

1. 决策树简介
决策树算法从有类标号的训练元组中,根据数据属性采用树状结构建立决策模型。
决策树中每个内部节点表示在一个属性上的测试,每个分支代表该测试上的一个输出,每个树叶节点存放一个类标号,直观看上去就像判断模块和终止块组成的流程图,判断模块表示对一个特征取值的判断,终止块表示分类结果。
决策树分类器的构造不需要任何领域知识或参数设置,适合探索式知识发现,可处理高维数据,表示直观易被理解,是许多商业规则归纳系统的基础。
如下表记录已有的用户是否还贷的相关信息: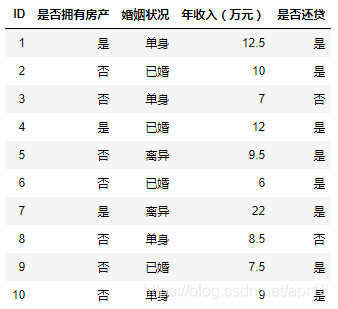
根据该数据,构建的决策树如下:
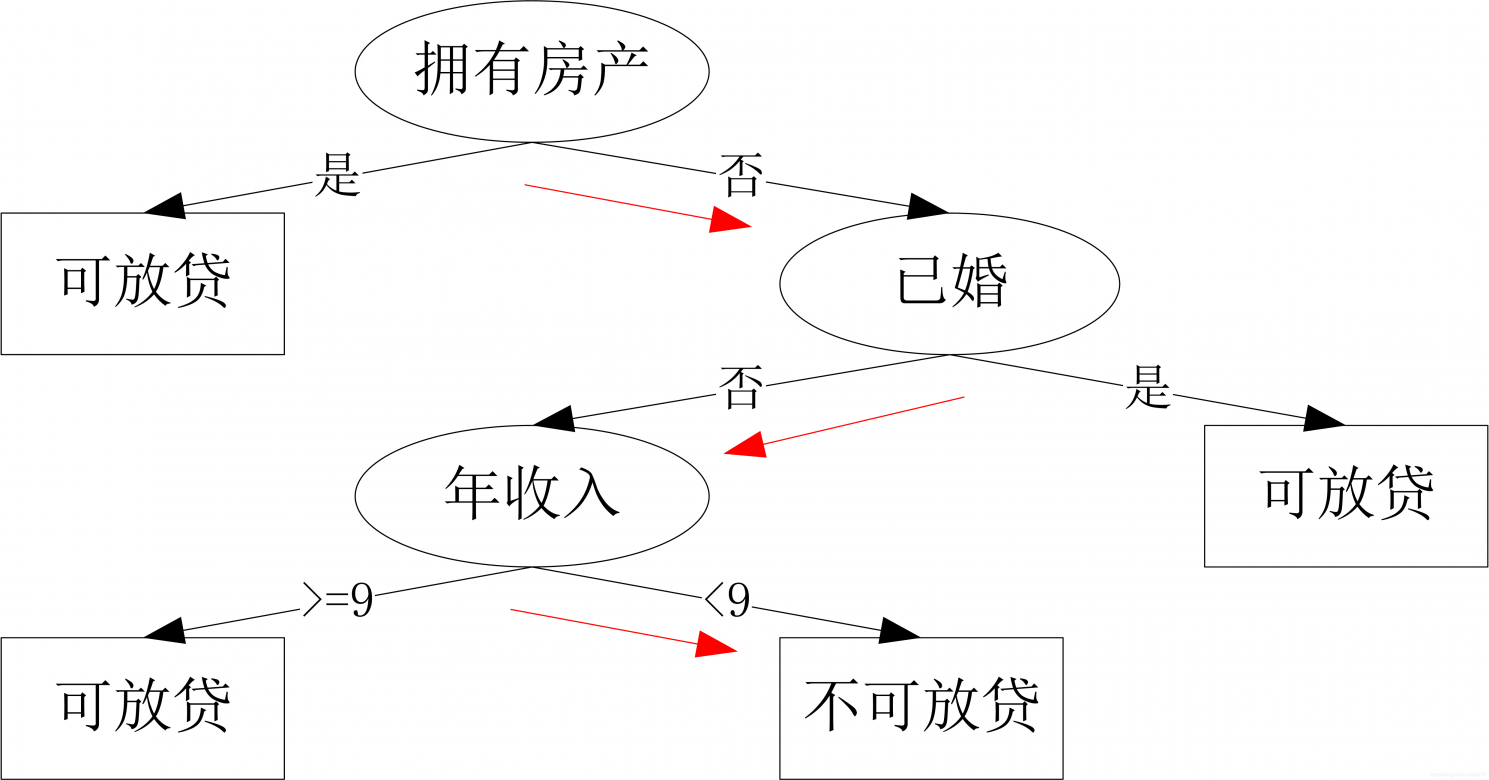
对于一个新用户:无房产,单身,年收入6.5万,根据上述决策树,可以判断无法还贷(红色路径)。从上面的决策树,还可以知道是否拥有房产可以很大程度决定用户是否可以偿还贷款,对借贷业务具有指导意义。
2 熵
信息熵
熵的概念首先由德国物理学家鲁道夫·克劳修在热力学中引入,用于度量一个热力学系统的无序程度。
- 熵越大,系统越无序,意味着系统结构和运动的不确定和无规则;
- 熵越小,系统越有序,意味着具有确定和有规则的运动状态。

