


DCGAN教程
GAN:Generative adversarial network生成对抗网路
GAN
GAN生成对抗网络,该框架可以教会一个深度学习模型来捕捉训练数据分布,并生成具有同分布的相同数据。GAN最早由lan Goodfellow在2014年首次提出。
GAN由两个不同的模型组成,一个是生成模型generator,一个是鉴别模型discriminator。其中,generator的作用是产生fake image使其封隔与训练图像相似; discriminator的作用是来判断这个fake image与真正的image是否相同。
训练过程中,generator通过产生越来越好的fake image,来不断试图去打败discriminator;同时discriminator也是如此。这个游戏的平衡Equilibrium是当生成器生成看起来像是直接来自训练数据的完美赝品时,判别器总是猜测生成器输出为真或假的概率为50%。
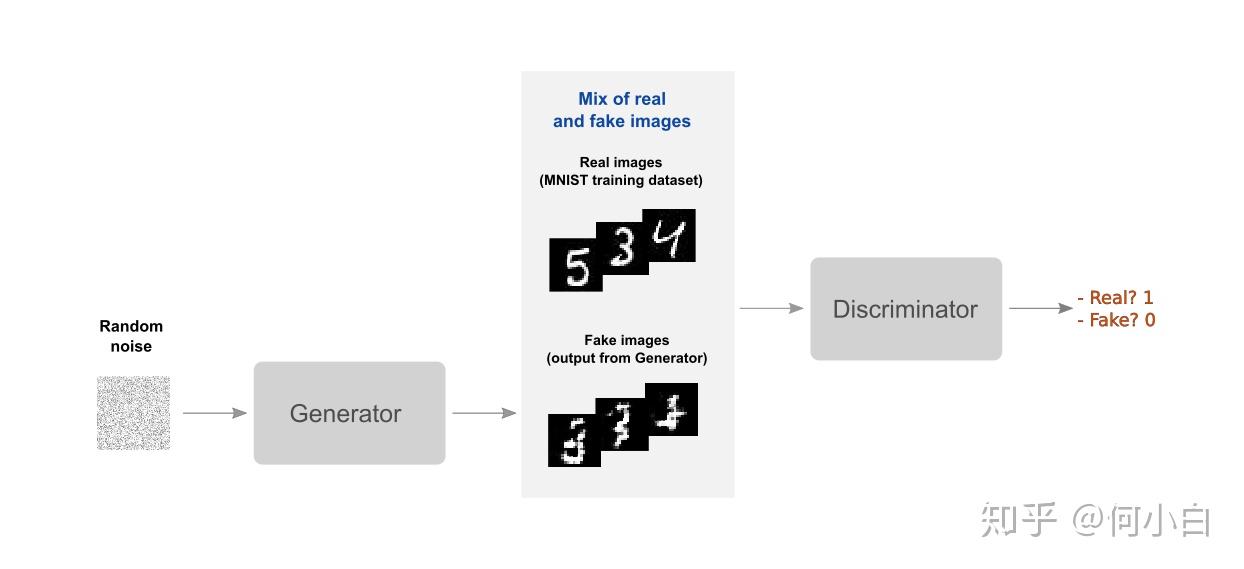
1. DCGAN原理
DCGAN是将CNN与GAN的一种结合。 其将卷积网络引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
DCGAN的原理和GAN对抗生成是一样的。它只是把GAN的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了.
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
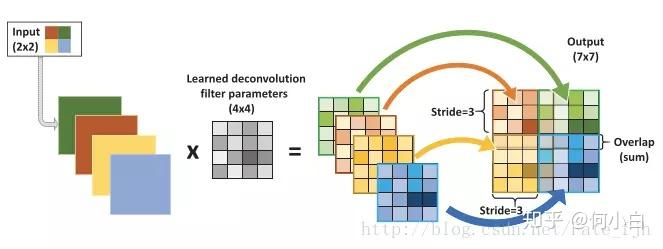
- 除了生成器模型的输出层和判别器模型的输入层,在网络其它层上都使用了Batch Normalization,使用BN可以稳定学习,有助于处理初始化不良导致的训练问题。
- 去掉全连接层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
关于转置卷积(反卷积)transposed convolutional layer
参考链接:
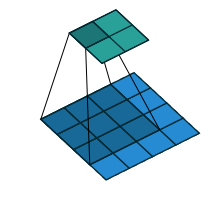
反卷积通常用于两个方面:
- CNN可视化;通过反卷积将得到的feature_map还原到像素空间,来观察feature map对哪些pattern响应最大,即可视化哪些特征是卷积操作提取出来的;
- FCN全卷积网络中,由于要对图像进行像素级的分割,需要将图像尺寸还原到原来的大小,类似upsampling的操作,所以需要采用反卷积;
- GAN生成对抗网络中,由于需要从输入图像到生成图像,自然需要将提取的特征和图还原到和原图同样尺度。
关于Loss Function
参考链接:

