

李宏毅ML学习笔记---Reinforcement Learning总结
0. 在学习A3C之前,首先需要了解的前置知识:
- RL算法主要基于以下两种方法:
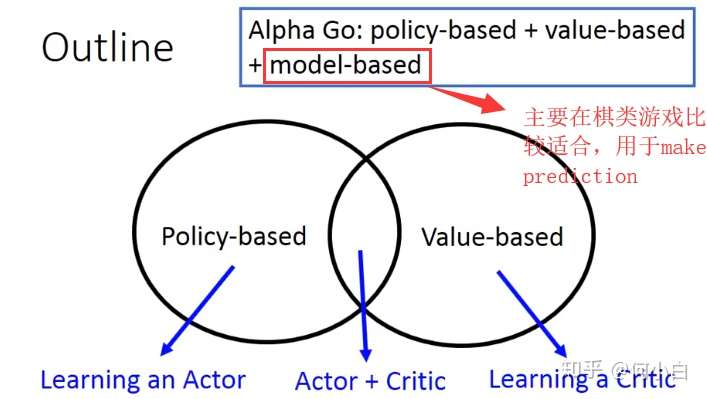
- Policy-based:
- Key Point: Learning an Actor/Policy (do action)
- Main Idea:

- STEP1——Define A set of Function 如果你的Function是Neural Network,可以肯定的是,你做的是Deep RL.
- Input of NN: Agent(Machine)的观测值,可以用vector描述,也可以用matrix描述;
- Output of NN: NN的输出,对应着每个动作,在你的需求中,有几个需要的action,这个NN的Output有着相对应的dimension;也可以理解为对应的每个动作的Probability(Softmax)

- Benefits:NN可以“举一反三”,也就是泛化能力(generalized),即使是没有看过的场景,也可能有很好的Performance.
- STEP2——Decide the goodness of the function 定义这个Function的好坏,比如在Supervised Learning里面,我们用Total Loss来定义“好坏”,在RL内,如何定义这个好坏呢?(Goodness of Actor)
- Given an actor
with network parameter
- Use the actor

- 同过上面的游戏过程,我们可以得到一个Total reward(corresponds to each eposide):
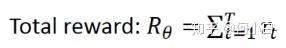
- 注意:即使是相同的actor/policy,
每次有可能也不一样(Randomness随机性)
- 我们期望去maxmize的不是
就衡量了某一个 an actor
- 一个eposide对应这一个Trajectory:
(代表游戏开始到结束的这一种过程)。

- 计算Total_reward。
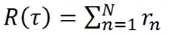
- 当你使用一个actor去玩某个游戏,每一个
都有一定的几率被选中。If you use an actor to play the game ,each
- The probability depends on actor parameter
:
(当你的parameter是
的时候,
- 最后定义Expected Value of
>>> Sum over all over possible trajectory.
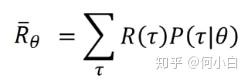
- 实际处理中,采取下面这个办法:假设某个

- 最终:进行等效代换:
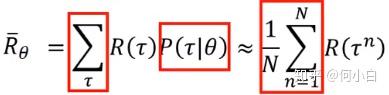
- STEP3——Pick the best function选择最好的Actor(How?--->Gradient Ascent类似于GD,但是你不是minimum而是 Maximum,所以是Gradient Ascent)
- 具体做法如下:(取log是因为)

- 总结一下,在
的时候,当Machine看见
时采取动作
时,如果
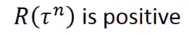
- 则我们会倾向于调整parameter
>> 这个observation采取这样 的action的probability变大,反之若是negative,则变小;
- P.S..>>>为什么上面蓝色字体,除以
?
- 相当于做一个Normalization,在update时,不会偏向那些出现几率比较高的Action;


- Value-based:
- Key Point: Learning a Critic (do evaluation)
- A critic does not determine the action>>并不决定action;
- Given an actor, it evaluates the how good the actor is >> 给定一个actor,critic评估这个actor的好坏;
- An actor can be found from a critic(Q-learning)
- A critic is a function depending on the actor π it is evaluated;Critic是一个函数,这个函数的用来评估一个observation(s)的好坏
- The Function is represented by a Neural Network
- State value function
- 当使用actor π时,在看到某一observation时,丢进这个V函数中,获得累计的reward。

- 上述两种方法结合Actor+Critic,就是A3C,也就是要学习的算法
- 主要可以学习的参考文献:



评论(0)
您还未登录,请登录后发表或查看评论