更多例子: - 热水的热量会传到空气中,最后使得温度一致
- 整理好的耳机线放进口袋,下次再拿出来已经乱了。让耳机线乱掉的看不见的“力”就是熵力,耳机线喜欢变成更混乱
- 一根弹簧的力,就是熵力。 胡克定律其实也是一种熵力的表现。万有引力也是熵力的一种
1948年,C.E. Shannon 在《A Mathematical Theory of Communication》第一次提出了信息熵。
- **信息熵(Entropy)**是信息的不确定性(Uncertainty)的度量,不确定性越大,信息熵越大。
- 信息用来消除事件的不确定性,即消除熵=获取信息。消除熵可以通过调整事件概率、排除干扰或直接确定来消除。
一条信息消除的事件的不确定性越大(熵减越大),它蕴含的信息量越大。
信息量的大小跟随机事件的概率有关:
- 越小概率的事情(不确定性越大)发生了(熵减越大)产生的信息量越大,如湖南地震;
- 越大概率的事情(不确定性越小)发生了(熵减越小)产生的信息量越小,如太阳从东边升起。
因此,信息的量度应该依赖于事件的概率分布 p ( x ) 。
(1)定义

决策树算法的基本思想是以信息熵为度量构造一颗熵值下降最快的树,叶子节点处熵值为零。属性的信息增益越大,对样本的熵减少的能力更强,使得数据由不确定性变确定性的能力越强。
采用自顶向下的递归方法,具体算法如下
输入:训练数据集D,属性列表A
def createTree(D,A):
创建一个节点N
if D中样本属于同一类别C:
返回N作为C类叶节点
return
if A为空:
返回N作为叶节点,标记为D中样本数最多的类
return
使用划分准侧选择最优划分属性a
A_sub = 从属性集A中删除属性a
for 属性a的每个取值a_v:
D_v = D中在属性a取值为a_v的样本集
if D_v 为空:
增加一个叶节点到节点N,标记为D中样本数最多的类
else:
增加由createTree(D_v,A_sub)返回的节点到N
return4. 划分准则
假设样本集合 D D D的属性 a 有 v个可能取值 { a 1 , a 2 , . . . , a v } ,若使用属性 a 对 D 进行划分,可得到 v v v个子集 { D 1 , D 2 , . . . , D v },其中 D j 中包含 D 中属性 a 取值为 a j 的数据。
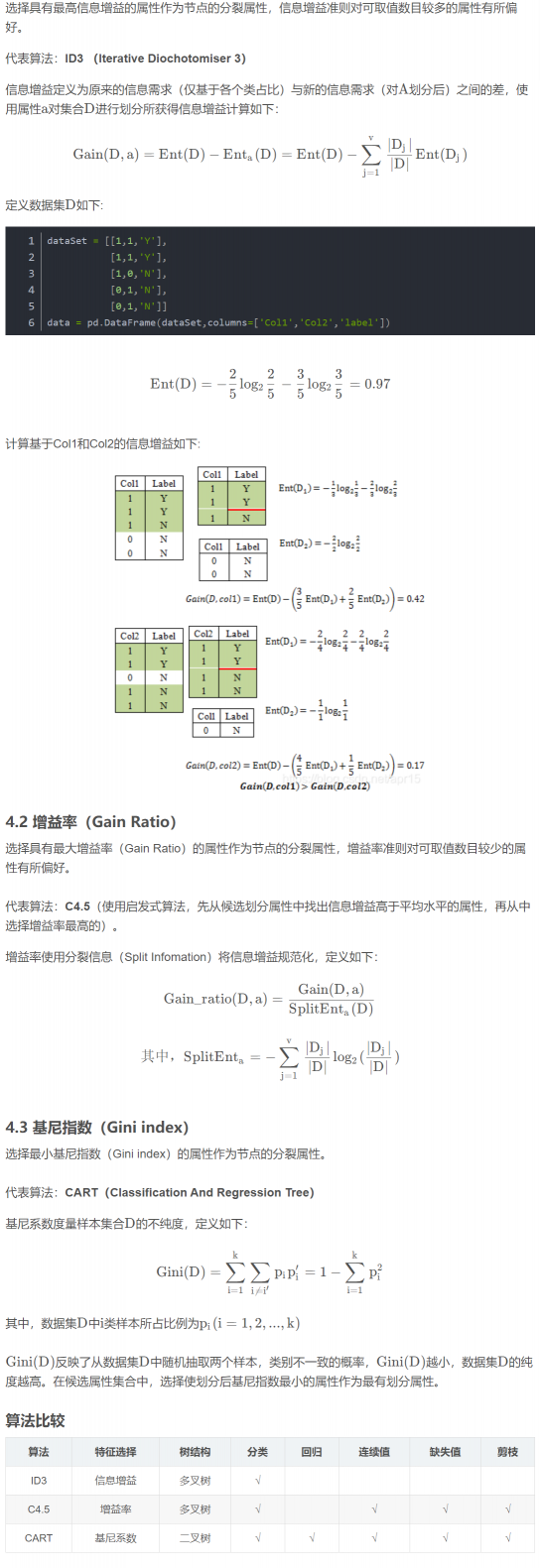
4.1 信息增益(Information Gain)



评论(0)
您还未登录,请登录后发表或查看评论