

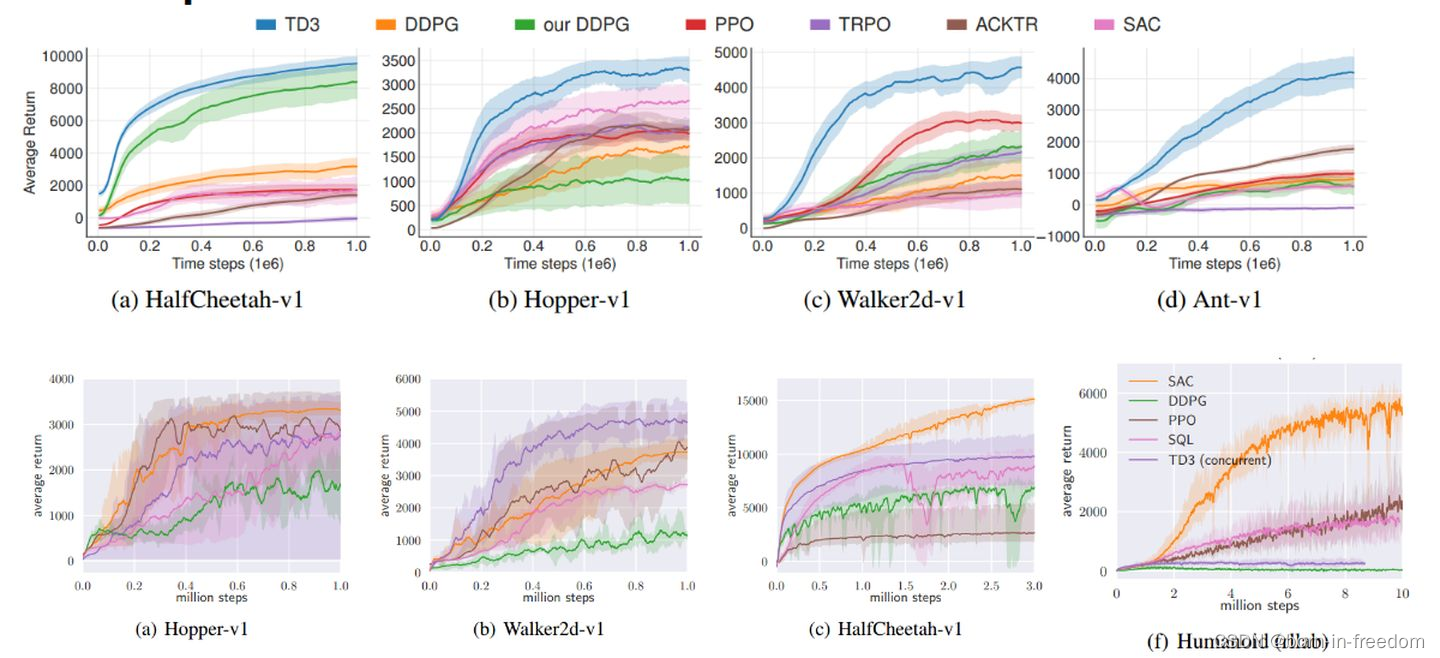
看到强化学习论文里面这种漂亮的图是不很羡慕。今天就是来看看这种画法。上面这些图中,线条两侧的填充区是置信区间,因为在一个x坐标轴的位置,有很多不同的y值对应,画图程序会自动计算估计的中间值来画线,同时自己添加上置信区间。
今天要说的是seaborn这个库,它虽然基于matplotlib,但是提供了更多的画图功能。Seaborn是Python中使用最广泛的数据可视化库之一,是Matplotlib的扩展。它为数据可视化提供了一个简单、直观但高度可定制的API。本篇文章主要讲解lineplotAPI。
先来个最基础的
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
x=[1,2,3,4,5]
y=[1,5,4,7,4]
sns.lineplot(x,y)
plt.show()
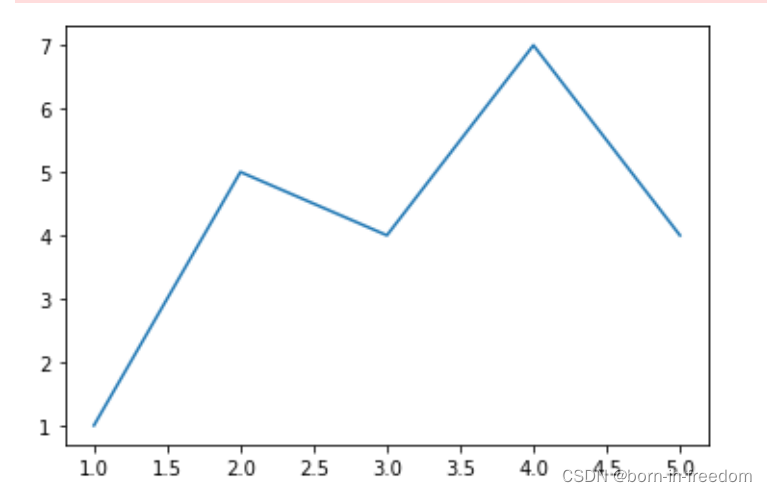
我们直接通过两个list来作图,可以看到图像,这个挺简单的。
我们在上面的程序当中修改一点点,添加一个控制seaborn画图主题的语句
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#控制图的主题
sns.set_theme(style="darkgrid")
x=[1,2,3,4,5]
y=[1,5,4,7,4]
sns.lineplot(x,y)
plt.show()
这时候画出的图就是这样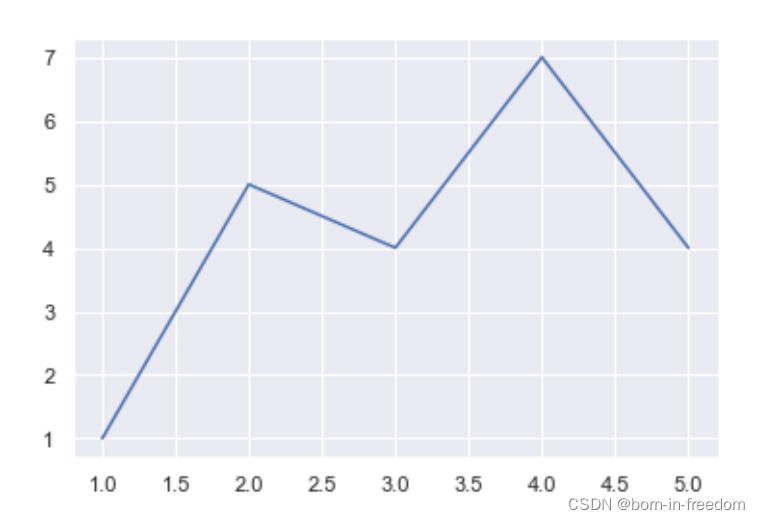
下面我们用一个比较复杂的数据来画图,我们使用kaggle上一个酒店房间预定的数据,数据和本篇文章的代码都可以从这个链接获取,https://www.jianguoyun.com/p/Ddc6RhEQnNm0CRjc2aAE。
