

本文章将介绍 DI-engine 中用于高效构建和标准化不同类型决策环境的系列工具,从而方便我们将各式各样的原始决策问题转化为适合使用强化学习方法解决的形式。
前言
对于“决策环境复杂性”的问题,这里描述的是在强化学习(RL)领域中,如何处理和简化复杂决策环境的挑战。决策环境可以非常广泛,包括虚拟世界的视频游戏、现实世界的棋类游戏、自动驾驶等场景。所有这些环境都有一个共同点:需要智能体(agent)在其中做出一系列决策。为了使这些环境适用于强化学习,必须将它们转化为标准的马尔可夫决策过程(MDP),这需要对环境的各个方面(如观测、动作和奖励)进行预处理和变换。
为什么要进行预处理&环境的复杂性:
-
复杂性:实际问题的复杂性导致了预处理步骤的必要性。在没有预处理的情况下,原始的决策问题可能无法直接应用现有的RL算法。
-
多样性:不同类型的决策问题需要不同的预处理方法。这增加了学习和转移这些技术的成本,因为每个新问题可能需要一套全新的预处理策略。
-
缺乏标准化:许多预处理技术(如one-hot编码、位置编码等)分散在不同的代码库中,没有统一的管理和标准化。
- 复杂的状态空间:环境状态可以非常复杂,包含大量的信息,可能是高维的、连续的,或者包含许多不同类型的数据。 -
多样化的动作空间:动作可能是离散的,如棋类游戏中的不同走法;也可能是连续的,如自动驾驶中的方向盘角度和油门控制。
-
动态变化的环境:环境可能会随时间变化,如多人游戏中其他玩家的策略变化或现实世界的交通条件变化。
-
不同的奖励机制:环境中的奖励可能是立即的,也可能是延迟的,而且其大小和频率可能会根据任务的不同而有很大差异。
预处理技术的示例:
One-hot 编码
目的:One-hot 编码是用来处理离散类别信息的一种方法,它将每个类别转换为一个稀疏的二进制向量。这种表示方法为每个类别分配一个独立的维度,使得模型能够更清晰地区分不同的类别,而不是将它们视为数值上的连续性。
示例:例如,假设我们有一个类别特征,它有三个可能的值:猫、狗、鸟。在one-hot编码中,猫可以被编码为[1, 0, 0],狗为[0, 1, 0],鸟为[0, 0, 1]。这样,每个类别都有一个对应的向量,其中一个元素为1表示类别,其余为0。
Position encoding
目的:位置编码用于给序列数据添加位置信息,这对于序列模型如RNN和Transformer非常重要,因为它们需要使用元素的顺序信息来做出预测。
示例:在实施位置编码时,可以使用一系列三角函数(如正弦和余弦)来为序列中的每个位置生成一个唯一的编码,或者通过模型学习得到位置的表示。
Discretization
目的:离散化是将连续的状态或动作空间转换为离散空间的过程。这在强化学习中很常见,因为许多算法更擅长处理离散动作。
示例:将连续空间划分为几个离散的区间(或“桶”),每个区间有一个代表值。例如,车速的连续范围可以划分为“低速”、“中速”和“高速”。
Normalization
目的:数据归一化是将数据缩放到一个共同的范围内的过程,例如[0, 1]或[-1, 1]。这有助于加快模型的收敛速度并提高性能。
示例:常见的归一化方法包括最小-最大归一化和Z得分归一化。前者将数据缩放到0和1之间,后者则将数据转换为均值为0,标准差为1的分布。
Abs->rel (Absolute to Relative)
目的:转换绝对位置信息为相对位置信息可以帮助模型更容易地学习移动和位置变化。
