
内容列表
一、源码下载
源码下载:https://github.com/Qidian213/deep_sort_yolov3
该代码将下面的deep_sort与keras-yolo3相结合。项目中的demo虽然可以完美运行,但是更换成自己训练好的.h5模型就会报错,对比其中的yolo代码发现与keras-yolo3还是有一些不同,所以参照keras-yolo3对代码进行修改,以实现运行自己训练好的模型。
https://github.com/nwojke/deep_sort
https://github.com/qqwweee/keras-yolo3
下面是笔者的运行环境和安装的依赖,在版本下可成功运行。
运行环境
Window10
Cuda9.0
Python3.6
Pycharm + Anaconda
主要依赖
keras-gpu 2.24
tensorflow-gpu 1.12.0
opencv 3.3.1
pillow 6.2.1
numpy
scipy
pyyaml
sklearn
二、代码修改
下载yolo.h5后即可运行demo,通过笔记本自带摄像头实现对人(以及其他的物体)的识别与跟踪。
如果已经有训练好的.h5文件,则需要添加或修改以下文件。自己训练的.h5,自己定义的类,以及参照keras-yolo3对下面四个文件的修改。
model_data/yolo.h5
model_data/my_classes.txt
yolo3/model.py
yolo3/utils.py
yolo.py
yolov3.cfg
下面我们逐一尝试。
2.1 运行demo
可在YOLO网站下载yolo或tiny-yolo的权重。并通过python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5命令将YOLO模型转换为Keras模型。或则直接下载yolo.h5文件(被墙),并将其放入model_data目录下。
运行demo.py即可。
2.2 使用自己的h5
通过(【目标检测】YOLOv3目标检测使用自己的数据集详细流程)我已经训练出属于自己的模型,但是将其自己放入modal_data内,并修改yolo.py和yolov3.cfg的参数后运行demo.py报错。所以我依照keras-yolo3修改代码。
2.2.1 my_classes.txt
在model_data目录下创建my_classes.txt文件,并写入自己的分类。
2.2.2 model.py
修改yolo3目录下的model.py。
"""YOLO_v3 Model Defined in Keras."""
from functools import wraps
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from yolo3.utils import compose
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D."""
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
def resblock_body(x, num_filters, num_blocks):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters//2, (1,1)),
DarknetConv2D_BN_Leaky(num_filters, (3,3)))(x)
x = Add()([x,y])
return x
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
x = resblock_body(x, 1024, 4)
return x
def make_last_layers(x, num_filters, out_filters):
'''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer'''
x = compose(
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)))(x)
y = compose(
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D(out_filters, (1,1)))(x)
return x, y
def yolo_body(inputs, num_anchors, num_classes):
"""Create YOLO_V3 model CNN body in Keras."""
darknet = Model(inputs, darknet_body(inputs))
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])
def tiny_yolo_body(inputs, num_anchors, num_classes):
'''Create Tiny YOLO_v3 model CNN body in keras.'''
x1 = compose(
DarknetConv2D_BN_Leaky(16, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(32, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(64, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(128, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(256, (3,3)))(inputs)
x2 = compose(
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(512, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(1,1), padding='same'),
DarknetConv2D_BN_Leaky(1024, (3,3)),
DarknetConv2D_BN_Leaky(256, (1,1)))(x1)
y1 = compose(
DarknetConv2D_BN_Leaky(512, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))(x2)
x2 = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x2)
y2 = compose(
Concatenate(),
DarknetConv2D_BN_Leaky(256, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))([x2,x1])
return Model(inputs, [y1,y2])
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
"""Convert final layer features to bounding box parameters."""
