

前情提要:
【Tutlebot迎宾机器人(一)】总体原理与设计
【Tutlebot迎宾机器人(二)】具体开发实现
【Tutlebot迎宾机器人(三)】模块封装及状态机实现
3. 实验评估
3.1 Gazebo 模型测试
终端进入工作区,输入roslaunch room.launch启动之前在 gazebo 中建好的 world 和 turtlebot3 的 waffle 模型,整个房间的俯视图如图 21 所示,三位客人的正面如图 22 所示。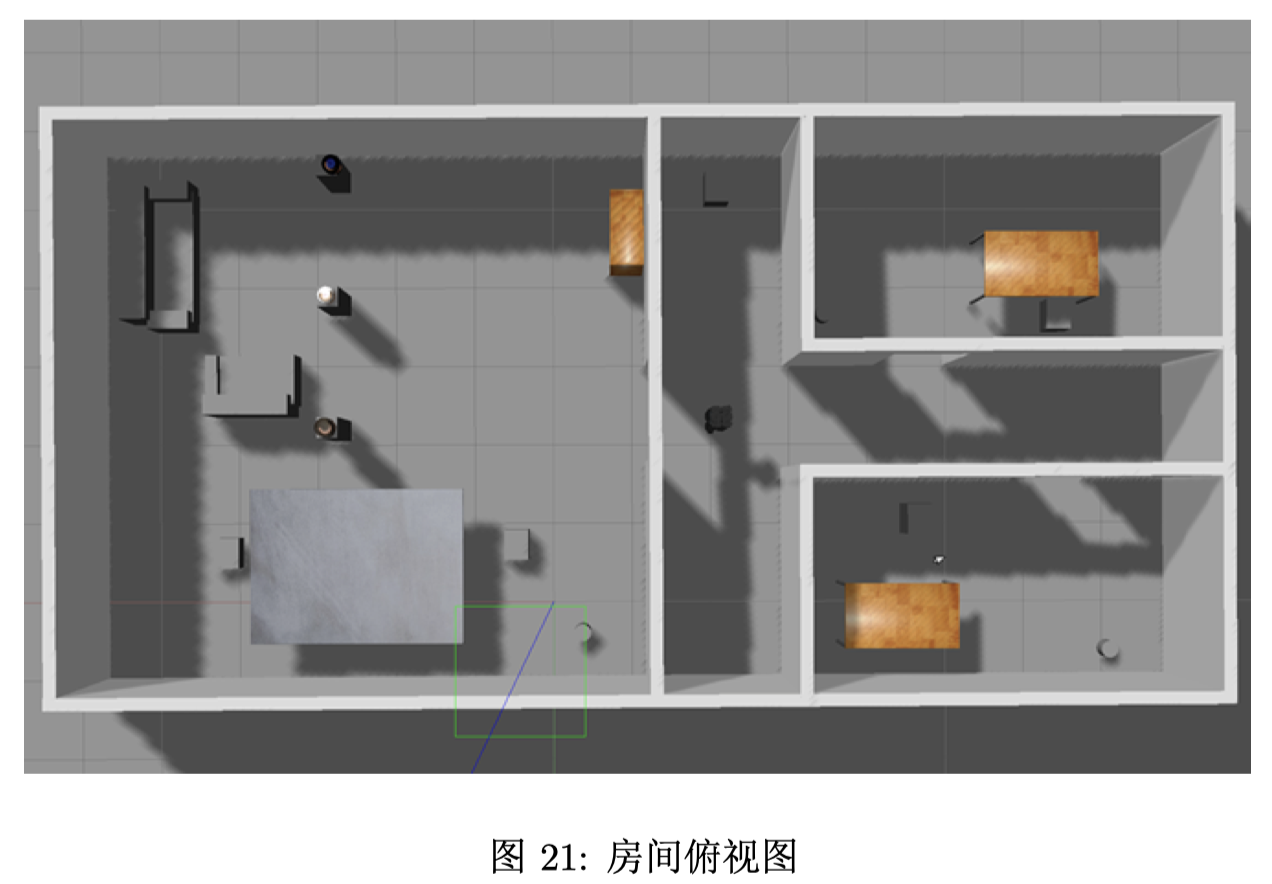

3.2 人脸识别模块测试
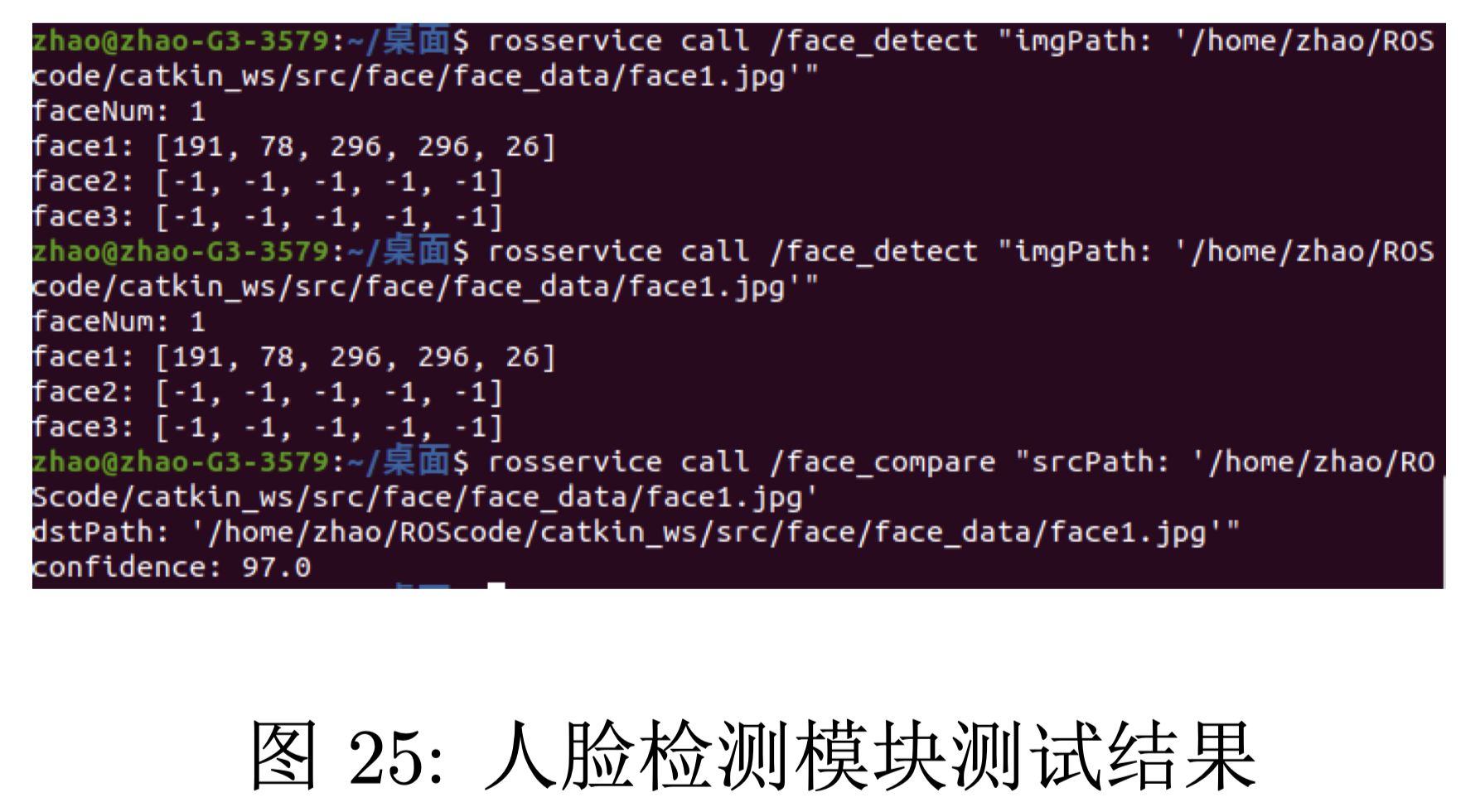
利用 ROS 进行了测试,利用图 23 进行人脸检测得到当前图片中只有一张人脸(faceNum=1)且该 人脸框的左上角位于图像中的(191,78),长宽均为 296,预测年龄为 26 岁。