示例:例如,如果我们正在处理一个跟踪对象移动的问题,我们可以将对象的位置相对于前一帧来表示,而不是相对于整个场景的固定坐标系。
Padding & Mask & Resize
目的:对于变长的序列数据,需要统一长度以便模型可以处理。
示例:通过添加特殊的padding符号来增加序列长度,或者通过mask来指示哪些部分是有效的,哪些部分是填充的。在需要的情况下,也可以通过截断长序列来减少长度。
DI-engine 的解决方法
DI-engine 结合了 DI-zoo 中的实践经验,抽象出了两类重要的功能组件:环境包装器(Env Wrapper)和环境管理器(Env Manager)。这些组件的目的是为了更方便和高效地完成强化学习决策环境的预处理和标准化工作,这在接下来的内容中将会进行详细介绍。
环境包装器(Env Wrapper)
在训练决策智能体时,经常需要对环境的马尔可夫决策过程(MDP)定义进行预处理和转换,以期获得更好的训练效果。这些处理技巧在不同环境中有着一定的普适性。例如,观测状态的归一化是一个常见的预处理技巧,它通过统一量纲和缩小尺度使训练更快且更加稳定。
DI-engine 根据多种类型决策环境的实践经验,将一些通用的预处理流程集成到环境包装器中。具体来说,环境包装器就是在常见的 gym 格式环境之外附加相应的预处理模块,以便在保持原始环境特性的同时,方便地加入对于观测(obs)、动作(action)和奖励(reward)的预处理函数。
例如,创建一个 Atari Pong 环境并添加了一些预处理功能的代码片段可能如下所示:
env = gym.make('PongNoFrameskip-v4') # 创建 Atari Pong 环境
env = NoopResetEnv(env, noop_max=30) # 添加 episode 初始的空操作 Env Wrapper
env = MaxAndSkipEnv(env, skip=4) # 添加合并连续四个帧的 Env Wrapper
代码虽然短,我们也要认真对待,让我们逐行进行分析:
-
gym.make('PongNoFrameskip-v4'):这是gym库的调用,用于创建一个 Atari Pong 游戏的环境实例。PongNoFrameskip-v4是环境的标识符,其中 “NoFrameskip” 表示不跳过任何游戏帧,以确保环境以最原始和未经处理的形式提供每一帧。 -
NoopResetEnv(env, noop_max=30):NoopResetEnv是一种环境包装器,它在每个新的 episode 开始时执行一定数量的“空操作”(no-operations,即不进行任何动作)。noop_max=30参数指定了执行空操作的最大次数,这个随机数量的空操作使得游戏的初始状态更具随机性,有助于智能体学习更健壮的策略,因为它不能总是期待从同一初始状态开始。 -
MaxAndSkipEnv(env, skip=4):MaxAndSkipEnv是另一种环境包装器,它每skip帧返回一个状态,并且在这skip帧中选择最大像素值作为代表值。在这里skip=4意味着它将每 4 帧作为一个单元,从这 4 帧的像素数据中取最大值(通常用于消除画面闪烁的问题),然后只提供这个合并后的帧给智能体。这不仅有助于减少智能体需要处理的数据量,同时也加快了训练速度,因为较少的决策步骤需要在每个 episode 中被评估。
