

0. 前言
在上面一篇文章中,参考李宏毅老师的授课内容,已经对Policy_Based的RL方法做了详细总结,这一篇是对上一篇的补充,主要是结合Tensorflow和GYM模块,实现Policy Based的代表算法,Policy Gradients进行实现。
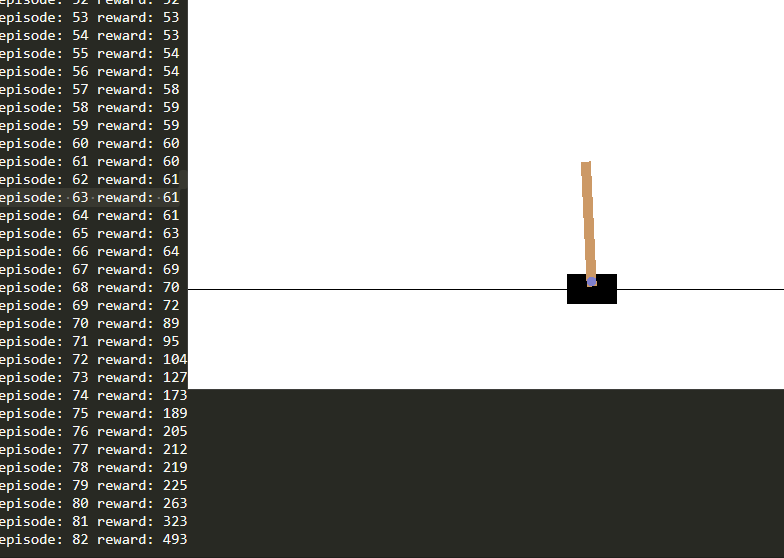