num_anchors = len(anchors)
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2])
grid_shape = K.shape(feats)[1:3] # height, width
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]),
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats))
feats = K.reshape(
feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])
# Adjust preditions to each spatial grid point and anchor size.
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
if calc_loss == True:
return grid, feats, box_xy, box_wh
return box_xy, box_wh, box_confidence, box_class_probs
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape):
'''Get corrected boxes'''
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape-new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([
box_mins[..., 0:1], # y_min
box_mins[..., 1:2], # x_min
box_maxes[..., 0:1], # y_max
box_maxes[..., 1:2] # x_max
])
# Scale boxes back to original image shape.
boxes *= K.concatenate([image_shape, image_shape])
return boxes
def yolo_boxes_and_scores(feats, anchors, num_classes, input_shape, image_shape):
'''Process Conv layer output'''
box_xy, box_wh, box_confidence, box_class_probs = yolo_head(feats,
anchors, num_classes, input_shape)
boxes = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape)
boxes = K.reshape(boxes, [-1, 4])
box_scores = box_confidence * box_class_probs
box_scores = K.reshape(box_scores, [-1, num_classes])
return boxes, box_scores
def yolo_eval(yolo_outputs,
anchors,
num_classes,
image_shape,
max_boxes=20,
score_threshold=.6,
iou_threshold=.5):
"""Evaluate YOLO model on given input and return filtered boxes."""
num_layers = len(yolo_outputs)
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]] # default setting
input_shape = K.shape(yolo_outputs[0])[1:3] * 32
boxes = []
box_scores = []
for l in range(num_layers):
_boxes, _box_scores = yolo_boxes_and_scores(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
boxes = K.concatenate(boxes, axis=0)
box_scores = K.concatenate(box_scores, axis=0)
mask = box_scores >= score_threshold
max_boxes_tensor = K.constant(max_boxes, dtype='int32')
boxes_ = []
scores_ = []
classes_ = []
for c in range(num_classes):
# TODO: use keras backend instead of tf.
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
nms_index = tf.image.non_max_suppression(
class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold)
class_boxes = K.gather(class_boxes, nms_index)
class_box_scores = K.gather(class_box_scores, nms_index)
classes = K.ones_like(class_box_scores, 'int32') * c
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = K.concatenate(boxes_, axis=0)
scores_ = K.concatenate(scores_, axis=0)
classes_ = K.concatenate(classes_, axis=0)
return boxes_, scores_, classes_
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
'''Preprocess true boxes to training input format
Parameters
----------
true_boxes: array, shape=(m, T, 5)
Absolute x_min, y_min, x_max, y_max, class_id relative to input_shape.
input_shape: array-like, hw, multiples of 32
anchors: array, shape=(N, 2), wh
num_classes: integer
Returns
-------
y_true: list of array, shape like yolo_outputs, xywh are reletive value
'''
assert (true_boxes[..., 4]<num_classes).all(), 'class id must be less than num_classes'
num_layers = len(anchors)//3 # default setting
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
true_boxes = np.array(true_boxes, dtype='float32')
input_shape = np.array(input_shape, dtype='int32')
boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2
boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2]
true_boxes[..., 0:2] = boxes_xy/input_shape[::-1]
true_boxes[..., 2:4] = boxes_wh/input_shape[::-1]
m = true_boxes.shape[0]
grid_shapes = [input_shape//{0:32, 1:16, 2:8}[l] for l in range(num_layers)]
y_true = [np.zeros((m,grid_shapes[l][0],grid_shapes[l][1],len(anchor_mask[l]),5+num_classes),
dtype='float32') for l in range(num_layers)]
# Expand dim to apply broadcasting.
anchors = np.expand_dims(anchors, 0)
anchor_maxes = anchors / 2.
anchor_mins = -anchor_maxes
valid_mask = boxes_wh[..., 0]>0
for b in range(m):
# Discard zero rows.
wh = boxes_wh[b, valid_mask[b]]
if len(wh)==0: continue
# Expand dim to apply broadcasting.
wh = np.expand_dims(wh, -2)
box_maxes = wh / 2.
box_mins = -box_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
# Find best anchor for each true box
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n in anchor_mask[l]:
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true
def box_iou(b1, b2):
'''Return iou tensor
Parameters
----------
b1: tensor, shape=(i1,...,iN, 4), xywh
b2: tensor, shape=(j, 4), xywh
Returns
-------
iou: tensor, shape=(i1,...,iN, j)
'''
# Expand dim to apply broadcasting.
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# Expand dim to apply broadcasting.