DI-engine 提供了一系列预定义且常用的 Env Wrapper,开发者可以根据自己的需求直接包裹在所需环境之上。这些 Env Wrapper 在实现时仍然遵循 Gym.Wrapper 格式,保证了与原有 gym 环境的兼容性和可扩展性。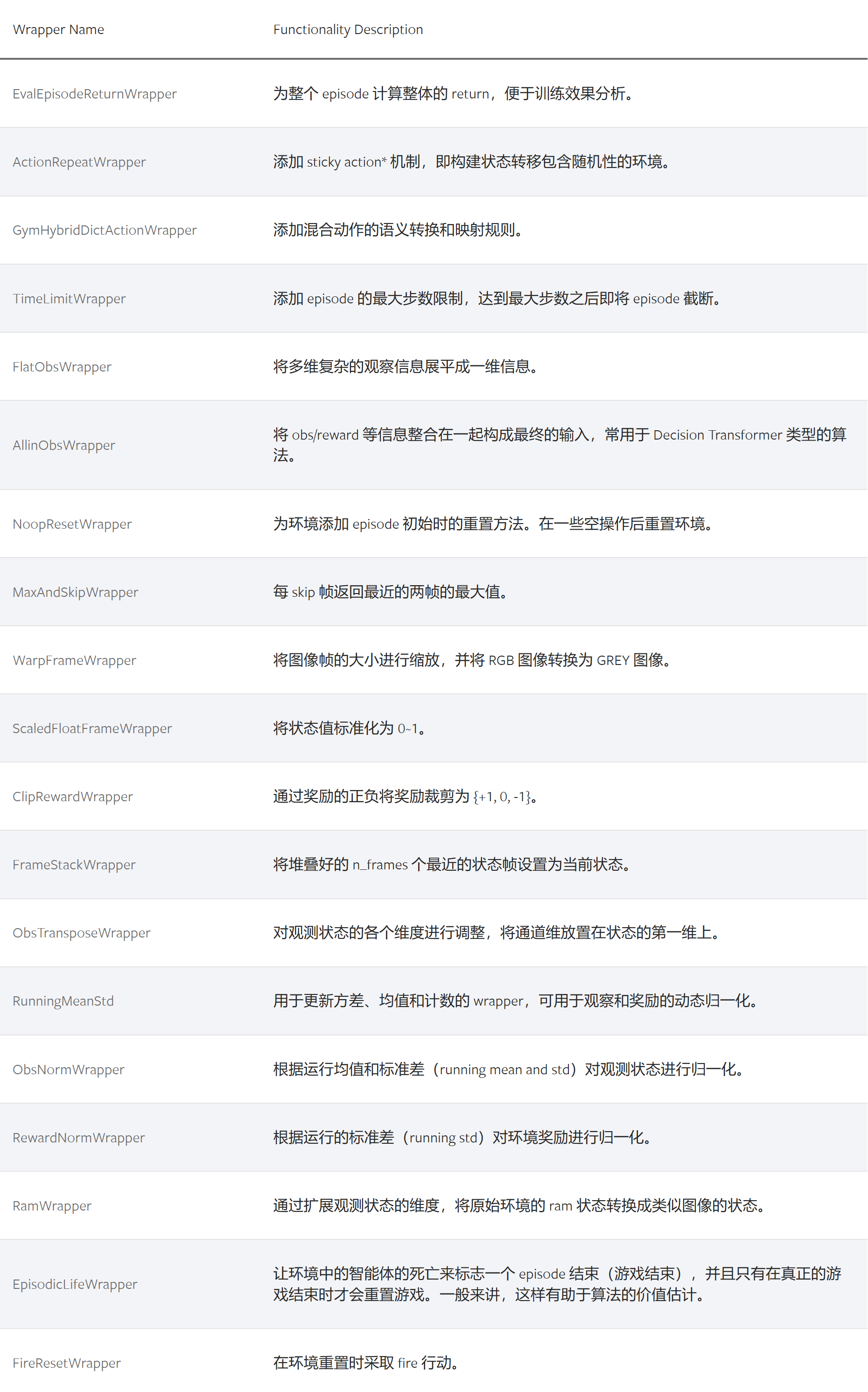
“sticky action” 机制通常是指在离散动作空间中的一种引入的技术,其中智能体在某些时间步上可能会执行与其选择的动作不同的动作。 这种机制的目的是模拟环境中的噪声或随机性,使得智能体需要更好地适应不确定性。
更进一步地,为了简化 Env Wrapper 的配置难度,为经典决策环境提供一键可用的默认 Env Wrapper 设置, 并直接做好相关的数据类型和接口转换(即从 gym 格式环境转换到 DI-engine 所需的 BaseEnv 衍生子环境), 这部分模块中还设计实现了一种更便利的调用方式 DingEnvWrapper,对应的使用示例如下:
import gym
from ding.envs import DingEnvWrapper
cartpole_env = DingEnvWrapper(gym.make('CartPole-v0'))
pendulum_env = DingEnvWrapper(gym.make('Pendulum-v1'))
lunarlander_env = DingEnvWrapper(cfg={'env_id': 'LunarLander-v2', env_wrapper='default'})
mujoco_env = DingEnvWrapper(cfg={'env_id': 'Ant-v3', env_wrapper='mujoco_default'})
atari_env = DingEnvWrapper(cfg={'env_id': 'PongNoFrameskip-v4', env_wrapper='atari_default'})
gym_hybrid_env = DingEnvWrapper(cfg={'env_id': 'Moving-v0', env_wrapper='gym_hybrid_default'})
这段代码展示了如何使用DingEnvWrapper,一个DI-engine中的工具,来包装和标准化不同类型的gym环境。下面我们将逐行对这段代码进行详细分析:
导入模块
import gym
from ding.envs import DingEnvWrapper
import gym:导入OpenAI Gym库,这是一个广泛使用的强化学习环境库,提供了多种标准化的环境接口。from ding.envs import DingEnvWrapper:从DI-engine中导入DingEnvWrapper类,这是环境包装器,用于添加标准化和额外的预处理层到原始的gym环境。
创建并包装环境实例
cartpole_env = DingEnvWrapper(gym.make('CartPole-v0'))
gym.make('CartPole-v0'):创建了一个CartPole-v0环境实例,这是一个经典的强化学习任务,要求智能体控制一个竖直的杆让它不要倒。DingEnvWrapper(...):将CartPole环境实例包装在DingEnvWrapper中,以应用DI-engine中的一些默认设置和预处理,例如观测和动作空间的转换、奖励的标准化等。
包装其他环境
接下来的几行重复了类似的模式,为其他几种环境创建并应用了DingEnvWrapper:
