


增强学习是这几年发展最快的方向之一,尤其在AlphaGo Zero以100:0完胜AlphaGo后,增强学习开始被公众所熟知。本文主要介绍增强学习在导航中的应用。ppt可以下载。

与监督学习、非监督学习不同,强化学习任务没有大量的标注样本但有反馈信号reward。强化学习常用马尔科夫决策过程(Markov Decision Process, MDP)来表示,如下所示Agent在Environment中的状态为
,执行动作
后状态变为
,对应的奖励为
。这里的奖励一般是根据目标人为设计的,而强化学习的目标即为寻找一个策略使得累计奖励值最大。与即时奖励
不同,这里的累计奖励评估的是某个策略对Agent在Environment中表现的长期影响,常用的计算方法有
折扣累计奖励和 T 步累计奖励。而当奖励值不好设定时,可以使用反向强化学习(Inverse Reinforcement Learning)来习得奖励值函数。

增强学习适合于复杂环境下的连续决策任务,因此非常适合解决机器人问题,近几年,在机器人抓取、导航等任务中研究非常广泛。我梳理了近几年比较有代表性的增强学习在导航相关领域中的应用文章。
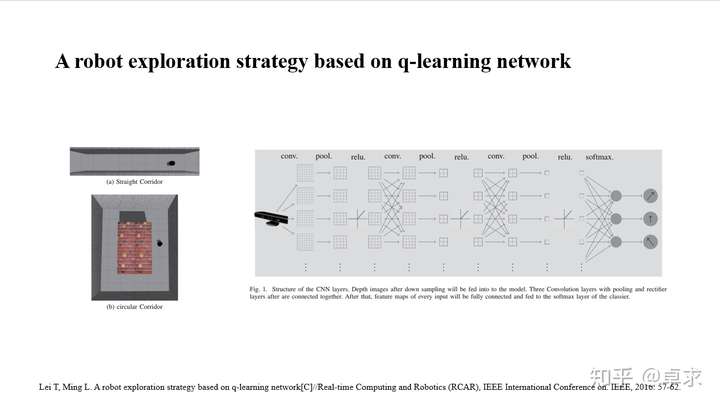

这是自DeepMind在Nature上发表Human-level control through deep reinforcement learning这篇里程碑式的论文后,最先一批将DQN+经验池的方法应用于机器人的文章。Turtlebot在Gazebo中的不同走廊环境中执行探索任务。在该任务中,State即DQN的输入为Kinect的深度图像,Action为离散化的左转、直行、右转三个动作。为了实现任务,作者将DQN分成了两步,首先用三层的卷积层来提取图像特征,如Fig.1所示,在训练时采集Kinect的深度图像以及人控制机器人的运动指令作为训练集进行监督学习(该步骤过渡自另一篇论文:A Deep-Network Solution Towards Model-less Obstacle Avoidance),训练好特征提取网络后即为第二步,在训练好的特征提取网络后加三层全连接层输出离散化的三个动作的Q值。Reward每一步为+1,如果发生碰撞,则为-50。

