

转自https://blog.csdn.net/watermelon1123/article/details/82083522
前些日子因工程需求,需要将yolov3从基于darknet转化为基于Caffe框架,过程中踩了一些坑,特在此记录一下。
1.Yolov3的网络结构
想要转化为Caffe框架,就要先了解yolov3的网络结构,如下图。
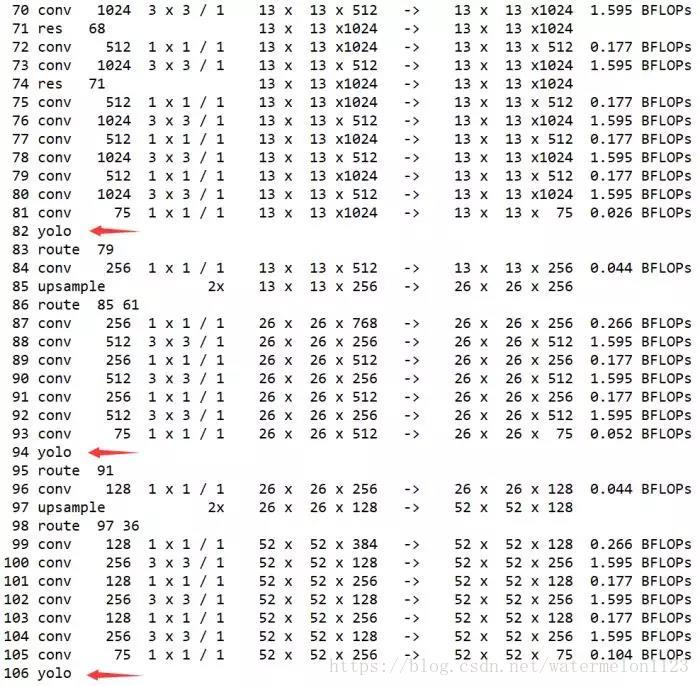
如果有运行过darknet应该会很熟悉,这是darknet运行成功后打印log信息,这里面包含了yolo网络结构的一些信息。yolov3与v2相比,网络结构中加入了残差(shortcut层),并且引入了上采样(upsample层),并为了将采样后的特征图进行融合引入了拼接(route层),最后融合的特征图以三个不同的大小13*13*75,26*26*75,52*52*75输入给yolo层最后得到目标的位置及分类信息,加上卷积层convolution,这些便是yolov3的网络基本构造。因此只要我们如果在Caffe中找到对应的层按照相应的进行构造就能够使用Caffe实现yolov3了。
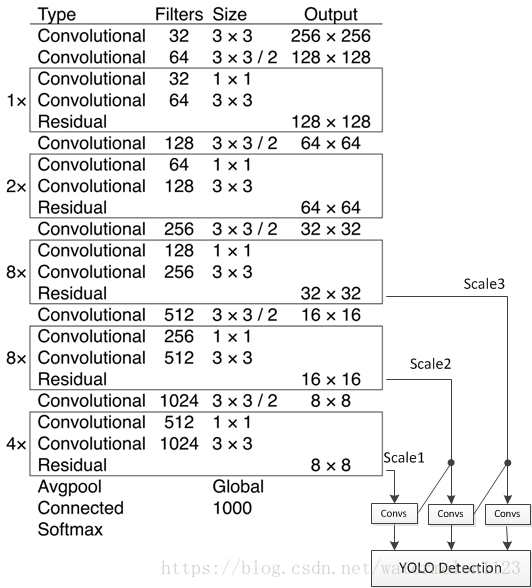
卷积层不说,yolov3中的shortcut层可以用eltwise替代,route层可以用concat替代,而upsample层和yolo层则需要自己实现,并添加到Caffe中即可。upsample层主要完成了上采样的工作,这里不细说。本文主要讲一下yolo层如何实现,上图中的YOLO Detection即为yolo层的所在位置,接收三种不同大小的特征图,并完成对特征图的解析,得到物体的位置和类别信息。所以其实yolo层主要起到了解析特征并输出检测结果的作用,这一过程我们完全可以在外部实现而无需加入到网络结构当中,也就是说我们无需将实现的yolo层加入到Caffe当中去。
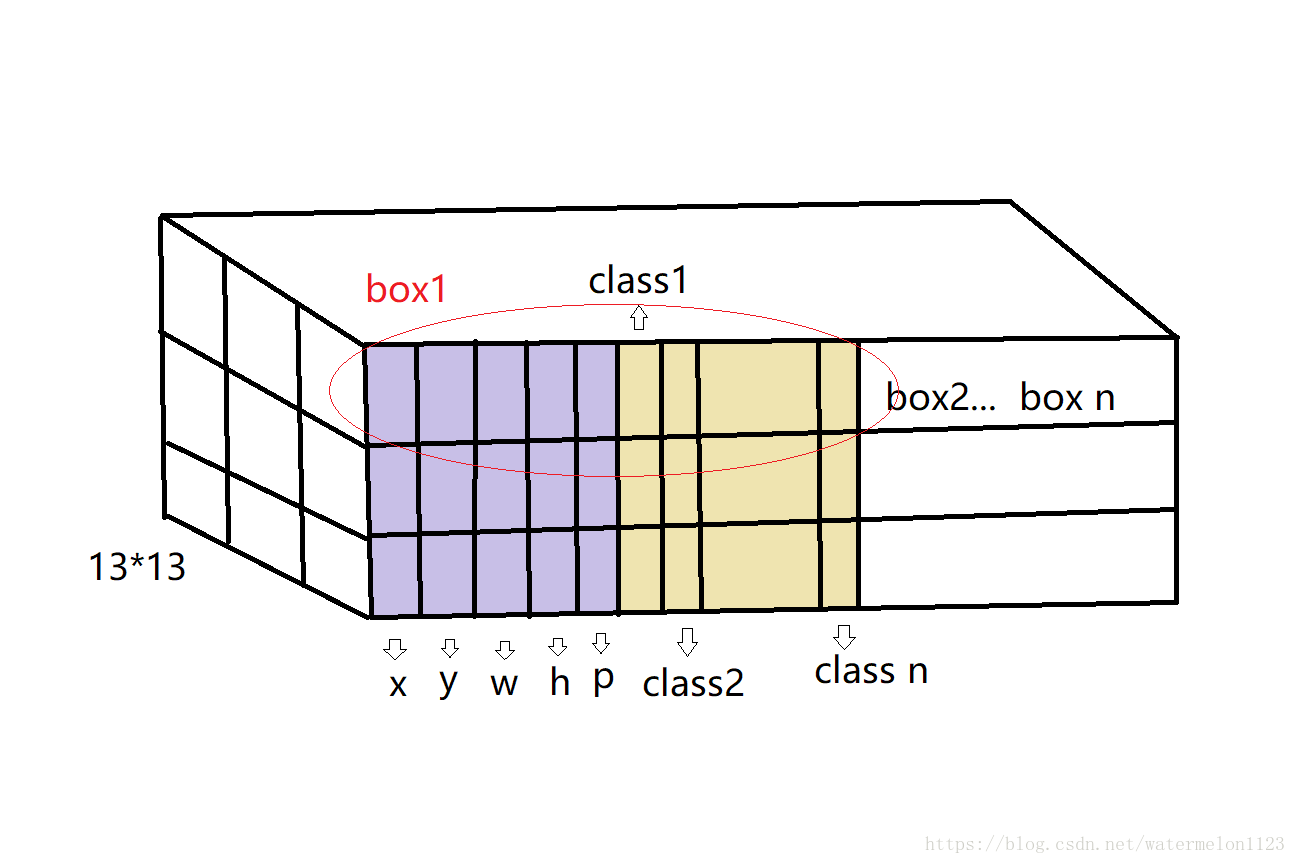