安装imageio来生成动态gif
# 安装imageio 来生成动态gif
!pip install imageio
import tensorflow as tf
tf.enable_eager_execution()
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import time
from IPython import display
# ---------读取数据----------
# 使用Mnist
(train_images,train_labels),(_,_) = tf.keras.datasets.mnist.load_data()
print(train_images.shape)
train_images = train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
train_images = (train_images-127.5)/127.5 # 正则化图片至[-1,1]
# 全局变量
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# --------使用tf.data来创建batches并shuffle数据集---------
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# --------创建模型------------
def make_generator_model():
"""
使用Sequential API来建立生成器与判别器模型
1.网络结构包括 Conv2DTranspose反卷积层
2.使用全连接层,并对图片进行两次上采样,来得到期望尺寸28x28x1
3.增加宽和高,并且减少网络深度
4.使用Leaky Relu()
"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(7*7*256,use_bias=False,input_shape=(100,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((7,7,256))) # reshape回去
assert model.output_shape == (None,7,7,256) # None是batchsize
# 反卷积1次
model.add(tf.keras.layers.Conv2DTranspose(128,(5,5),strides=(1,1),
padding='same',use_bias=False))
assert model.output_shape == (None,7,7,128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
# 反卷积2次
model.add(tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
# 反卷积3次,获得28,28,1维度
model.add(tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
def make_discriminator_model():
"""
判别器模型,与基本CNN图片二分类器类似
"""
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1))
return model
# --------定义loss function和optimizer ---------
def generator_loss(generated_output):
"""生成器loss"""
return tf.losses.sigmoid_cross_entropy(tf.ones_like(generated_output),generated_output)
def discriminator_loss(real_output,generated_output):
"""
判别器loss计算过程:
1.计算real_loss它是真实图像和一组1的sigmoid交叉熵损失(因为这些是真实图像)
2.计算generated_loss它是生成的图像和一组0的sigmoid交叉熵损失(因为这些是假图像)。
3.计算total_loss=sum(real_loss,generated_loss)
"""
# [1,1,1...1]是真实图像,因为它是真实的,所以我们希望生成的示例看起来像它
real_loss = tf.losses.sigmoid_cross_entropy(\
multi_class_labels=tf.ones_like(real_output),
logits=real_output)
# [0,0,…,0]生成图像,因为它们是假的
generated_loss = tf.losses.sigmoid_cross_entropy(\
multi_class_labels=tf.zeros_like(generated_output),
logits=generated_output)
total_loss = real_loss + generated_loss
return total_loss
# 判别与生成优化器是不同的,我们要各自训练
generator_optimizer = tf.train.AdamOptimizer(1e-4)
discriminator_optimizer = tf.train.AdamOptimizer(1e-4)
# Checkpoints(object-based saving)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir,"ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
# ----------配置GAN进行训练------------
# set up Generative Adversarial Networks
# 定义training的参数
EPOCHS= 50
noise_dim = 100
num_examples_to_generate = 16
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# 我们会重复使用这个random vector,你会轻松发现它会越来越优化
random_vector_for_generation = tf.random_normal([num_examples_to_generate,
noise_dim]) # 16,100
print(random_vector_for_generation.shape) # 16x100
# 定义训练方法
# 生成器:以一个随机vector作为输入,来产生一个与手写数字类似的图像。
# 判别器:展示真正的MNIST图像,并评价这个生成器生成的图像。
# 计算generator和discriminator的loss。然后,我们计算关于generator以及
# discrinminator变量的loss的梯度
def train_step(images):
"""训练过程"""
# 产生正态分布的噪声
noise = tf.random_normal([BATCH_SIZE,noise_dim])
with tf.GradientTape() as gen_tape,tf.GradientTape() as disc_tape:
generated_images = generator(noise,training=True)
real_output = discriminator(images,training=True)
generated_output = discriminator(generated_images,training=True)
gen_loss = generator_loss(generated_output)
disc_loss = discriminator_loss(real_output,generated_output)
gradients_of_generator = gen_tape.gradient(gen_loss,generator.variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss,discriminator.variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator,
generator.variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator,
discriminator.variables))
这个模型花费大概~30s每个epoch的效率,在K80的Colab上。
Eager-execution会比执行等价graph稍微慢一些,因为它不可以从图像整个program上获益,而且会导致一些用于解释Python代码的开销。通过使用tf.contrib.eager.defun来建立凸函数,我们会获得一个~20s/epoch的性能提升(from 50s/epoch to 30s/epoch)。通过这种方式,我们可以同时获得快速执行eager_execution(更容易调试)和图形模式graph_mode(更好的性能)的最佳效果。
generator = make_generator_model()
discriminator = make_discriminator_model()
train_step = tf.contrib.eager.defun(train_step)
def generate_and_save_images(model,epoch,test_input):
"""
确保training参数设置是False因为我们在进行推理时不希望训练batchnorm层。
"""
predictions = model(test_input,training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow(predictions[i,:,:,0]*127.5+127.5,cmap='gray') # 去标准化
plt.axis('off') # 关闭坐标轴
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset,epochs):
"""训练过程"""
for epoch in range(epochs):
start = time.time()
for images in dataset:
train_step(images)
display.clear_output(wait=True)
generate_and_save_images(generator,epoch+1,random_vector_for_generation)
# 每15个epoch保存(checkpoint)一次
if (epoch+1)%15 == 0 :
checkpoint.save(file_prefix = checkpoint_prefix)
print('时间消耗:epoch{}是{}s'.format(epoch+1,time.time()-start))
# 最后的epoch后进行generating
display.clear_output(wait=True)
generate_and_save_images(generator,epochs,random_vector_for_generation)
%time
train(train_dataset,EPOCHS)




评论(0)
您还未登录,请登录后发表或查看评论