

论文:Sequence to Sequence – Video to Text
GitHub - YiyongHuang/S2VT: S2VT pytorch implementation
GitHub - chenxinpeng/S2VT: Tensorflow implement of paper: Sequence to Sequence: Video to Text
论文首次基于sequence to sequence提出一个端到端的模型S2VT,可以实现任意帧的视频输入(sequence of frames),输出任意个数单词(sequence of words)组合成的完整句子输出,从而实现video caption的任务。
模型亮点:
- 可以处理任意帧数的图片输入
- 可以学习到视频中的时序结构
- 可以学习到一个语言模型来学习到自然的输出句子
网络结构:
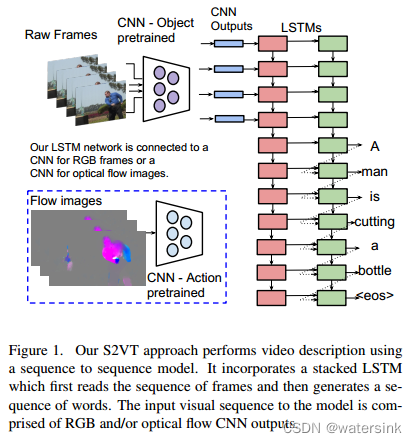
输入图片为一系列的rgb视频帧序列,图片被缩放到256_256,然后随机裁剪为227_227大小。当然输入也可以是光流图,光流梯度图也先归一化到128均值附近后,乘以一定系数变换到0-255区间。网络的主干结构为AlexNet或者VGG。经过主干网络处理,在其fc6层,输出一个长度为500维度的特征,然后输入2层lstm中,输出最终预测句子。
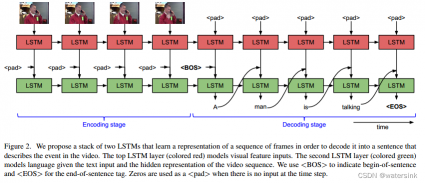
上图包含两层LSTM, 此处我们称上面那层作为第一层,下面作为第二层。其实一般意义上的Sequence to Sequence并不需要包括两层。该框架包含encoding阶段和decoding阶段。CNN抽取视频帧的图像特征后(可以一个视频等间隔取20帧,并使用resnet等模型抽取特征),在每个时间步将一个图像特征送入LSTM作encoding。有意思的是,对于LSTM接口来说,在encoding阶段不是一定要拼接一个<pad>标志符的, 而这里还是设计为跟经过编码的第一层的隐状态拼接起来。在encoder编码完成后,送入decoder,这里的送入指的是decoder中LSTM的初始化。
在decoder阶段需要生成文本。其实,在文本预处理阶段都会先对数据集中所有单词构建词汇表,表中单词和序号一一对应,如(123, man)。这种对应关系相当于给每个词一个标号。这种编码是以独热编码(one-hot)形式存在的,可以理解为一个vector中只有一个位置是1,其他都是0。然后经过embedding转成词嵌入(Word Embedding)。在PyTorch中可以使用nn.embedding()。Word Embedding即可作为单词输入和在模型中生成。图中的<BOS>, <pad>等均需进行相应转换。<BOS>符号在第一个词前输入模型,表示句子的开头(Begin of Sentence)。当句子生成<EOS>(End of Sentence)时,表示句子结束。在生成每个词时,均需通过softmax,所以可以看作随着时间步,每向前走一步都做了一次以词汇表为大小,选择其一的分类问题,选择的是置信度最大的那个词。例如,10000个词的词汇表中,在当前时间步中预测到man这个词。
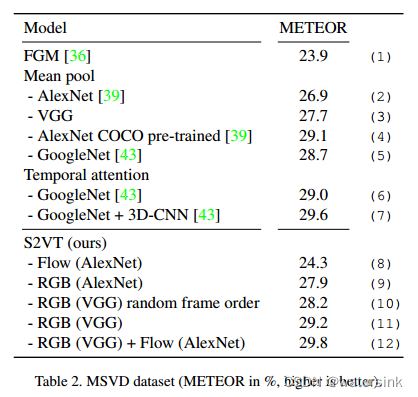
实验结果:




评论(0)
您还未登录,请登录后发表或查看评论