我们首先将数据读取出来,
df=pd.read_csv('hotel_bookings.csv')
print(df.head())
hotel is_canceled lead_time arrival_date_year arrival_date_month \
0 Resort Hotel 0 342 2015 July
1 Resort Hotel 0 737 2015 July
2 Resort Hotel 0 7 2015 July
3 Resort Hotel 0 13 2015 July
4 Resort Hotel 0 14 2015 July
arrival_date_week_number arrival_date_day_of_month \
0 27 1
1 27 1
2 27 1
3 27 1
4 27 1
stays_in_weekend_nights stays_in_week_nights adults ... deposit_type \
0 0 0 2 ... No Deposit
1 0 0 2 ... No Deposit
2 0 1 1 ... No Deposit
3 0 1 1 ... No Deposit
4 0 2 2 ... No Deposit
agent company days_in_waiting_list customer_type adr \
0 NaN NaN 0 Transient 0.0
1 NaN NaN 0 Transient 0.0
2 NaN NaN 0 Transient 75.0
3 304.0 NaN 0 Transient 75.0
4 240.0 NaN 0 Transient 98.0
required_car_parking_spaces total_of_special_requests reservation_status \
0 0 0 Check-Out
1 0 0 Check-Out
2 0 0 Check-Out
3 0 0 Check-Out
4 0 1 Check-Out
reservation_status_date
0 2015-07-01
1 2015-07-01
2 2015-07-02
3 2015-07-02
4 2015-07-03
[5 rows x 32 columns]
他有非常多的行和列,在这里没有显示完全。
我们这里主要看两个数据,一个是arrival_date_month,一个是stays_in_week_nights,分别表示客人到来的月份和住的时间。使用seaborn的lineplot的时候,调用API的方式有点不一样,这里x和y是直接指定我们数据的索引,x这里就是df['arrival_date_month']这个数据,最后通过data参数来指定我们要传入的数据。
sns.lineplot(x="arrival_date_month",y="stays_in_week_nights",data=df)
plt.show()
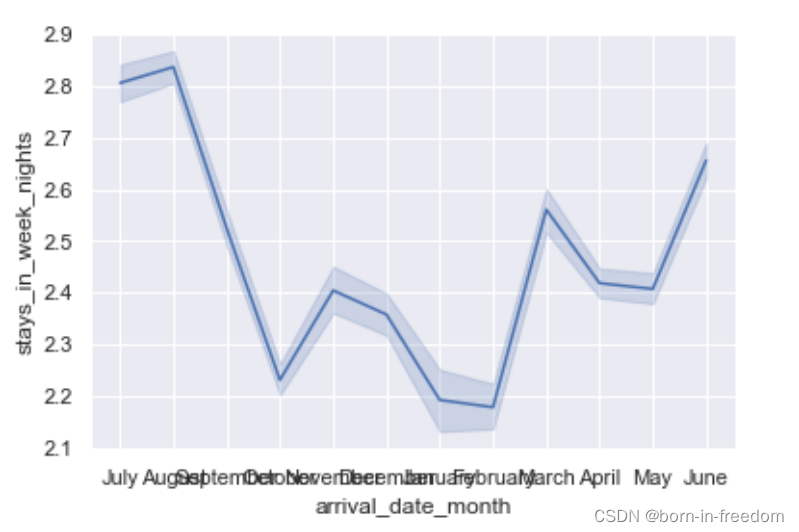
画出的图就是这样。我们可以清楚地看到,6月、7月和8月(暑假)的工作日停留时间往往较长,而1月和2月的停留时间最低,正好在新年之前的一系列假期之后。
此外,也可以看到置信区间(线本身周围的区域),这是seaborn估计的我们给的数据的中心值的一个趋势,这是因为每个x值有多个y值(每个月有许多人停留),Seaborn计算这些记录的中心趋势,并绘制该线,以及该趋势的置信区间。