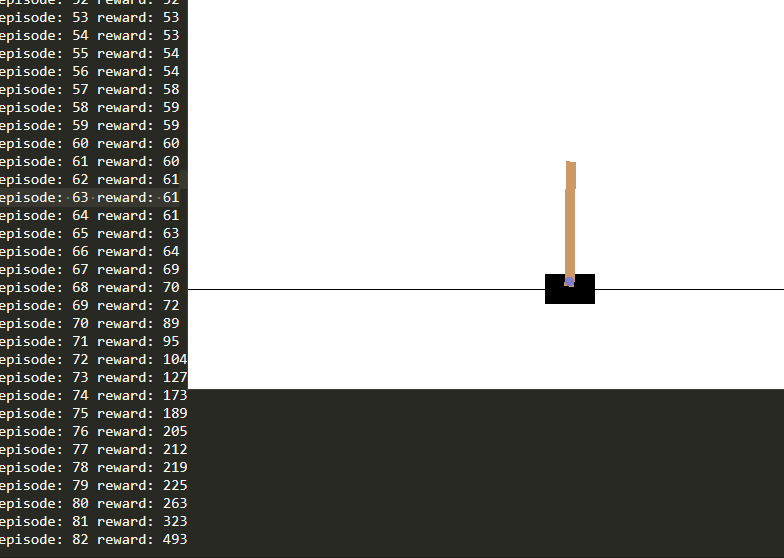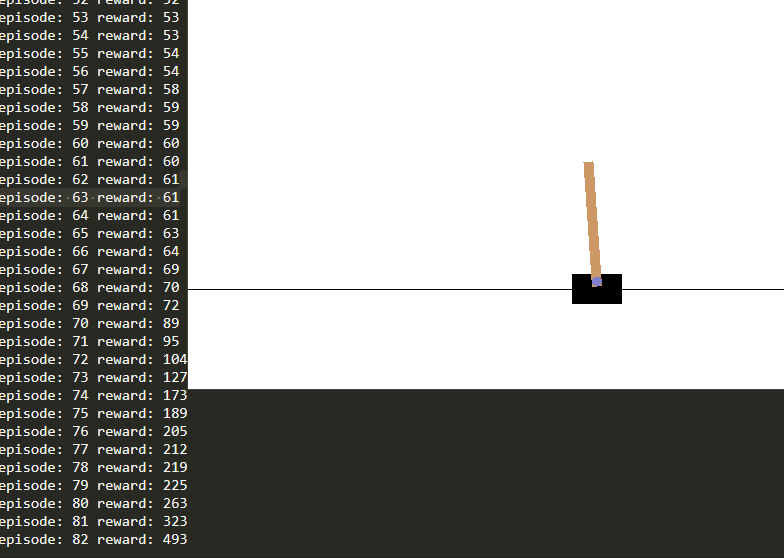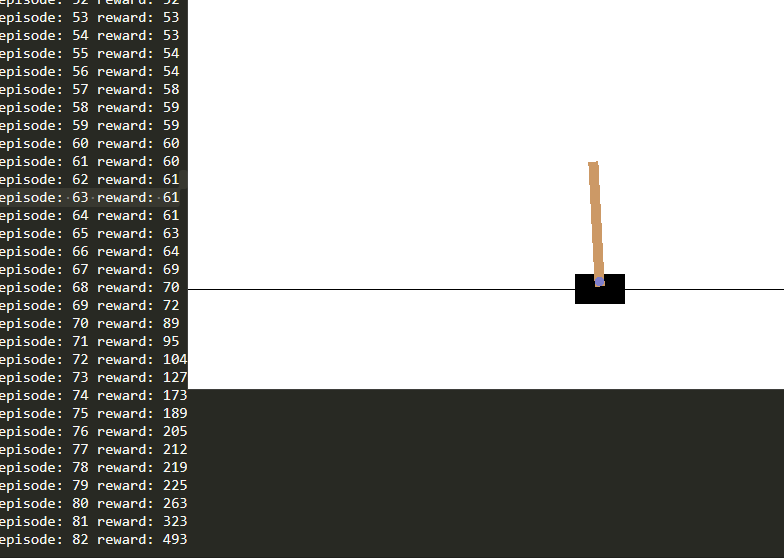
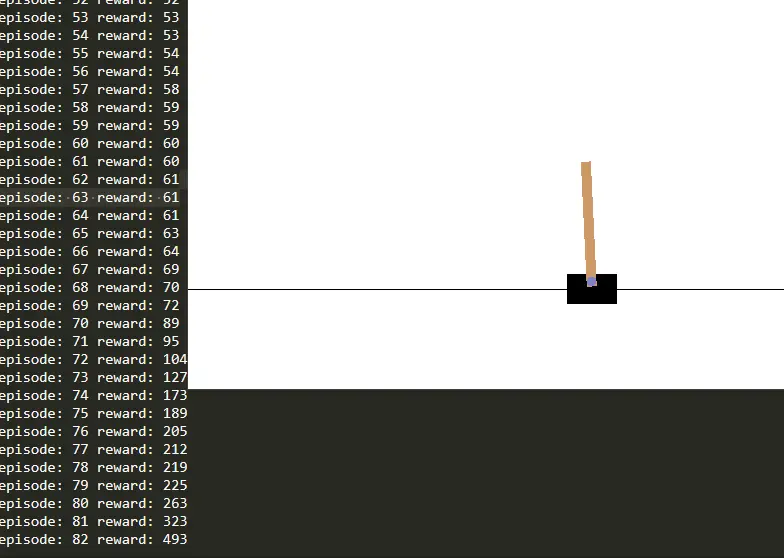
先放效果图,基于Policy Gradient 的Reinforcement Learning.
