSet每一张图的特征与Gallery中所有图片特征做比对
然后对的所有结果(相似度)进行从大到小排序,然后取出前TopK个的相似度结果
如果这K个相似度结果大于设定阈值,则表示此时测试的ProbeSet中的这张图片在GallerySet中,因此也就命中Gallery中的图片
从上面的分析知道,当TopK中的K取值越小,命中也就比较难,命中率在数值表现上也就小一点,比如一般Top1的命中率肯定是小于Top30的命中率!
5.2 人脸辨识:开集测试的评价方法
对于Gallery与ProbeSet开集进行1vN测试,一般评价方法如下:
统计不同误识率FAR下的正确识别率TAR(也称为通过率),FAR与TAR的计算公式如下:

其中,T代表不同的阈值(threshold)
一般情况下,我们通过对比感兴趣FAR下的TAR值来分析不同模型的识别性能,如表1,例如!$FAR=[1e-1,1e-2,1e-3,1e-4,1e-5,…]$。相同FAR下,TAR越高代表模型性能越好。
所以对于测试:
当pn=0 时,是闭集测试
当pn=0 时,是开集测试
开集测试:

6 人脸识别性能评价指标
在产品实际工作平台以及需求规定的资源下单并发串行测试1000张人脸图片,统计总的特征提取时间后求取平均值。公式如下:
特征提取耗时= 1000张人脸图片特征提取总耗时/1000
7 gallery、probe、pg、pn的数据划分
1、采集到一批人脸数据(百万级别)
2、通过之前与训练的人脸模型对其进行特征提取,每张图片得到一个512维的特征
3、对特征之间进行聚类(计算两站图片的特征距离,也可以认为是相似度!)
4、对聚类的结果中,每一类认为是一个ID,然后从每个ID中抽取一张作为gallery入库,其他的作为probe
5、后面需要根据得到的gallery和probe做1v1测试和1vn测试,然后过滤出以下图片,进行人工核验,最终得到一个正确的gallery和probe数据列表
还有按照质量评价得分进行划分的:使用综合质量打分在每个ID中挑选一张质量分大于0.8的图片入库,其他图片作为PG,如果该ID中所有图片的质量分均小于0.8,则该ID的所有图片作为PN。
probe_num = pg_num + pn_num
pg:是在gallery中有ID的
pn:在gallery中没有ID的
pg和pn是如何划分得到的:
pg_ids = gallery & probe # 两者取交集
pn_ids = probe - pg_ids # 二者取差集
8 测试规范
正常测试集及测试Case
瞳距影响测试集及测试Case
角度影响测试集及测试Case
口罩遮挡测试集及测试Case
戴眼镜测试集及测试Case
刘海测试集及测试Case
种族影响测试集及测试Case
年龄影响测试集及测试Case
特殊情形误识测试集及测试Case
魏梦测试报告中的识别指标:

不应该匹配的人脸,当成匹配人脸的个数:在标准的人脸数据库中测试人脸识别算法的时候,不同人脸特征匹配分数大于给定的阈值,从而被认为是相同人脸的比例!
FRR= 把应该匹配的人脸,当成不匹配人脸的个数 / pg个数
把应该匹配的人脸,当成不匹配人脸的个数:在标准人脸数据库中测试人脸识别算法的时候,同一个人脸的匹配分数低于给定的阈值,从而认为是不同人脸的比例
9 其他
9.1 把txt的特征文件保存成npy类型文件
代码来源:
230服务器:/storage_server1/workspace/weimeng/for_shl/jiadu_test/feature_npy
import os
import numpy as np
import glob
import badu
def load_feat(line):
feat_part = line.split(':')[1]
d_f = [float(d) for d in feat_part.split(" ")]
return np.array(d_f).astype(np.float32)
if __name__ == "__main__":
root = "/data1/weimeng/test/jiadu/testset_500w_v2/check_test/feature_sdk/*feat.txt"
save_root = "/data1/weimeng/test/jiadu/testset_500w_v2/check_test/feature_npy/"
feat_paths = glob.glob(root)
for feat_path in feat_paths:
print(feat_path)
lines = [item.strip() for item in open(feat_path)]
data_dict = {}
for line in lines:
feat = load_feat(line)
key = line.split(':')[0]
data_dict[key] = feat
print("num is: {}".format(len(data_dict)))
np.save(os.path.join(save_root, os.path.basename(feat_path).replace("txt","npy")), data_dict)9.2 读取npy的特征文件
import numpy
Feat_dict = np.load('color_feature.npy', allow_pickle=True).item()
# 调用item() 就可以把读取的npy转换成字典类型!!!
TAR、FAR、FRR公式概念参考
查看:https://blog.csdn.net/sinat_29957455/article/details/109031471
参考:https://blog.csdn.net/Robin_Pi/article/details/107913181
参考:https://lavi-liu.blog.csdn.net/article/details/81259492
参考:https://zhuanlan.zhihu.com/p/33025359
参考:https://blog.csdn.net/colourful_sky/article/details/72830640
参考:https://www.cnblogs.com/dlml/p/4403482.html # ROC介绍比较详细
参考:https://blog.csdn.net/abcjennifer/article/details/7359370
参考:https://zhuanlan.zhihu.com/p/33025359 # FAR和FRR介绍
参考 # 评价指标
参考:https://blog.csdn.net/qq_27871973/article/details/81065074 # 查准率和查全率
参考:https://www.cnblogs.com/nowgood/p/APdefinite.html # ROC和PR曲线
")


评论(0)
您还未登录,请登录后发表或查看评论