通过上图(我自己花的灵魂解析图,凑活看吧),可以解释yolo层如何得到检测目标的位置和分类。Yolo层的input是一个13*13*N的特征图,其中13*13如果有看过yolov1的论文作者有给出过解释,其实就是图像被分成了13*13个grid cell,而每个grid中是一个长度为N的张量,其中的数据是这样分布的,前4个位置分别为x,y,w,h,用于计算目标框的位置;第5个位置为置信度值Pr(object)*IOU,表明了该位置的目标框包含目标的置信度;第5个位置往后则为该box包含物体类别的条件概率Pr(class|object),从class1~class n,n为你所需检测类别数。这样(x,y,w,h)+ Pr(object)*IOU + n*Pr(class|object)构成了box1的所有信息,而一个grid cell中含有3个这样的boxes,这就是输入到yolo层的特征图的直观解释。在yolo层进行检测的时候,首先判定每个box的包含物体的置信度值即p的值是否大于设定阈值thresh,如果大于该阈值则认为这个box中含有物体,读取位置信息(x,y,w,h)与对应的anchor box的信息计算得到物体框的实际位置。之后针对于每个含有物体的box,根据其类别概率判定其类别所属,再对同一类别的目标框进行非极大值抑制NMS,即得到最终结果。
以上即为yolo层所实现的检测过程简要介绍,具体的过程如何计算还需要看官们仔细看一下代码和论文,当然此过程不包括训练的前向和反向过程,仅包含推理。因此我们转换到Caffe框架下的yolov3也仅能实现推理过程,具体的训练还需要通过darknet来完成。
2.如何实现
下面这部分将着重讲一下如何实现从darknet向yolov3的转换,首先这一过程要感谢chenyingpeng提供的代码,博客在这里。
1.加入upsample层并编译Caffe
upsample层的代码在这里,密码bwrd。
其中的upsample_layer.hpp放入include/caffe/layers下面;upsample_layer.cpp与upsample_layer.cu放在src/caffe/layers下面。
修改相应的caffe.proto文件,src/caffe/proto/caffe.proto中的LayerParameter的最后一行加入加入:
message LayerParameter {
.....
optional UpsampleParameter upsample_param = 149;
}注意149为新层的ID号,该ID号请根据个人的caffe.proto文件指定即可。
