

目录
一、决策树是啥?
二、决策树的工作原理
三、机器学习应用:Sklearn中的DecisionTreeClassifier
四、如何选择正则化超参数
五、总结
一、决策树是啥?
顾名思义,我们很直观地知道决策树的基本意义,就是当面临多种选择的时候,我们需要做出决策,根据生活经验,做出决策之前会考虑方方面面,目的就是做出最佳的决策结果。举个例子,我们通过一个公司的面试考核,在接受offer之前,会考虑一些因素如:薪资、未来发展、公司文化、交通情况等等。这时候,根据每个因素的权重综合考虑是否接受offer的决策。
上面讲了决策树在实际场景中的意义,相信大家可以很好理解了,现在介绍一下比较官方的意思,来理解决策树的含义。
决策树(decision tree)是一种有监督学习方法。它是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。决策树既可用于分类也可以用于回归。
实现的算法也有许多,但归根结底都是以树结构形式,每个分支是一种结果表示。具体的决策树算法:CART、ID3、C4.5;还有一些特殊的决策树,如随机森林(random forest)、斜树、演化树等。
不了解具体算法的实现没关系,基本原理懂得之后,看算法就是一些公式上的计算以及演化过程。
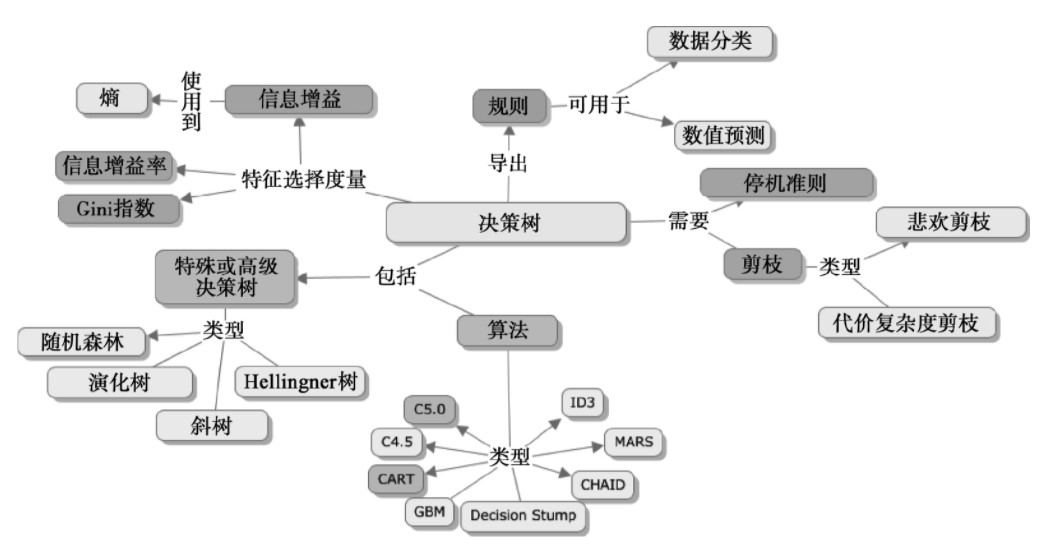
上图(来源:百度百科)基本包含了整个决策树的体系,其中许多重要概念比如:熵、信息增益、Gini指数等,有兴趣可以详细了解,这是实现算法的重要概念。
二、决策树的工作原理
因为决策树是一种有监督的方法,还是拿前面举的例子:是否接受offer。对于薪资、未来发展、公司文化、交通情况这些因素的判断,我们也需要从经验上讨论。
同样的,决策树需要先从数据中学习,来形成一棵有许多条件属性的树,所以它的工作原理就是:
- 通过从根节点到叶子节点遍历一个树形结构来对数据实例来分类。可以这样理解,决策树由两种元素构成:节点以及连接节点的边。
- 决策流程如下:从根节点开始,在每个节点选择一条边,跳转到下一个节点,直到抵达叶子节点,做出决策。
- 每个节点代表对一个具体特征(条件属性)的判断,而分支代表该特征的各种不同特征值。