1. Key Points (Review)
- STEP1: Define a set of function;
- STEP2: Decide the goodness of the function(just like "loss function");
- STEP3: Pick the best actor. (Gradient Ascent);
2. Algorithm(PG)
Policy Gradient 的核心思想
是表示衡量这个动作的正确程度,即衡量某个state-action所对应的value(通过reward计算)如果actor执行这个动作正确程度较高,则
- log 形式的概率,会有更好的收敛性,参考强化学习1;
- 更新时以回合为基础,一个回合运行完了之后,进行一次更新(比如上面步骤中,每一个episode,都会不停的更新
);
是概率 probability;
是表示在状态s对所执行动作a的“吃惊”程度,如果
也就是(Policy(s,a)),其值越小,则log以后的值越大(概率值小于1);考虑一种情况,当在一个
- 在实际编程过程中,由于Tensorflow里的loss都是minimize,为了继续用到这种概念,同时又可以进行类似于反向传播的过程来增加我们的observation(
),在进行正常编写时,在Loss function前需要乘上-1即可;(Minimize--->Maximize)
- 在CartPole倒立摆游戏中,
- 在MountCar游戏中,越靠近奖励位置,更新幅度越大;
- 在每一个Game中,
- 补几个算法说明:

3.Code
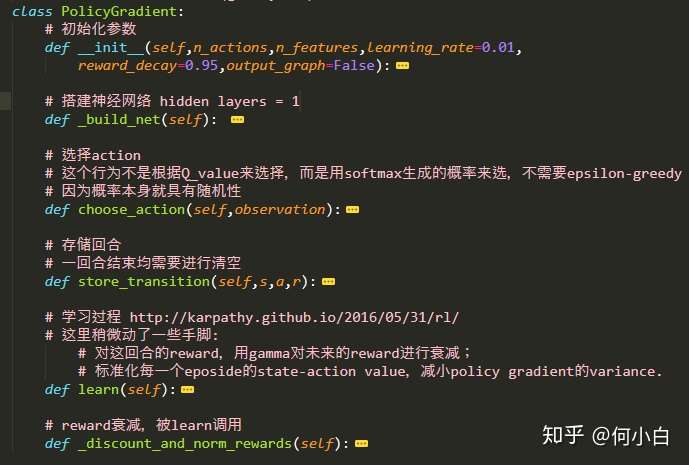
3.1 建立Policy Gradient类,主要功能:

3.2 类的结构
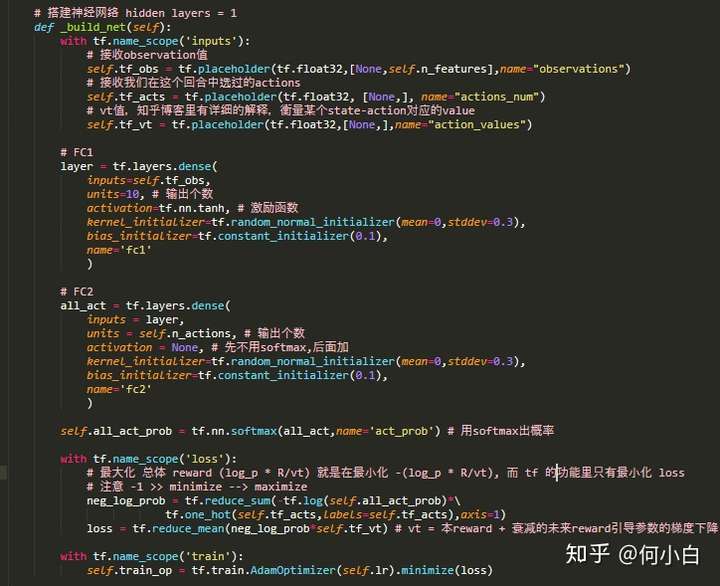
3.3 搭建神经网络
- 需要注意的是,最小化Loss的过程,实际上是对
3.4 选择action
- 思路:

- 代码:

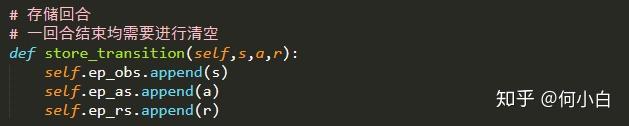
3.5 存储每个eposide的observation、action、reward值
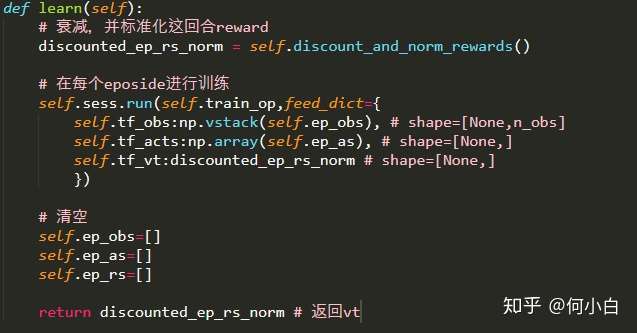
3.6 学习过程,参照:Deep Reinforcement Learning: Pong from Pixels
- 思路:

- 代码
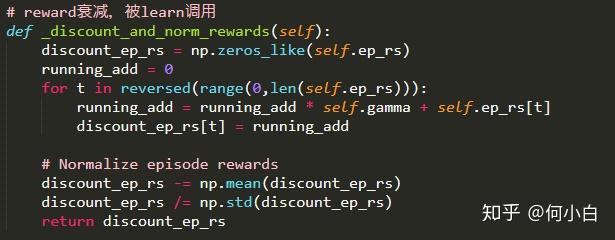
3.7 衰减reward
3.8. 所有代码
#-*- coding: utf-8 -*-
# Policy-basd RL algorithm---Policy Gradient
# Key Points:
# STEP1: Define a set of function
# STEP2: Decide the goodness of the function (just like "loss function")
# STEP3: Pick the best actor. (Gradient Ascent)
# Main tool:
# GYM
# Tensorflow
# Detail description: https://zhuanlan.zhihu.com/p/60441731
import gym
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Global Variable
RENDER = False # 是否显示模型窗口
THRESHOLD = 400 # 当回合reward大于400时显示模拟窗口
GAMEID = ['CartPole-v0','MountainCar-v0'] # 需要强化的游戏代号
EPISODE = 100 # 回合数
# Reproducible
np.random.seed(1)
tf.set_random_seed(1)
# 定义Policy_Gradient类
# Key Function:
# 1. 建立PG的神经网络(微微有改变)
# 2. 选择action行为
# 3. 存储回合transition(三个列表,observation,action,reward)
# 4. 学习过程(update parameter)
# 5. 衰减回合的reward.(gamma,衰减)
class PolicyGradient:
# 初始化参数
def __init__(self,n_actions,n_features,learning_rate=0.01,
reward_decay=0.95,output_graph=False):
self.n_actions = n_actions # action动作的数量
self.n_features = n_features # state的observation数
self.lr = learning_rate # NN学习率
self.gamma = reward_decay # 衰减率
self.ep_obs = [] # 存储每个回合信息的list