然后再caffe.proto中添加upsample层的参数:
message UpsampleParameter{
optional int32 scale = 1 [default = 1];
}紧接着重新编译Caffe,这样就完成了在Caffe中添加upsample层。更多信息请参考caffe中添加新层教程。
上面说过转换到Caffe后只包含推理过程,因此我们需要将训练好的模型(.cfg)和权重文件(.weights)转换到对应Caffe下的.proto和.caffemodel,代码可以借鉴github上的模型转换工具。注意该工具需要pytorch支持请自行安装。且该工具应用于Yolov2,因为我们在Caffe中加入了相应的upsample层并且yolov3和v2的网络结构有变化,因此需要替换相应的darknet2caffe.py,代码在这里,密码:i6y2。
至此我们的准备工作就结束了,这样通过Caffe我们就能得到相应的blobs,这些blobs里包含的信息和darknet输入给yolo层的信息是一样的。我们只需要通过yolo layer将blobs的信息进行解析就能够得到目标的位置和类别信息。因为私人原因,这部分代码不能开放,但是可以参考chenyingpeng的代码,在这里。经测试是同样可用的,只需要注意因为我们的yolo layer的检测过程是在Caffe外部实现的,因此yolo layer层的相应信息作者以硬编码的形式加入到代码中,使用的时候需要根据个人yolo layer的参数进行修改(比如我测试的时候yolo_layer.cpp中的函数get_detections中的类别数目没有修改就发生了难以言表的结果...)。
yolov3从darknet转Caffe的整个过程就结束了,其中关于yolov3的原理并没有详细解释特别多,本文主要着重于和转到Caffe框架相关的内容,具体yolov3的原理性文章推荐大家看这篇,里面关于yolov1~v3讲解的很详细(来自一群还在上大一的学生的论文解读,不禁让人感叹长江后浪推前浪,前浪我已GG)。关于yolov3的训练代码,推荐大家去看darknet的源码,尤其是关于Yolo layer的代码,里面有许多作者文章里没有讲清楚的内容,感兴趣的可以仔细钻研一下。
本人才疏学浅,本文仅是最近工程实践中的一点成果,如有错误还望指正。



评论(0)
您还未登录,请登录后发表或查看评论