一般来说,人们在7月的工作日停留约2.8天,但置信区间在2.78-2.84之间。
下面来看一个更加复杂的例子。我们希望将几个月内的住宿情况可视化,但我们也希望将入住年份考虑在内。这时候画图需要将月份、年份和入住情况三个数据都表示在图上。
我们首先对数据进行一下处理。
我们将df数据简化一下,提取出我们关心的数据。
df=df[['arrival_date_year','arrival_date_month','stays_in_week_nights']]
df
我们只关心这三个数据。
我们使用arrival_date_month作为排序规则
order=df['arrival_date_month']
order
然后,我们使用pivot_table,也就是透视图(excel中)来表示数据。关于pivot_table具体是怎么表示数据的,只需要跟着我们下面的代码走,就可以体会出来。
df_wide=df.pivot_table(index='arrival_date_month',columns='arrival_date_year',values='stays_in_week_nights')
df_wide
sns.lineplot(data=df_wide)
plt.show()
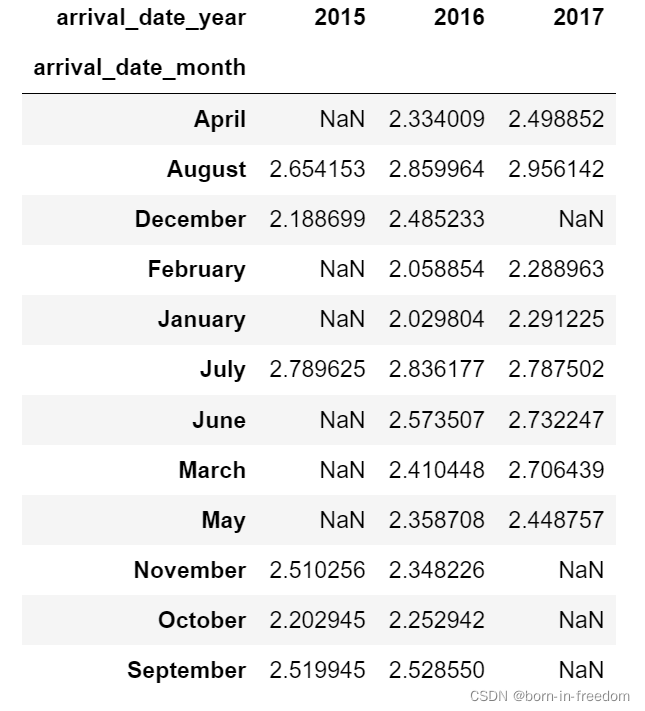
pivot_table的作用就是将我们设定的index作为索引,然后去匹配我们设定的列,我们设定的value值也就是中间部分要显示的内容。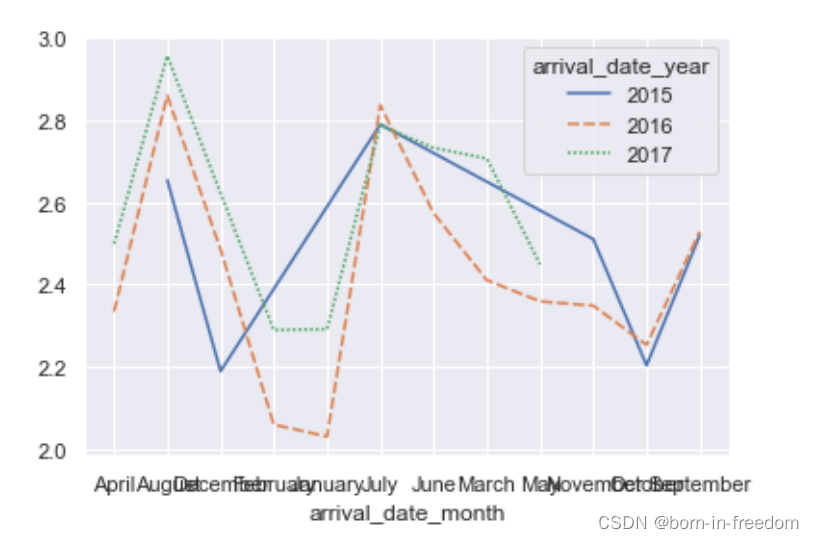
我们也可以按照在原始的csv文件中,arrival_date_month的顺序来画图,也就是上面我们设定的order=df['arrival_date_month']的作用。
