

强化学习实战-训练DDPG智能体进行自适应巡航
此示例显示了如何在Simulink®中训练用于确定性巡航控制(ACC)的深度确定性策略梯度(DDPG)智能体。
Simulink模型
此示例的强化学习环境是车辆和领头车的简单纵向动力学。训练的目标是通过控制纵向加速度和制动,使自车辆以设定的速度行驶,同时保持与领先车的安全距离。 指定两辆车的初始位置和速度。
x0_lead = 50; % initial position for lead car (m)
v0_lead = 25; % initial velocity for lead car (m/s)
x0_ego = 10; % initial position for ego car (m)
v0_ego = 20; % initial velocity for ego car (m/s)
指定静止默认间距(m),时间间隔(s)和驾驶员设定的速度(m / s)。
D_default = 10;
t_gap = 1.4;
v_set = 30;
为了模拟车辆动力学的物理限制,请将加速度限制在[–3,2] m / s ^ 2的范围内。
amin_ego = -3;
amax_ego = 2;
以秒为单位定义采样时间T_s和仿真持续时间T_f。
Ts = 0.1;
Tf = 60;
打开模型。
mdl = 'rlACCMdl';
open_system(mdl)
agentblk = [mdl '/RL Agent'];

对于此模型: 1.从智能体到环境的加速作用信号为–3至2 m / s ^ 2。 2.车的参考速度V_{ref}定义如下。如果相对距离小于安全距离,车跟踪的是前车速度和驾驶员设定的速度的最小值。通过这种方式,汽车与领先车保持一定的距离。如果相对距离大于安全距离,汽车会跟踪驾驶员设定的速度。在这个例子中,安全距离被定义为车纵向速度V的线性函数;即t_{gap} \times V+D_{default}。安全距离决定了汽车的参考跟踪速度。 3.从环境观测到的速度误差e=V_{ref} - V_{ego},它的积分为\int{e},汽车纵向速度为V。 4.当前车的纵向速度小于0或前车与前车的相对距离小于0时,仿真终止。 5.在每个时间步骤t提供的奖励r_t是 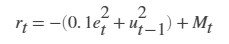 其中u_{t-1}是上一个时间步长的控制输入。当速度误差e^2_t <=0.25时,逻辑值M_t =1;否则,M_t =0。
其中u_{t-1}是上一个时间步长的控制输入。当速度误差e^2_t <=0.25时,逻辑值M_t =1;否则,M_t =0。
创建环境界面
为模型创建强化学习环境界面。 创建观察规范。
observationInfo = rlNumericSpec([3 1],'LowerLimit',-inf*ones(3,1),'UpperLimit',inf*ones(3,1));
observationInfo.Name = 'observations';
observationInfo.Description = 'information on velocity error and ego velocity';
创建动作规范。
actionInfo = rlNumericSpec([1 1],'LowerLimit',-3,'UpperLimit',2);
actionInfo.Name = 'acceleration';
创建环境界面。
env = rlSimulinkEnv(mdl,agentblk,observationInfo,actionInfo);
要定义引导车位置的初始条件,请使用匿名函数句柄指定一个环境重置函数。在示例末尾定义的重置函数localResetFcn将随机化领头车的初始位置。
env.ResetFcn = @(in)localResetFcn(in);
固定了随机生成器种子的再现性。
rng('default')
创建DDPG智能体
DDPG智能体使用批判器价值函数表示法,根据给定的观察和操作来估算长期奖励。 要创建批判器,首先要创建一个具有两个输入(状态和动作以及一个输出)的深度神经网络。
L = 48; % number of neurons
statePath = [
featureInputLayer(3,'Normalization','none','Name','observation')
fullyConnectedLayer(L,'Name','fc1')
reluLayer('Name','relu1')
fullyConnectedLayer(L,'Name','fc2')
additionLayer(2,'Name','add')
reluLayer('Name','relu2')
fullyConnectedLayer(L,'Name','fc3')
reluLayer('Name','relu3')
fullyConnectedLayer(1,'Name','fc4')];
actionPath = [
featureInputLayer(1,'Normalization','none','Name','action')
fullyConnectedLayer(L, 'Name', 'fc5')];
criticNetwork = layerGraph(statePath);
criticNetwork = addLayers(criticNetwork, actionPath);
criticNetwork = connectLayers(criticNetwork,'fc5','add/in2');
查看critical network配置信息。
plot(criticNetwork)