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou
def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):
'''Return yolo_loss tensor
Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss
Returns
-------
loss: tensor, shape=(1,)
'''
num_layers = len(anchors)//3 # default setting
yolo_outputs = args[:num_layers]
y_true = args[num_layers:]
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0]))
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]
loss = 0
m = K.shape(yolo_outputs[0])[0] # batch size, tensor
mf = K.cast(m, K.dtype(yolo_outputs[0]))
for l in range(num_layers):
object_mask = y_true[l][..., 4:5]
true_class_probs = y_true[l][..., 5:]
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True)
pred_box = K.concatenate([pred_xy, pred_wh])
# Darknet raw box to calculate loss.
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]
# Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)
object_mask_bool = K.cast(object_mask, 'bool')
def loop_body(b, ignore_mask):
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0])
iou = box_iou(pred_box[b], true_box)
best_iou = K.max(iou, axis=-1)
ignore_mask = ignore_mask.write(b, K.cast(best_iou<ignore_thresh, K.dtype(true_box)))
return b+1, ignore_mask
_, ignore_mask = K.control_flow_ops.while_loop(lambda b,*args: b<m, loop_body, [0, ignore_mask])
ignore_mask = ignore_mask.stack()
ignore_mask = K.expand_dims(ignore_mask, -1)
# K.binary_crossentropy is helpful to avoid exp overflow.
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)+ \
(1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
if print_loss:
loss = tf.Print(loss, [loss, xy_loss, wh_loss, confidence_loss, class_loss, K.sum(ignore_mask)], message='loss: ')
return loss
2.2.3 utils.py
修改yolo3目录下的utils.py。
"""Miscellaneous utility functions."""
from functools import reduce
from PIL import Image
import numpy as np
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
def compose(*funcs):
"""Compose arbitrarily many functions, evaluated left to right.
Reference: https://mathieularose.com/function-composition-in-python/
"""
# return lambda x: reduce(lambda v, f: f(v), funcs, x)
if funcs:
return reduce(lambda f, g: lambda *a, **kw: g(f(*a, **kw)), funcs)
else:
raise ValueError('Composition of empty sequence not supported.')
def letterbox_image(image, size):
'''resize image with unchanged aspect ratio using padding'''
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128,128,128))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
def get_random_data(annotation_line, input_shape, random=True, max_boxes=20, jitter=.3, hue=.1, sat=1.5, val=1.5, proc_img=True):
'''random preprocessing for real-time data augmentation'''
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
if not random:
# resize image
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
dx = (w-nw)//2
dy = (h-nh)//2
image_data=0
if proc_img:
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image)/255.
# correct boxes
box_data = np.zeros((max_boxes,5))
if len(box)>0:
np.random.shuffle(box)
if len(box)>max_boxes: box = box[:max_boxes]
box[:, [0,2]] = box[:, [0,2]]*scale + dx
box[:, [1,3]] = box[:, [1,3]]*scale + dy
box_data[:len(box)] = box
return image_data, box_data
# resize image
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter)
scale = rand(.25, 2)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
# place image
dx = int(rand(0, w-nw))
dy = int(rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
# flip image or not
flip = rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
# distort image
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
x = rgb_to_hsv(np.array(image)/255.)
x[..., 0] += hue
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x>1] = 1
x[x<0] = 0
image_data = hsv_to_rgb(x) # numpy array, 0 to 1
# correct boxes
box_data = np.zeros((max_boxes,5))
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
if flip: box[:, [0,2]] = w - box[:, [2,0]]
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid box
if len(box)>max_boxes: box = box[:max_boxes]
box_data[:len(box)] = box
return image_data, box_data
2.2.4 yolo.py
按照下面代码对yolo.py修改后,还需要自己修改model_path、classes_path。
# -*- coding: utf-8 -*-
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
import time
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
class YOLO(object):
_defaults = {
"model_path": 'model_data/helmet_weights.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/my_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
self.is_fixed_size = self.model_image_size != (None, None)
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# Load model, or construct model and load weights.
num_anchors = len(self.anchors)
num_classes = len(self.class_names)
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False)
except:
self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# Generate colors for drawing bounding boxes.
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
np.random.seed(10101) # Fixed seed for consistent colors across runs.
np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes.
np.random.seed(None) # Reset seed to default.