df_wide=df_wide.reindex(order,axis=0)
df_wide

这时候,数据就是按照原始的csv文件中的顺序来组织的。
sns.lineplot(data=df_wide)
plt.plot()
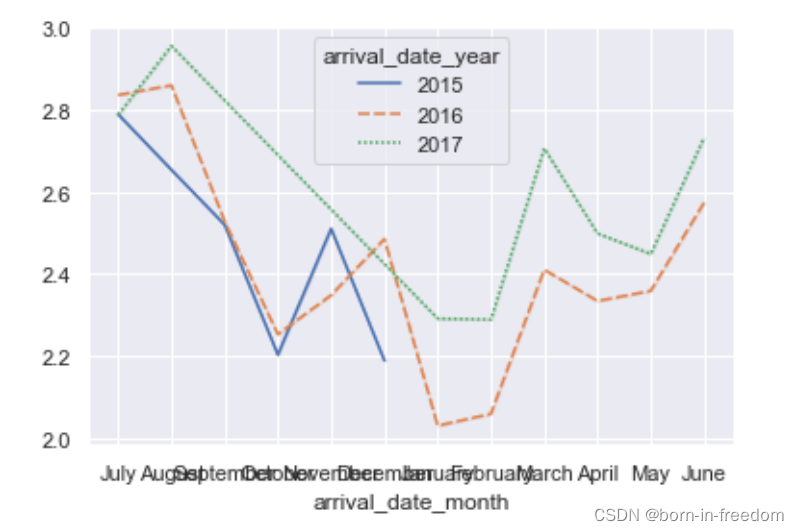
下面来看看控制颜色和其他一些特性的代码。
- 控制不同曲线的颜色
df=pd.read_csv('hotel_bookings.csv') sns.lineplot(x="arrival_date_month",y="stays_in_week_nights",hue="arrival_date_year",data=df) plt.plot()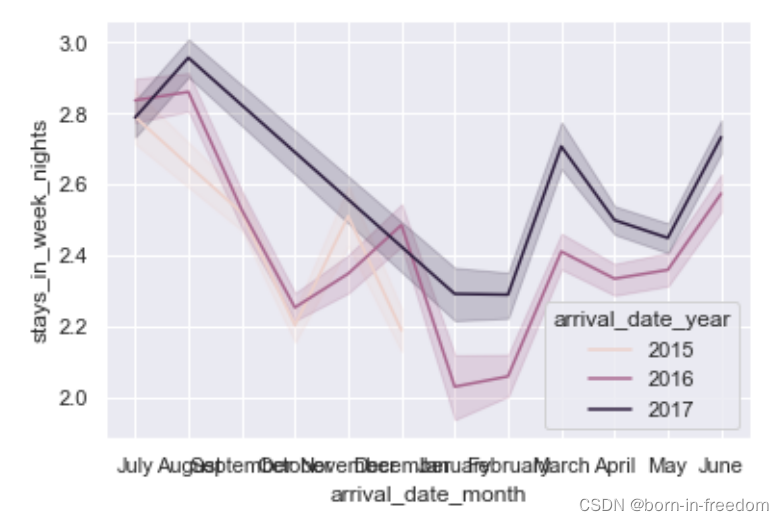
这时候seaborn会自动帮我们将每年的数据以不同的颜色表示出来。
sns.lineplot(x="arrival_date_month",y="stays_in_week_nights",hue="arrival_date_year",err_style="bars",data=df)
plt.plot()
还可以将置信区间的表示方式设置为线条。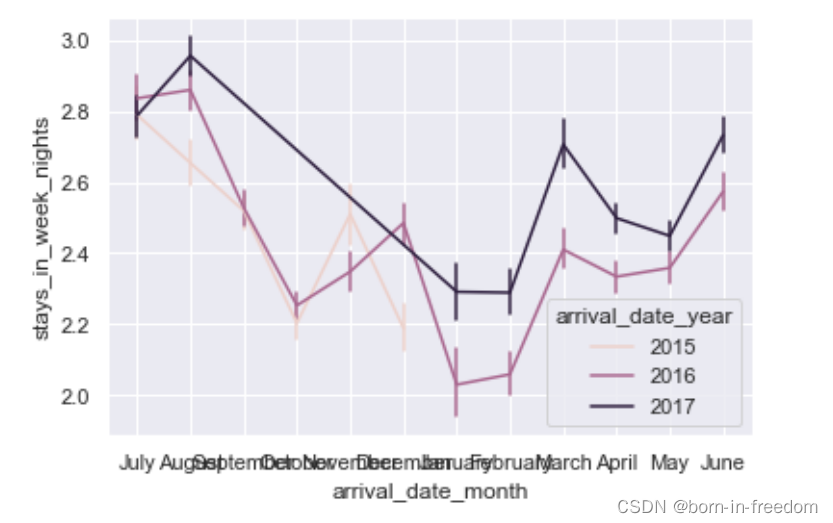
参考:
https://stackabuse.com/seaborn-line-plot-tutorial-and-examples/,
所有的数据和代码可以从这个链接获取https://www.jianguoyun.com/p/Ddc6RhEQnNm0CRjc2aAE



评论(0)
您还未登录,请登录后发表或查看评论