self.ep_as = []
self.ep_rs = []
self._build_net() # 建立policy神经网络
self.sess = tf.Session()
if output_graph: #是否输出tensorboard
# tensorboard --logdir=logs
# http://0.0.0.0:6006/
# tf.train.SummaryWriter soon be deprecated, use following
tf.summary.FileWriter("logs/",self.sess.graph)
self.sess.run(tf.global_variables_initializer())
# 搭建神经网络 hidden layers = 1
def _build_net(self):
with tf.name_scope('inputs'):
# 接收observation值
self.tf_obs = tf.placeholder(tf.float32,[None,self.n_features],name="observations")
# 接收我们在这个回合中选过的actions
self.tf_acts = tf.placeholder(tf.float32, [None,], name="actions_num")
# vt值,知乎博客里有详细的解释,衡量某个state-action对应的value
self.tf_vt = tf.placeholder(tf.float32,[None,],name="action_values")
# FC1
layer = tf.layers.dense(
inputs=self.tf_obs,
units=10, # 输出个数
activation=tf.nn.tanh, # 激励函数
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc1'
)
# FC2
all_act = tf.layers.dense(
inputs = layer,
units = self.n_actions, # 输出个数
activation = None, # 先不用softmax,后面加
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.3),
bias_initializer=tf.constant_initializer(0.1),
name='fc2'
)
self.all_act_prob = tf.nn.softmax(all_act,name='act_prob') # 用softmax出概率
with tf.name_scope('loss'):
# 最大化 总体 reward (log_p * R/vt) 就是在最小化 -(log_p * R/vt), 而 tf 的功能里只有最小化 loss
# 注意 -1 >> minimize --> maximize
neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob)*tf.one_hot(self.tf_acts,labels=self.tf_acts),axis=1)
loss = tf.reduce_mean(neg_log_prob*self.tf_vt) # vt = 本reward + 衰减的未来reward引导参数的梯度下降
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
# 选择action
# 这个行为不是根据Q_value来选择,而是用softmax生成的概率来选,不需要epsilon-greedy
# 因为概率本身就具有随机性
def choose_action(self,observation):
prob_weights = self.sess.run(self.all_act_prob,\
feed_dict={self.tf_obs:observation[np.newaxis,:]}) # 所有 action 的概率
action = np.random.choice(range(prob_weights.shape[1]),p=prob_weights.ravel()) # 根据概率来选 action
return action
# 存储回合
# 一回合结束均需要进行清空
def store_transition(self,s,a,r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
# 学习过程 http://karpathy.github.io/2016/05/31/rl/
# 这里稍微动了一些手脚:
# 对这回合的reward,用gamma对未来的reward进行衰减;
# 标准化每一个eposide的state-action value,减小policy gradient的variance.
def learn(self):