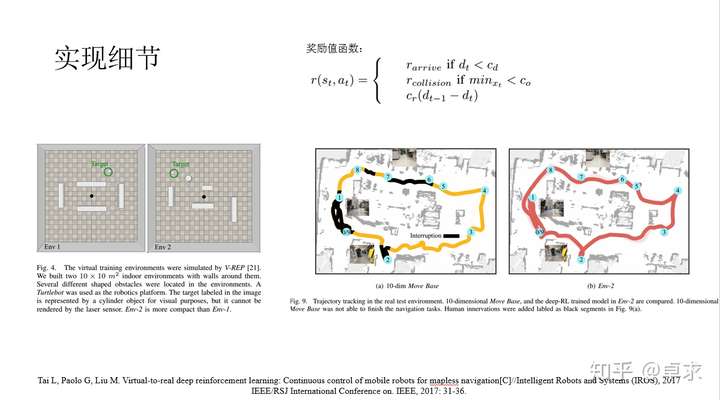
这篇文章使用的增强学习方法是并行化地运行DDPG(Deep Deterministic Policy Gradient)来提高采样效率,称之为同步DDPG(ADDPG)。Turtlebot在机器人仿真工具V-REP中执行无地图的导航任务,State为激光雷达采到的十个距离值(用于避障)以及机器人相对于目标点的位置(用于导航)和上一步的速度值(影响当前速度值的确定),输出是Turtlebot左右轮的转速,与上篇的工作相比,Action是连续的,而DDPG提出的初衷正是解决连续动作空间的问题。Fig.3为actor和critic网络,分别负责输出策略(使得其表现越来越好)和估计对应值函数(使得其越来越准确),网络的学习效率是0.0001,训练优化器为Adam。这篇文章另一个强调点是virtual-to-real,相比于图像,采用稀松距离值来训练更易于用于实物中。作者以激光雷达的全部数据计算得到的成本地图作为Move Base,以同样的稀松距离值计算得到的成本地图与在V-REP中训练好的增强学习作比较,如图Fig.9。


国内相关的工作也比较多,但都没什么大的创新,这里选两篇简单看看。第一篇A deep Q network for robotic planning from image将目标信息直接包括到图像中,机器人在室内从初始位置到达目标点,不过我在论文里没有找到目标怎么包括到输入里,而如果把场景图像和目标图像一块儿放入深度增强学习的网络中,便是17年的ICRA文章Target-driven visual navigation in indoor scenes using deep reinforcement learning的思路。第二篇任务有所不同,机器人在封闭空间中探索,去收集更可能多的apple而避免碰到lemon,这个任务应该是参考16年DeepMind的文章Reinforcement learning with unsupervised auxiliary tasks,这两篇文章后边都会介绍。这两个任务的输入都是高维图像信息,动作空间都离散化为三个,因此都采用了DQN来实现。

这篇文章即在室内环境中使用尽可能少的步数到达视觉目标,输入为室内图像与目标对象图像,输出机器人的动作(离散化为4个,加入高斯噪声模拟真实世界中的误差),到达目标的奖励值为10.0,否则每步会得到-0.01的惩罚(鼓励以更少的步数到达目标)。右图所示为网络结构,这里使用了孪生网络(Siamese Network),孪生网络适合小样本和评估相似性的学习任务,两个输入后紧跟的神经网络拥有相同的权重,这里是使用ImageNet训练的ResNet-50和一个全连接层,全连接层的权重训练得到,且共享,然后将两部分的输出连接到一个全连接层,进一步输出4个离散化动作的probability以及所选动作的Q值。

