

许多 CUDA 内核受带宽限制,新硬件中触发器与带宽的比率增加导致更多带宽受限内核。 这使得采取措施缓解代码中的带宽瓶颈变得非常重要。 在本文中,我将向您展示如何在 CUDA C/C++ 中使用矢量加载和存储来帮助提高带宽利用率,同时减少执行指令的数量。
让我们从以下简单的内存复制内核开始。
__global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N; i += blockDim.x * gridDim.x) {
d_out[i] = d_in[i];
}
}
void device_copy_scalar(int* d_in, int* d_out, int N)
{
int threads = 128;
int blocks = min((N + threads-1) / threads, MAX_BLOCKS);
device_copy_scalar_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
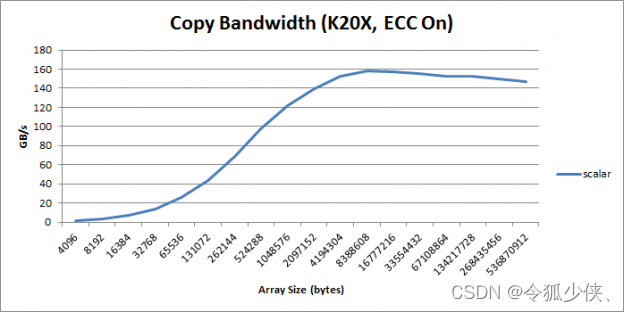
在此代码中,我使用了grid-stride loops,如较早的 earlier CUDA Pro Tip post. 中所述。 图 1 显示了以 GB/s 为单位的内核吞吐量作为 copy size的函数。
Figure 1: Copy bandwidth as a function of copy size
我们可以使用 CUDA 工具包中包含的 cuobjdump 工具检查此内核的程序集。
cuobjdump 从 CUDA 二进制文件(独立的和嵌入在主机二进制文件中的文件)中提取信息,并以人类可读的格式呈现它们。 cuobjdump 的输出包括每个内核的 CUDA 汇编代码、CUDA ELF 部分标题、字符串表、重定位器和其他 CUDA 特定部分。 它还从主机二进制文件中提取嵌入的 ptx 文本。
有关每个 GPU 架构的 CUDA 汇编指令集的列表,请参阅指令集参考。
%> cuobjdump -sass executable
scalar copy kernel主体的 SASS 如下:
/*0058*/ IMAD R6.CC, R0, R9, c[0x0][0x140]
/*0060*/ IMAD.HI.X R7, R0, R9, c[0x0][0x144]
/*0068*/ IMAD R4.CC, R0, R9, c[0x0][0x148]
/*0070*/ LD.E R2, [R6]
/*0078*/ IMAD.HI.X R5, R0, R9, c[0x0][0x14c]
/*0090*/ ST.E [R4], R2
在这里我们可以看到总共有六个与复制操作相关的指令。四个 IMAD指令计算加载和存储地址,LD.E 和 ST.E 从这些地址加载和存储 32 位。
我们可以通过使用矢量化加载和存储指令 LD.E.{64,128} 和ST.E.{64,128}来提高此操作的性能。这些操作还加载和存储数据,但以 64 位或 128位宽度执行。使用矢量化加载可减少指令总数、减少延迟并提高带宽利用率。
使用向量化加载的最简单方法是使用 CUDA C/C++ 标准头文件中定义的向量数据类型,例如 int2、int4 或 float2。您可以通过 C/C++中的类型转换轻松使用这些类型。例如,在 C++ 中,您可以使用 reinterpret_cast<int2*>(d_in) 将 int 指针 d_in 重铸为 int2 指针。在 C99 中,您可以使用转换运算符来做同样的事情:(int2*(d_in))。
取消引用这些指针将导致编译器生成矢量化指令。但是,有一个重要警告:这些指令需要对齐的数据。设备分配的内存自动对齐到数据类型大小的倍数,但如果您偏移指针,偏移量也必须对齐。例如,reinterpret_cast<int2*>(d_in+1) 无效,因为 d_in+1 未与 sizeof(int2) 的倍数对齐。
如果使用“对齐”偏移量,则可以安全地偏移数组,如 reinterpret_cast<int2*>(d_in+2)。您还可以使用结构生成矢量化负载,只要该结构的大小是两个字节的幂。
struct Foo {int a, int b, double c}; // 16 bytes in size
Foo *x, *y;
…
x[i]=y[i];
现在我们已经了解了如何生成向量化指令,让我们修改内存复制内核以使用向量加载。
__global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N/2; i += blockDim.x * gridDim.x) {
reinterpret_cast<int2*>(d_out)[i] = reinterpret_cast<int2*>(d_in)[i];