三、机器学习应用:Sklearn中的DecisionTreeClassifier
讲了这么多决策树基本原理层面的内容,到了实践学习的时候了。sklearn真是机器学习中功能很强大的库,包含了大部分机器学习算法的封装实现,现在我们使用其中的决策树分类器来对iris数据集进行分类,原理懂了之后实践会得心应手。
"""
encoding: utf-8
@author: Charzous
@license: Copyright © 2021 Charzous
@software: Pycharm
@file: decision_tree_demo.py
@time: 2021-06-01 下午 08:17
"""
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import matplotlib.pyplot as plt
import pandas as pd
iris = load_iris()
X = iris.data[:, 2:]
y = iris.target
decision_tree = DecisionTreeClassifier(max_depth=2)
decision_tree.fit(iris.data, y)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(url, names=names)
# 获取花卉两列数据集
pos = pd.DataFrame(dataset)
L1 = pos['sepal-length'].values
L2 = pos['sepal-width'].values
predict=decision_tree.predict(iris.data)
plt.scatter(L1, L2, c=predict, marker='x')
plt.xlabel('sepal-length')
plt.ylabel('sepal-width')
plt.title("DTC")
plt.show()
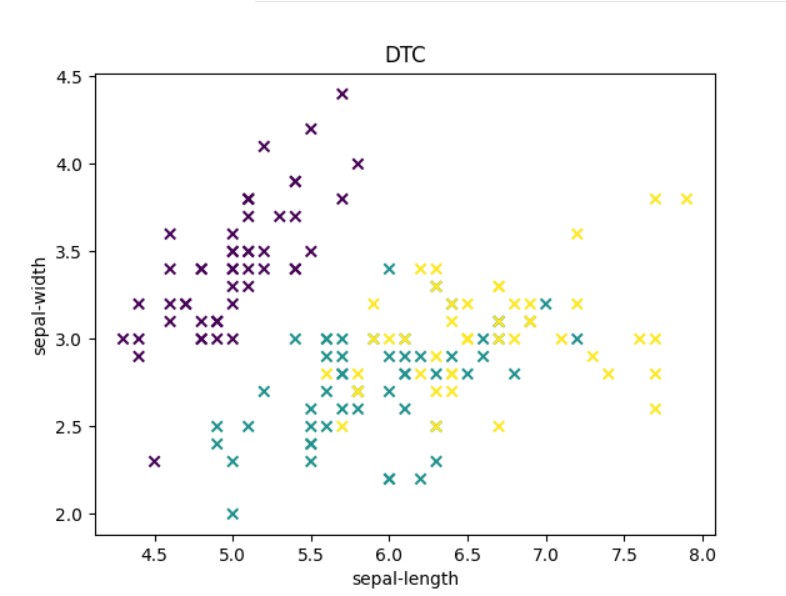
这是得到的决策区域结果。
将数据集以7:3划分为训练集和测试集,使用决策树模型预测,得到精确率、召回率、f1-score等指标如下:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 0.83 0.94 0.88 16
2 0.94 0.84 0.89 19
accuracy 0.91 45
macro avg 0.92 0.93 0.92 45
weighted avg 0.92 0.91 0.91 45
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
decision_tree.fit(x_train, y_train)
predict_target = decision_tree.predict(x_test)
print(metrics.classification_report(y_test, predict_target))
print(metrics.confusion_matrix(y_test, predict_target))另外,可以通过可视化决策选择,查看决策树的分类依据。
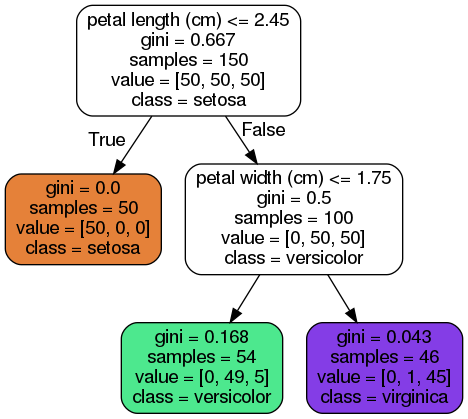
上图就是决策树对iris数据集做出的预测。
我们可以分析一下,对于一朵鸢尾花,想要将其归类,那么从根节点(深度0,位于顶部)开始:这朵花的花瓣长度是否小于2.45厘米?如果是,则向下移动到根的左侧子节点(深度1,左)。本例中,这是一个叶节点(即没有任何子节点),所以它不再继续提出问题,你可以直接查看这个节点的预测类别,也就是说,决策树预测你的这朵花是Setosa鸢尾花(class=setosa)。
通过分析可以很直观看出决策树的工作过程,也符合上面讲解的原理部分。
四、如何选择正则化超参数
上面简单的实践基本学会了决策树分类器的使用,其实我们目前用的都是默认参数,对于实际应用中,通常需要正则化、调参等操作让模型拟合效果达到最佳。一些正则化方法以及超参的选择可以参考以下内容。
- 为避免过度拟合,需要在训练过程中降低决策树的自由度,这个过程被称为正则化。正则化超参数的选择取决于你所使用的模型,但是通常来说,至少可以限制决策树的最大深度。在Scikit-Learn中,这由超参数max_depth控制(默认值为None,意味着无限制)。减小max_depth可使模型正则化,从而降低过度拟合的风险。
- DecisionTreeClassifier类还有一些其他的参数,同样可以限制决策树的形状:min_samples_split(分裂前节点必须有的最小样本数),min_samples_leaf(叶节点必须有的最小样本数量),min_weight_fraction_leaf(跟min_samples_leaf一样,但表现为加权实例总数的占比),max_leaf_nodes(最大叶节点数量),以及max_features(分裂每个节点评估的最大特征数量)。增大超参数min_*或是减小max_*将使模型正则化。
五、总结
在此之前,我总结记录了一篇决策树的实战,《多分类器集成学习:多数票机制、Bagging、Adaboost实例分析》,感兴趣的伙伴可以查看,偏向实践更加有趣!
这一篇聊聊 决策树 的详细内容,了解其原理来龙去脉,通过简单入门项目深入浅出。决策树(decision tree)是一种有监督学习方法,既可用于分类也可以用于回归。
如果觉得不错欢迎三连,点赞收藏关注,一起加油进步!原创作者:Charzous.



评论(0)
您还未登录,请登录后发表或查看评论