

论文阅读
Multiple Anchor Learning for Visual Object Detection
- 论文阅读
- 一、论文工作概述
- 二、论文研究情况
-
- 2.1 anchor的选择
- 2.2 RetinaNet框架
- 2.3 MAL方法实现
- 2.4 MAL方法流程总结:
- 2.5 selection-depression优化策略
-
- 2.5.1 Anchor Selection
- 2.5.2 Optimization Analysis
- 三、实验和总结
-
- 3.1 MAL与RetinaNet对比试验
- 3.2 基于COCO minval数据集的比较
- 3.3 Comparison with State-of-the-Art Detectors
- 3.4 实验总结
- 四 研究结论
一、论文工作概述
作者主要贡献:
一、作者提出了一种多锚学习的方法,通过联合优化目标定位与分类,得到最优的anchor。
二、提出了selection-depression优化策略,以保证anchor的选择不会掉入到局部最小值中。
二、论文研究情况
分类和定位是视觉目标检测器的两个最重要的环节。以往在基于CNN的目标检测器中,这两个模块通常在一组固定的边界框下进行优化。这种配置大大限制了联合优化分类和定位的可能性。也就是说,分类与定位之间是没有交互的,这就会导致定位精准但是分类的置信度低,如果一个检测结果的定位精度较高但分类置信度较低,那么它有可能在NMS操作中被过滤掉。
为解决分类与回归相互独立的问题,有人提出了IoU-Net和freeachor等方法来解决这个问题,但是在训练过程中它们仍然使用独立的分类和定位置信度。对于这一问题,本文提出了一种MAL的方法,从anchor-object匹配的角度出发,联合优化目标分类与定位。
2.1 anchor的选择
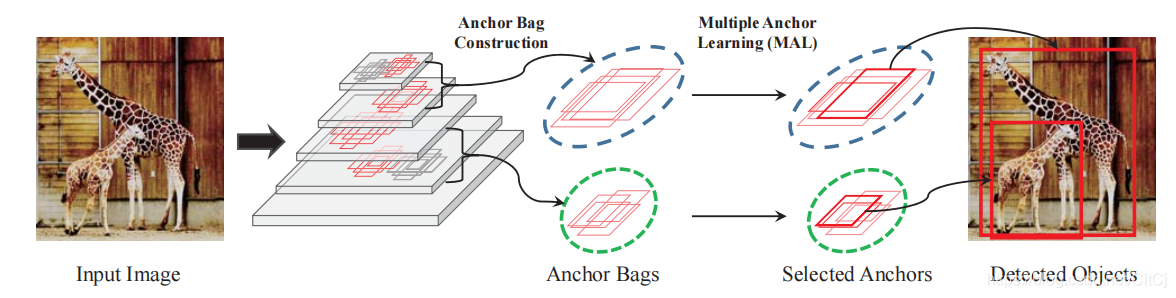
在特征金字塔网络中,为每个目标对象bi构造一个anchor bag。通过网络的反向传播,MAL评估了每个anchor在ai中的联合分类和定位置信度。这样的置信度用于anchor选择。
在每次迭代过程中,MAL选出anchor bag中得分较高的anchor以更新模型,更新后的模型为每个anchor评估新的置信度。通过一次次的anchor选择和模型学习以实现最终的优化。
2.2 RetinaNet框架

MAL是基于RetinaNet 网络体系结构实现的。MAL通过找到用于分类和定位的anchor/feature的最佳选择来优化RetinaNet。
上图为RetinaNet框架:RetinaNet的框架整体是ResNet+FPN+FCN,它使用ResNet作为backbone来提取图像特征,然后从中抽取5层特征层来构建特征金字塔网络(FPN: feature pyramid network),最后接两个独立的全卷积网络(FCN: full convolution network)分别得到物体的类别信息和位置框信息。
2.3 MAL方法实现
在每次学习迭代中,MAL选择anchor bags中的得分高的anchor来更新模型。更新后,模型会评估每个具有新置信度的anchor。模型学习和anchor选择迭代地朝着最终优化的方向执行。得到MAL有如下目标函数:
其中fθ(.)和gθ(.) 分别计算分类和定位置信度,β是正则化因子,最终是要为目标i选出最优的positive anchor,同时学习网络参数θ*。在构建Ai 之后,MAL评估出Ai 中每个anchor的分类和定位置信度,利用式(3)选出分数较高的anchor来更新模型参数,再使用更新后的模型重新评估anchor的分类和定位置信度,经过一次次这样的迭代过程,最终选出最优的anchor,以及计算出最优的模型参数。进而可以将目标函数写成:
其中Ldet和Lcls分别表示定位和分类损失与RetinaNet上一致。
2.4 MAL方法流程总结:
1.在MAL训练阶段,通过anchor-object之间的IoU进行排序,选择IoU位于前面的anchor,用它们构造一个属于该目标的anchor bag。
2.然后,通过结合分类和定位分数,来评估每个anchor bag中的正样本anchor。
3.在每次训练迭代中,MAL使用所有的正样本anchor来优化训练损失,选择得分最高的anchor作为最终的anchor。使分类分数与定位分数就能同时达到最高。
2.5 selection-depression优化策略
如果采用SGD的优化策略的话,由于SGD优化方法是一个非凸问题,所以每次迭代中选择分数最高的anchor可能不会达到最好的效果,有可能目标的一部分被错误地定位,但因为分类分数比较高,导致最终分数也比较高。
为解决此问题,这篇文章提出了selection-depression优化策略,通过扰动分数较高的anchor特征,来反复降低该anchor的置信度,使得所选择的anchor是最优的。
2.5.1 Anchor Selection
常规的MIL算法倾向于选择得分最高的anchor。但是,在物体检测的情况下,很难从每个anchor bag中选择得分最高的锚点。因此本文提出"All-to-Top-1"anchor 选择策略,在学习过程中,线性降低Ai 中的anchor数量直到降为1。设λ=t/T ,t 和T分别是当前和总的迭代次数,然后设ϕ(λ) 表示排名前几位的anchor的索引,∣ϕ(λ)∣=∣Ai∣∗(1−λ)+1 ,那么式(3)可以被改写为:
沿着这一途径,MAL利用目标区域内的多个anchor/feature在早期训练epoch中学习检测模型,并在最后一个阶段得到最佳的anchor。
受inverted attentionnetwork的启发,作者提出了一种anchor depression模块来干扰anchor的选择,其实就是给未被选择的anchor更多的机会以参与训练。设feature map和attention map分别是U和M ,其中w 是U 的全局平均池化,l是U的通道索引。然后通过将较高的值骤降为0,生成新的depressed attention map ,那么被扰动后的feature map V 为: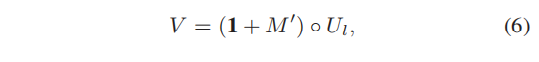