使用rlRepresentationOptions指定批判器表示的选项。
criticOptions = rlRepresentationOptions('LearnRate',1e-3,'GradientThreshold',1,'L2RegularizationFactor',1e-4);
使用指定的神经网络和选项创建批判器表示。 您还必须指定批判器的操作和观察信息,这些信息是从环境界面获得的。
critic = rlQValueRepresentation(criticNetwork,observationInfo,actionInfo,...
'Observation',{'observation'},'Action',{'action'},criticOptions);
DDPG智能体通过使用行动器表示来决定采取哪种行动。 要创建行动器,首先要创建一个具有一个输入(观察)和一个输出(动作)的深层神经网络。
actorNetwork = [
featureInputLayer(3,'Normalization','none','Name','observation')
fullyConnectedLayer(L,'Name','fc1')
reluLayer('Name','relu1')
fullyConnectedLayer(L,'Name','fc2')
reluLayer('Name','relu2')
fullyConnectedLayer(L,'Name','fc3')
reluLayer('Name','relu3')
fullyConnectedLayer(1,'Name','fc4')
tanhLayer('Name','tanh1')
scalingLayer('Name','ActorScaling1','Scale',2.5,'Bias',-0.5)];
actorOptions = rlRepresentationOptions('LearnRate',1e-4,'GradientThreshold',1,'L2RegularizationFactor',1e-4);
actor = rlDeterministicActorRepresentation(actorNetwork,observationInfo,actionInfo,...
'Observation',{'observation'},'Action',{'ActorScaling1'},actorOptions);
要创建DDPG智能体,请首先使用rlDDPGAgentOptions指定DDPG智能体选项。
agentOptions = rlDDPGAgentOptions(...
'SampleTime',Ts,...
'TargetSmoothFactor',1e-3,...
'ExperienceBufferLength',1e6,...
'DiscountFactor',0.99,...
'MiniBatchSize',64);
agentOptions.NoiseOptions.Variance = 0.6;
agentOptions.NoiseOptions.VarianceDecayRate = 1e-5;
然后,使用指定的行动器表示,批判器表示和智能体选项创建DDPG智能体。
agent = rlDDPGAgent(actor,critic,agentOptions);
训练智能体
要训练智能体,请首先指定训练选项。 对于此示例,使用以下选项: 1.每个训练episode 最多运行5000个 episodes ,每个 episode 最多持续600个时间步。 2.在“Episode Manager”对话框中显示训练进度。 3.当智能体收到的 episode 奖励大于260时,停止训练。
maxepisodes = 5000;
maxsteps = ceil(Tf/Ts);
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','EpisodeReward',...
'StopTrainingValue',260);
使用Train函数对智能体进行训练。训练是一个计算密集型的过程,需要几分钟才能完成。为了在运行这个示例时节省时间,可以通过将doTraining设置为false来加载一个预先训练过的智能体。要自己训练智能体,请将doTraining设置为true。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainingOpts);
else
% Load a pretrained agent for the example.
load('SimulinkACCDDPG.mat','agent')
end

DDPG智能体仿真
要验证训练过的智能体的性能,可以通过取消注释以下命令在Simulink环境中仿真智能体。
% simOptions = rlSimulationOptions('MaxSteps',maxsteps);
% experience = sim(env,agent,simOptions);
为了使用确定的初始条件来演示训练好的agent,在Simulink中模拟模型。
x0_lead = 80;
sim(mdl)
下面的图展示了前导车领先后面汽车70 (m)时的仿真结果。 1.在开始的28秒内,相对距离大于安全距离(下图),因此汽车会跟踪设定的速度(中图)。 为了加速并达到设定的速度,加速度为正(上图)。 2.在28到60秒之间,相对距离小于安全距离(下图),因此,汽车会追踪领先速度和设定速度中的最小值。 在28到36秒之间,超前速度小于设定的速度(中间图)。 要减慢并跟踪有轨车的速度,加速度为负(上图)。 在36到60秒之间,汽车会调整其加速度以密切跟踪参考速度(中间图)。 在此时间间隔内,跟踪车将设定速度从43
秒调至52秒,并将领先速度从36秒调至43秒和52秒至60秒。



关闭Simulink模型。
bdclose(mdl)
重置函数
function in = localResetFcn(in)
% Reset the initial position of the lead car.
in = setVariable(in,'x0_lead',40+randi(60,1,1));
end



评论(2)
您还未登录,请登录后发表或查看评论