# Generate output tensor targets for filtered bounding boxes.
self.input_image_shape = K.placeholder(shape=(2, ))
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou)
return boxes, scores, classes
def detect_image(self, image):
start = timer()
if self.model_image_size != (None, None):
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = (image.size[0] + image.size[1]) // 300
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom))
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def detect_boxs(self, image):
if self.is_fixed_size:
assert self.model_image_size[0] % 32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1] % 32 == 0, 'Multiples of 32 required'
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
# print(image_data.shape)
image_data /= 255.
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
feed_dict={
self.yolo_model.input: image_data,
self.input_image_shape: [image.size[1], image.size[0]],
K.learning_phase(): 0
})
return_boxs = []
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
if predicted_class != 'person':
continue
box = out_boxes[i]
# score = out_scores[i]
x = int(box[1])
y = int(box[0])
w = int(box[3] - box[1])
h = int(box[2] - box[0])
if x < 0:
w = w + x
x = 0
if y < 0:
h = h + y
y = 0
return_boxs.append([x, y, w, h])
return return_boxs
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC)) # 获得视频编码MPEG4/H264
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
image = Image.fromarray(frame) # 从array转换成image
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
# if __name__ == '__main__':
# image_path = "test/2.jpg"
# image = Image.open(image_path)
# yolo = YOLO()
# r_image = yolo.detect_image(image=image)
# r_image.show()
if __name__ == '__main__':
video_path = "test/video3.mp4"
yolo = YOLO()
detect_video(yolo, video_path, "/test")
2.2.5 yolo3.cfg
打开yolo3.cfg,搜索yolo(共三处),每次均按下图修改。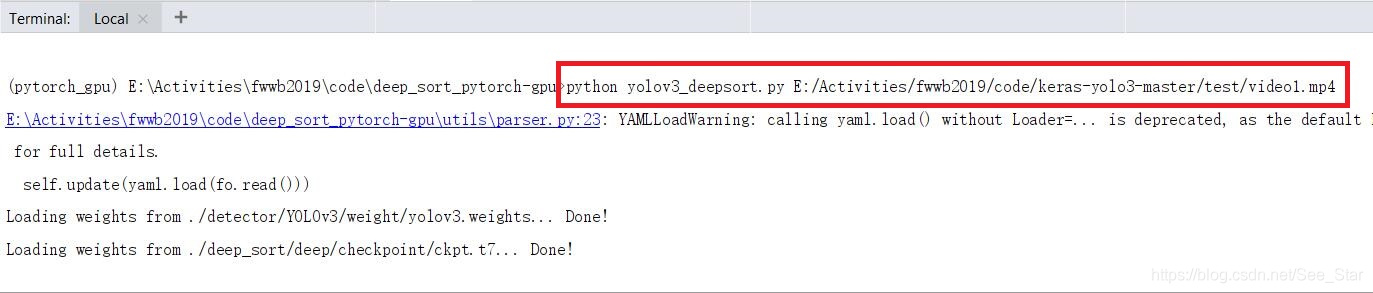
filters:3*(5+len(classes))
classes:训练的类别数
random:原来是1,显存小改为0
完成后,即可运行demo.py:
import os
import cv2
import time
import argparse
import torch
import warnings
import numpy as np
from detector import build_detector
from deep_sort import build_tracker
from utils.draw import draw_boxes
from utils.parser import get_config
class VideoTracker(object):
def __init__(self, cfg, args):
self.cfg = cfg
self.args = args
use_cuda = args.use_cuda and torch.cuda.is_available()
if not use_cuda:
warnings.warn("Running in cpu mode which maybe very slow!", UserWarning)
if args.display:
cv2.namedWindow("test", cv2.WINDOW_NORMAL)
cv2.resizeWindow("test", args.display_width, args.display_height)
if args.cam != -1:
print("Using webcam " + str(args.cam))
self.vdo = cv2.VideoCapture(args.cam)
else:
self.vdo = cv2.VideoCapture()
self.detector = build_detector(cfg, use_cuda=use_cuda)
self.deepsort = build_tracker(cfg, use_cuda=use_cuda)
self.class_names = self.detector.class_names
def __enter__(self):
if self.args.cam != -1:
ret, frame = self.vdo.read()
assert ret, "Error: Camera error"
self.im_width = frame.shape[0]
self.im_height = frame.shape[1]
else:
assert os.path.isfile(self.args.VIDEO_PATH), "Error: path error"
self.vdo.open(self.args.VIDEO_PATH)
self.im_width = int(self.vdo.get(cv2.CAP_PROP_FRAME_WIDTH))
self.im_height = int(self.vdo.get(cv2.CAP_PROP_FRAME_HEIGHT))
assert self.vdo.isOpened()