}
// in only one thread, process final element (if there is one)
if (idx==N/2 && N%2==1)
d_out[N-1] = d_in[N-1];
}
void device_copy_vector2(int* d_in, int* d_out, int n) {
threads = 128;
blocks = min((N/2 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector2_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
这个内核只有一些变化。 首先,循环现在只执行 N/2 次,因为每次迭代处理两个元素。 其次,我们在文案中使用了上面描述的铸造技术。 第三,我们处理 N 不能被 2 整除时可能出现的任何剩余元素。最后,我们启动的线程数是我们在标量内核中执行的线程数的一半。
检查 SASS 我们看到以下内容。
/*0088*/ IMAD R10.CC, R3, R5, c[0x0][0x140]
/*0090*/ IMAD.HI.X R11, R3, R5, c[0x0][0x144]
/*0098*/ IMAD R8.CC, R3, R5, c[0x0][0x148]
/*00a0*/ LD.E.64 R6, [R10]
/*00a8*/ IMAD.HI.X R9, R3, R5, c[0x0][0x14c]
/*00c8*/ ST.E.64 [R8], R6
请注意,现在编译器生成 LD.E.64 和 ST.E.64。 所有其他指令都是相同的。 但是,需要注意的是,执行的指令数量将减少一半,因为循环只执行了 N/2 次。 指令数的这种 2 倍改进在指令绑定或延迟绑定内核中非常重要。
我们也可以写一个vector4版本的copy kernel。
__global__ void device_copy_vector4_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) {
reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i];
}
// in only one thread, process final elements (if there are any)
int remainder = N%4;
if (idx==N/4 && remainder!=0) {
while(remainder) {
int idx = N - remainder--;
d_out[idx] = d_in[idx];
}
}
}
void device_copy_vector4(int* d_in, int* d_out, int N) {
int threads = 128;
int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector4_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
对应的SASS如下:
/*0090*/ IMAD R10.CC, R3, R13, c[0x0][0x140]
/*0098*/ IMAD.HI.X R11, R3, R13, c[0x0][0x144]
/*00a0*/ IMAD R8.CC, R3, R13, c[0x0][0x148]
/*00a8*/ LD.E.128 R4, [R10]
/*00b0*/ IMAD.HI.X R9, R3, R13, c[0x0][0x14c]
/*00d0*/ ST.E.128 [R8], R4
这里我们可以看到生成的LD.E.128和ST.E.128。 此版本的代码将指令数减少了 4 倍。您可以在图 2 中看到所有 3 个内核的整体性能。
Figure 2: Copy bandwidth as a function of copy size for vectorized kernels.
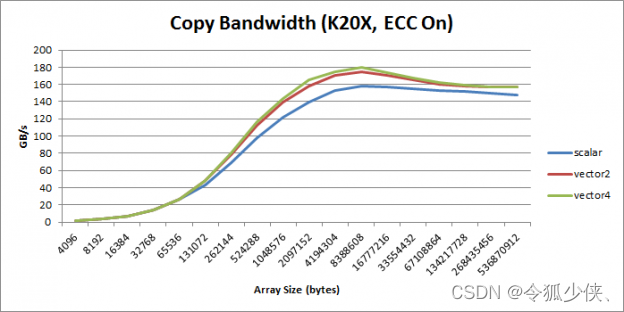
在几乎所有情况下,矢量化负载都优于标量负载。 但是请注意,使用矢量化加载会增加寄存器压力并降低整体并行度。 因此,如果您的内核已经受到寄存器限制或并行度非常低,您可能希望坚持使用标量加载。 此外,如前所述,如果您的指针未对齐或您的数据类型大小(以字节为单位)不是 2 的幂,则您不能使用矢量化加载。
矢量化加载是一种基本的 CUDA 优化,您应该尽可能使用它,因为它们可以增加带宽、减少指令数并减少延迟。 在这篇文章中,我展示了如何通过相对较少的更改轻松地将矢量化负载合并到现有内核中。
参考:
")


评论(0)
您还未登录,请登录后发表或查看评论