

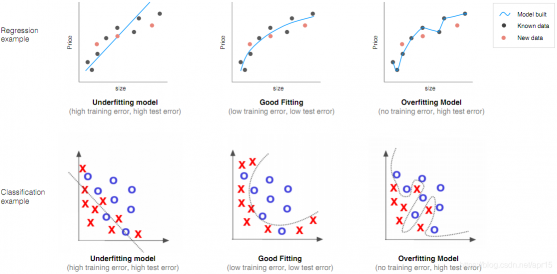
1. 过拟合与欠拟合
- 欠拟合(underfitting):模型未能拟合训练数据,高偏差(high bias)。
- 过拟合(overfitting) :模型未能拟合测试数据,高方差(high variance)。
过度拟合通常发生在特征过多的时候,模型总能很好的拟合训练数据,但泛化能力(模型能够应用到新样本的能力)差,无法应用到新的数据样本中。
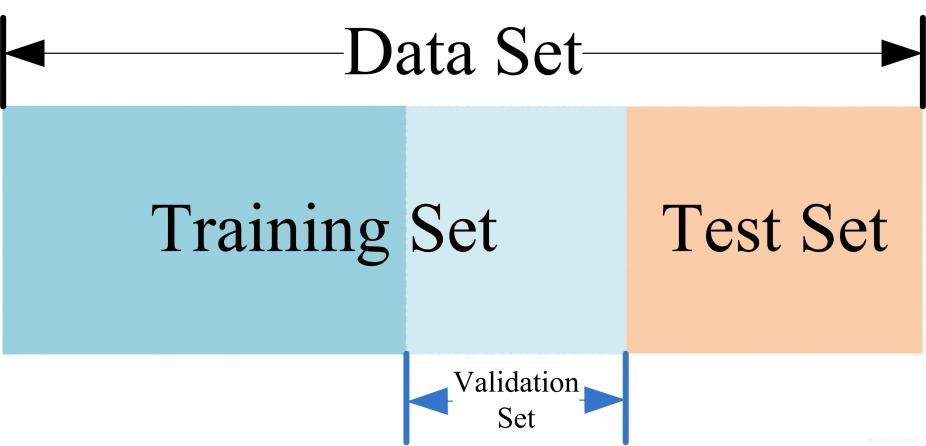
为了防止数据的过拟合(Overfitting),一般将数据集分为两部分:
- 训练集(Training set):用于训练模型
- 测试集(Test set):用于测试模型。
有时在模型的训练过程,为调整参数辅助模型构建(如神经网络中选择隐藏单元数),又会另将训练数据划分为训练集与验证集(Validation Set)。
验证集可以在模型训练中重复使用,而测试集只用于模型检测中,评估模型的准确率,不允许用于模型训练。
实际应用中,一般只将数据集划分为训练集与测试集。
《Pattern Recognition and Neural Networks》(Ripley, B.D,1996)中对三个词的定义如下:
- Training set: A set of examples used for learning, which is to fit the parameters [i.e., weights] of the classifier.
- Validation set: A set of examples used to tune the parameters [i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
- Test set: A set of examples used only to assess the performance [generalization] of a fully specified classifier.
2. 训练集与测试集划分
2.1 保持(Holdout)方法
保持方法是划分训练集与测试集的常用方法,将给定数据随机划分成两个独立的集合,通常以75/25或80/20的比例分配到训练集与测试集。
2.2 交叉验证 (cross-validation)
k-折交叉验证(k-fold cross-validation)中,初始数据随机地划分成k个互不相交的子集(折),S 1 ,S 2 ,...,S k 。训练并检验k次,第i次迭代中,分区S i S_iS i 作为测试集,其余分区用作训练模型。即第1次迭代,子集S 2 ,...,S k 作为训练集,得到第1个模型,并在S 1 上测试;第2次迭代,子集S 1 ,S 3 ,...,S k作为训练集,得到第2个模型,并在S 2上测试;如此下去。每个样本用于训练的次数相同,并且仅用于1次测试。




评论(0)
您还未登录,请登录后发表或查看评论