if self.args.save_path:
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
self.writer = cv2.VideoWriter(self.args.save_path, fourcc, 20, (self.im_width,self.im_height))
return self
def __exit__(self, exc_type, exc_value, exc_traceback):
if exc_type:
print(exc_type, exc_value, exc_traceback)
def run(self):
idx_frame = 0
while self.vdo.grab():
idx_frame += 1
if idx_frame % self.args.frame_interval:
continue
start = time.time()
_, ori_im = self.vdo.retrieve()
im = cv2.cvtColor(ori_im, cv2.COLOR_BGR2RGB)
# do detection
bbox_xywh, cls_conf, cls_ids = self.detector(im)
if bbox_xywh is not None:
# select person class
mask = cls_ids==0
bbox_xywh = bbox_xywh[mask]
bbox_xywh[:,3:] *= 1.2 # bbox dilation just in case bbox too small
cls_conf = cls_conf[mask]
# do tracking
outputs = self.deepsort.update(bbox_xywh, cls_conf, im)
# draw boxes for visualization
if len(outputs) > 0:
bbox_xyxy = outputs[:,:4]
identities = outputs[:,-1]
ori_im = draw_boxes(ori_im, bbox_xyxy, identities)
end = time.time()
print("time: {:.03f}s, fps: {:.03f}".format(end-start, 1/(end-start)))
if self.args.display:
cv2.imshow("test", ori_im)
cv2.waitKey(1)
if self.args.save_path:
self.writer.write(ori_im)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("VIDEO_PATH", type=str)
parser.add_argument("--config_detection", type=str, default="./configs/yolov3.yaml")
parser.add_argument("--config_deepsort", type=str, default="./configs/deep_sort.yaml")
parser.add_argument("--ignore_display", dest="display", action="store_false", default=True)
parser.add_argument("--frame_interval", type=int, default=1)
parser.add_argument("--display_width", type=int, default=800)
parser.add_argument("--display_height", type=int, default=600)
parser.add_argument("--save_path", type=str, default="./demo/demo.avi")
parser.add_argument("--cpu", dest="use_cuda", action="store_false", default=True)
parser.add_argument("--camera", action="store", dest="cam", type=int, default="-1")
return parser.parse_args()
# if __name__ == "__main__":
# args = parse_args()
# cfg = get_config()
# cfg.merge_from_file(args.config_detection)
# cfg.merge_from_file(args.config_deepsort)
#
# with VideoTracker(cfg, args) as vdo_trk:
# vdo_trk.run()
if __name__ == "__main__":
VIDEO_PATH = "E:/Activities/fwwb2019/code/keras-yolo3-master/test/video1.mp4"
parser = argparse.ArgumentParser()
parser.add_argument("--VIDEO_PATH", type=str, default=VIDEO_PATH)
parser.add_argument("--config_detection", type=str, default="./configs/yolov3.yaml")
parser.add_argument("--config_deepsort", type=str, default="./configs/deep_sort.yaml")
parser.add_argument("--ignore_display", dest="display", action="store_false", default=True)
parser.add_argument("--frame_interval", type=int, default=1)
parser.add_argument("--display_width", type=int, default=800)
parser.add_argument("--display_height", type=int, default=600)
parser.add_argument("--save_path", type=str, default="./demo/demo.avi")
parser.add_argument("--cpu", dest="use_cuda", action="store_false", default=True)
parser.add_argument("--camera", action="store", dest="cam", type=int, default="-1")
args = parser.parse_args()
cfg = get_config()
cfg.merge_from_file(args.config_detection)
cfg.merge_from_file(args.config_deepsort)
with VideoTracker(cfg, args) as vdo_trk:
vdo_trk.run()



评论(0)
您还未登录,请登录后发表或查看评论