这篇文章包括下一篇都是DeepMind的文章,文章创新性、理论性更强,很值得参考。在这篇文章里提出了UNREAL(UNsupervised REinforcement and Auxiliary Learning)算法,即让agent在训练过程中执行附加任务,来对标准的增强学习方法进行增强,比如在该迷宫游戏中执行搜索任务时增加两个辅助任务:学习控制屏幕上的像素,即通过移动看到不同的东西,加快搜索效率(Pixel Control);从简短的历史背景中预测即将获得的奖励(Reward Prediction)。在训练时原始的任务使用A3C来训练,而辅助任务使用Q-learning来训练,Loss包括两部分的损失函数之和,由此可以通过辅助任务加快原始任务的训练。另外推荐一篇文章:Playing FPS Games with Deep Reinforcement Learning,这篇文章通过增强学习来玩射击类游戏Doom,文章思路和UNREAL很橡,通过在网络中添加Game features的预测分支和主任务(选择策略,消灭敌人,拾取弹药等)进行Co-training,Loss为两部分损失函数之和,由此来加快主任务的训练。
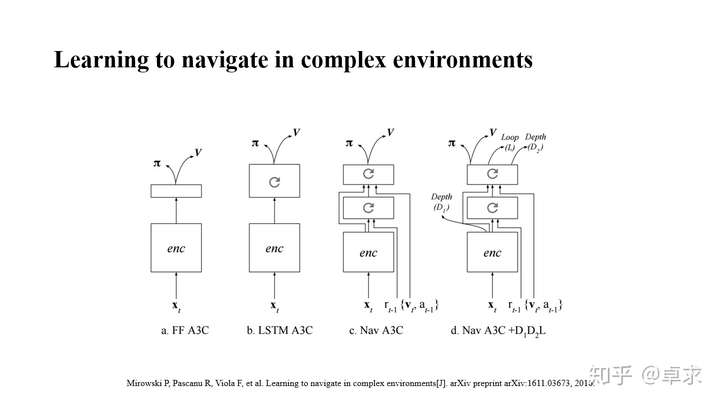
这篇文章执行的任务和上篇一样,即仅适用视觉信息(单目摄像头的图像)进行导航搜素(以最快速度找到迷宫中的苹果),在A3C的基础上:
1>改进了神经网络的结构。图a是原始的A3C算法,同时输出策略π以及值函数V,图b所示结构在a的基础上加入了LSTM层使得网络记忆之前的图像信息。图c在卷积层之后又加入了一层LSTM,并在输入中包含了更多导航相关信息(上一步的奖励值、相对速度以及动作),第一层LSTM负责抽取视觉特征和奖励的关联信息,这些关联作为第二层LSTM的输入。
2>增加辅助训练任务,这点和UNREAL思想相同,在外部引入深度信息输出(在SLAM中往往很有用)与判断机器人是否走过同一位置(是否进入loop)来根据仿真环境中的数据训练CNN网络。进一步在训练好的CNN网络再引入一个输出,输出位置信息,机器人行走一段时间后位置就相当准确了。
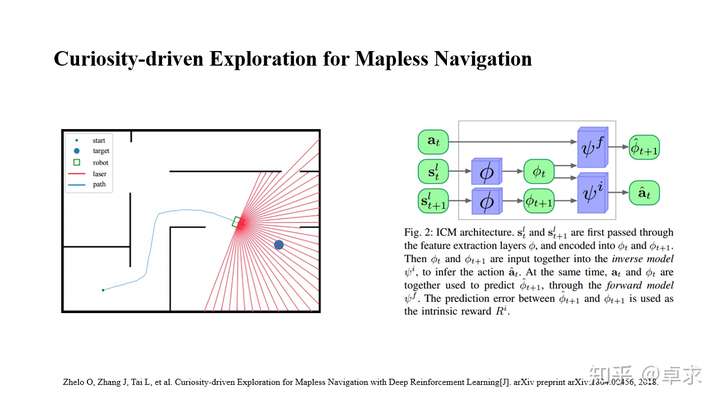
这篇文章将ICM(Intrinsic Curiosity Module)应用到了导航中,通过ICM产生的额外奖励值来让agent更好地探索环境。这里首先说下ICM,对于Sparse reward任务,在大部分时间reward为0,会使得agent在环境中瞎转悠,这时可设计一个指标来评估熟悉度,这个指标即根据当前的state和action来预测下一刻的state,计算与实际state的偏差,偏差越小说明agent对环境越熟悉,这个熟悉度即为可额外添加的reward,称之为Curiosity。右图所示即为ICM结构,关于ICM更详细的介绍可查看论文Curiosity-driven exploration by self-supervised prediction。