pendulum_env = DingEnvWrapper(gym.make('Pendulum-v1'))
Pendulum-v1环境是一个倒立摆问题,要求智能体通过施加力来保持摆动的摆杆竖直。
lunarlander_env = DingEnvWrapper(cfg={'env_id': 'LunarLander-v2', env_wrapper='default'})
LunarLander-v2是一个登月任务,智能体需要控制着陆器安全着陆。
mujoco_env = DingEnvWrapper(cfg={'env_id': 'Ant-v3', env_wrapper='mujoco_default'})
Ant-v3来自MuJoCo物理引擎,是一个多足机器人运动任务,要求智能体控制一个仿生蚂蚁在环境中尽可能远的移动。
atari_env = DingEnvWrapper(cfg={'env_id': 'PongNoFrameskip-v4', env_wrapper='atari_default'})
PongNoFrameskip-v4是Atari 2600游戏Pong的一个版本,智能体需要在乒乓球游戏中击败对手。
gym_hybrid_env = DingEnvWrapper(cfg={'env_id': 'Moving-v0', env_wrapper='gym_hybrid_default'})
Moving-v0可能是一个自定义环境或者特定应用的环境,这里’gym_hybrid_default’表明它使用了一些混合动作空间或者其他特定于该环境的默认设置。
每一个DingEnvWrapper的调用都可以通过cfg参数传递一个配置字典,其中env_id指定了想要创建的环境,而env_wrapper指定了要应用的预处理类型。这样的设计使得DingEnvWrapper非常灵活,可以轻松适应不同类型和需求的环境。
向量化环境管理器(Env Manager)
向量化环境管理器(Env Manager)是DI-engine中设计用来提升强化学习训练效率的重要组件。在强化学习中,智能体(agent)需要与环境(environment)进行大量的实时交互来收集数据,用于训练和提升策略。传统的方法是在单一环境中运行多个episode,直到收集到足够量的数据。这种方法虽然直接,但效率低下,尤其是在数据需求量大时。
为了解决这一问题,DI-engine采用了向量化的方法。向量化环境管理器允许同时并行运行多个环境实例,每个实例运行在独立的计算资源上(比如不同的CPU核心),并且各自收集一部分数据。这样做的优势是明显的:它可以显著加速数据收集过程,因为多个环境实例可以同时进行,而不是顺序地一个接一个运行。
然而,在实际应用中,向量化环境管理器也面临一些挑战。例如,不同环境实例可能会有不同的运行时间、episode长度和数据包大小,如果简单地等待所有环境实例完成,可能会因为某些实例运行较慢而造成资源浪费,这就是所谓的“木桶效应”。针对这一问题,DI-engine提出了分组向量化的解决方案,将运行特性相似的环境分组管理,以减少等待时间。
此外,从工程实现的角度来看,Python的多进程库可能存在稳定性问题,且进程间通信的开销可能影响向量化的效益。为了克服这些问题,DI-engine集成了多种特性不同的环境管理器,包括: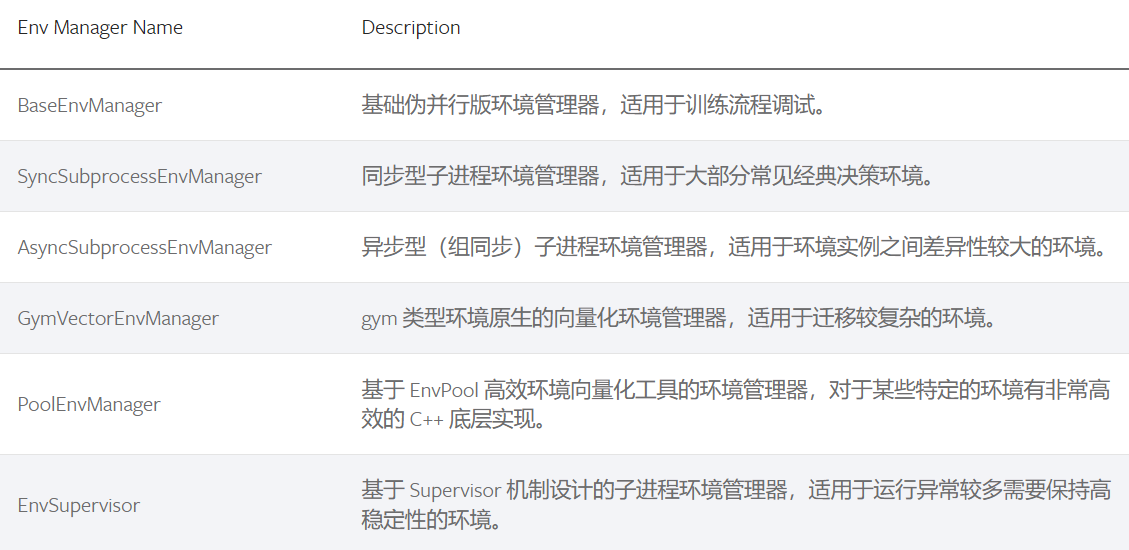



评论(0)
您还未登录,请登录后发表或查看评论