# 衰减,并标准化这回合reward
discounted_ep_rs_norm = self._discount_and_norm_rewards()
# 在每个eposide进行训练
self.sess.run(self.train_op,feed_dict={
self.tf_obs:np.vstack(self.ep_obs), # shape=[None,n_obs]
self.tf_acts:np.array(self.ep_as), # shape=[None,]
self.tf_vt:discounted_ep_rs_norm # shape=[None,]
})
# 清空
self.ep_obs=[]
self.ep_as=[]
self.ep_rs=[]
return discounted_ep_rs_norm # 返回vt
# reward衰减,被learn调用
def _discount_and_norm_rewards(self):
discount_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
for t in reversed(range(0,len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discount_ep_rs[t] = running_add
# Normalize episode rewards
discount_ep_rs -= np.mean(discount_ep_rs)
discount_ep_rs /= np.std(discount_ep_rs)
return discount_ep_rs
if __name__ == '__main__':
# 进行算法更新
# 调用GYM的Environment
env = gym.make(GAMEID[0]) # 选择“倒立摆”模型
env = env.unwrapped # 取消限制
env.seed(1) # 选择随机种子
# 显示需学习的game的 信息 (action,state,observation...)
print("The action that can be used:",env.action_space) # 可用action
print("The observation of the useful state:",env.observation_space) # 可用state的observation值
print("The maximum of the observation:",env.observation_space.high) # 最大observation
print("The minimun of the observation:",env.observation_space.low) # 最小observation
# 定义
RL = PolicyGradient(
n_actions=env.action_space.n, # action数量
n_features=env.observation_space.shape[0], # state数量
learning_rate=0.02,
reward_decay=0.99, # gamma
output_graph=False # 输出tensorboard
)
# 主循环 相对于Qlearning(value-based)的单步更新,这里是每跑完一个eposide更新一次
for episode_i in range(EPOSIDE):
observation = env.reset() # 初始化observation,最大化期望R'_theta
while True:
if RENDER:
env.render() # 显示模拟窗口
action = RL.choose_action(observation)
observation_,reward,done,info=env.step(action)
RL.store_transition(s=observation, a=action, r=reward) # 存储这一回合的transition
if done:
ep_rs_sum = sum(RL.ep_rs)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward*0.99 + ep_rs_sum*0.01
if running_reward > THRESHOLD: RENDER=True # 达到阈值显示模拟
print("episode:",episode_i,"reward:",int(running_reward))
vt = RL.learn() # 学习,输出vt
if episode_i == 0:
plt.plot(vt,'*',color='red')
plt.grid(True)
plt.xlabel('episode steps')
plt.ylabel('normalized state-action value')
plt.show()
break
observation = observation_


评论(0)
您还未登录,请登录后发表或查看评论