2.5.2 Optimization Analysis
selection-depression策略其实是一个对抗的过程。selection找出得分较高的anchor从而最小化检测损失Ldet 而depression通过扰动这些被选择的anchor的特征,降低这些anchor的置信度,从而Ldet又再一次上升。如下图所示,在第一个弯道中,MAL选择次优的anchor并且陷入损失函数的局部最小值;然后在第二个弯道中,anchor depression增加了损失,使得局部最小值被"填满",从而MAL能够继续这个优化过程。通过这种方式,在最终收敛的时候,MAL能有更好的机会找到最优解。
三、实验和总结
数据集:COCO
评价标准:采用AP对检测器性能进行评价,一般是在多个 IoU值间取平均值,作者是采用了 10 个 IoU阈值 即0.50:0.05:0.95.
3.1 MAL与RetinaNet对比试验
首先,在特征激活图上可视化了图5中MAL的有效性。MAL与RetinaNet相比,MAL可以激活物体上的更多部分并在后处理环节抑制更多部分,这表明MAL改进了功能以实现更好的目标检测。
3.2 基于COCO minval数据集的比较

3.3 Comparison with State-of-the-Art Detectors

3.4 实验总结
MIL:其实也是一种监督学习,但是和分类不同的是它的分类不是每一个样本给一个label,而是一个bag给一个label。举一个例子来说,我们要判别,一个视频中有没有出现篮球,那么如果这个视频由一万张图组成,那么如果有一张图中有出现篮球,那么这个视频中就有篮球,反之,如果1w张图中都没有出现篮球,那我们就说这个视频中没有出现篮球。所以我们训练数据的时候拿到的是1个视频和1个label(这个视频中有没有篮球)。
那么这篇文章是如何把MIL用到目标检测中的呢?
作者首先提出现在的模型大多都没有将分类和定位联系起来的,即分类得分并不表达regression的回归效果,但是实际上我们希望能够表达,因为这样我们的NMS需要根据分类得分来移除冗余的预测框。那么这就会存在可能回归出来的框很好,但是分类得分较低,或者分类得分很高,但是回归出来的锚框不是很理想,这些情况都对最后的NMS造成了负面影响。解决这个问题存在两种方法,第一种是给更好的score,也就是IoUNet想做的事情,第二种也就是作者想做的,用更适合的anchor来训练网络。当然这个说法就是FreeAnchor(作者解释是因为MLE不适合用来解非凸问题,所以FreeAnchor也不好)。
那么怎么才是好的呢?
作者提出了学多个anchor,每次选出top-k score的anchor用来回归,也就是从anchor bag中选若干个anchor进行训练,这样就在优化的过程中保证了给出的anchor都是高的,不然就不会被选到。但是这就存在一个问题,如果我每次都训练多个anchor回归一个物体,那么最后推断呢?选谁好?所以作者提出了一个selection depression optimization,是啥呢?通俗的说就是一开始会一个bag里有多个anchor,随着iter增加逐渐减少anchor,直到最后只剩一个。当然对于anchor的选择,作者还提出了另外一个方法,也就是anchor depression,总的来说就是把MIL应用到object detection里的文章,比RetinaNet高了5个点。在我们看来这真的是一个很大的提升。
四 研究结论
本文提出了:
一种多锚学习的方法,通过联合优化目标定位与分类,得到最优的anchor。
selection-depression优化策略,以保证anchor的选择不会掉入到局部最小值



评论(0)
您还未登录,请登录后发表或查看评论