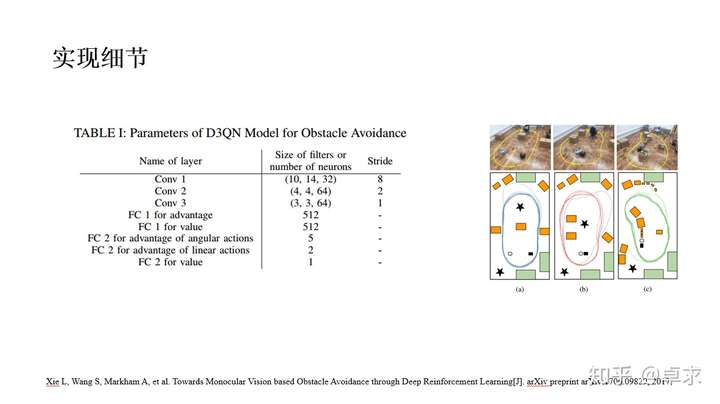
这篇文章侧重于避障,传统的路径规划方法利用视觉信息可推断出可通行路径,但需要微调很多参数,且并不适应于新环境;而端到端的深度学习直接可以根据视觉图像得到控制策略,但需要大量的手工标签来训练。由此作者提出了新的网络结构,由两部分组成,首先利用卷积残差网络(Convolutional Residual Network)提取深度信息,这部分可通过监督学习来训练,直接利用Kinect的深度图作为标签,避免了手工标注,同时为了更好地应用到实际场景中Kinect深度图加入了随机噪声和模糊。网络的第二部分是增强学习网络,作者称之为D3QN(dueling architecture based deep double-Q network),其实就是DQN加上double-Q,dueling betwork等技巧,action为离散化的线速度(2个)和角速度(5个 ),奖励值函数r=v*cos(ω)*δt , v 和 ω 依次是局部线速度和角速度, δt 是步长,设为0.2s,奖励函数使得机器人尽可能地前进而避免原地打转,此外当发生碰撞时奖励值-10,500步为一个episode。在Gazebo中训练好的网络应用到实际场景中的效果也是本不错的。

这篇文章是2018年DeepMind发表在Nature上的一篇文章,这篇文章虽然理论性很强但是很有意思,如果觉得论文太过枯燥,可以读读他们的博客文章。这篇文章也说明了神经科学不仅启发着人工智能,人工智能也能反哺神经科学。
最后再来看两篇自动驾驶相关的文章。

这篇文章不借助地图、GPS等其它一切辅助手段,只以视觉信息作为输入进行无人车的导航,这与人到达目的地很橡。与之前的相关工作不同,作者将无人车放在了城市规模的复杂场景中,在纽约、巴黎、伦敦三个城市中采集真实世界的数据进行训练。多城市导航网络结构如右图c所示,卷积网络Conv处理图像并抽取特征,中间层为locale-specific RNN来记忆、理解环境,第三层是locale-invariant RNN来生成导航策略。分别用三个城市来训练网络,完成后用于新的城市时将Conv和locale-invariant RNN层固定,只需locale-specific RNN层来学习新的城市的标志物,这种方法使得agent来学习新的知识(locale-specific RNN层)而无需忘记已经习得的知识(Conv和locale-invariant RNN层)。

当增强学习任务搜索空间巨大时可以使用模仿学习(Imitation Learning)来加快任务的训练。在这篇文章中作者在模仿学习的基础上提出了条件模仿学习(Conditional
Imitation Learning),因为通过模仿学习得到训练数据,再用训练数据去训练网络,存在一个隐式的假设,即Observation/Sate到action的映射是唯一而确定的,但在复杂情况时这种单一映射是不成立的,比如自动驾驶车辆开到三叉路口,驾驶员后续的动作并不止从Observation来确定,还有驾驶员的internal state,如目的地。由此可显性建模这个internal state,记为h,通过添加额外的输入command将h外置到控制器中,c=c(h)。如图所示,作者提出了两种结构,command input和branched,其中branched的测试效果更好。此外,自动驾驶任务中如果只利用得到的专家数据训练很容易使得运行轨迹偏移(个人理解是存在传感器误差等原因),这时需要recover from disturbance or drift,常见的方法是记录数据时就添加抖动,具体见论文End to End Learning for Self-Driving Cars;或者使用Dagger算法,可以查看在Torcs环境中实现的基于Dagger的端到端的自动驾驶策略,或者我的Kears版本。

还可以看下这篇比较新的论文InfoGAIL: Interpretable Imitation Learning from Visual Demonstrations,文章使用Generative Adversarial Imitation Learning (GAIL)来推断专家演示中导致可变的以往未显式建模的潜在因素(比如个人开车偏好等)。也可以看看这篇:Imitating driver behavior with generative adversarial networks。



评论(0)
您还未登录,请登录后发表或查看评论