利用图 24 中的人脸与该 人脸进行对比得到两张人脸属于同一个人的概率为 97.0(confidence=97.0)。测试结果输出如 25 所示。

3.3 语音识别模块测试
运行如下命令测试 SDK:
cd Linux_iat1227_tts_online1227_5ff12445/bin
./iat_online_record_sample
运行效果如图 26 所示。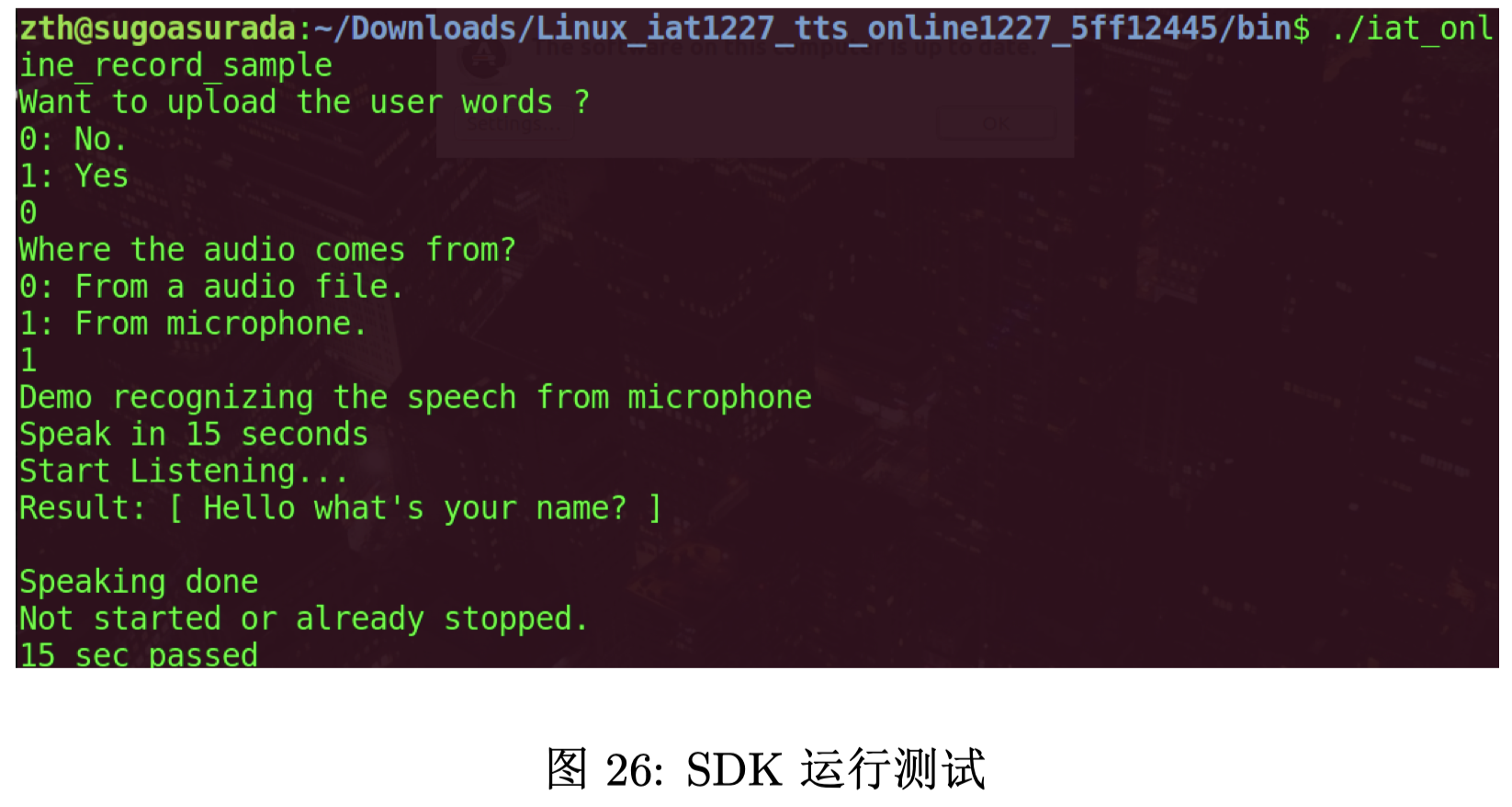
按如下流程测试修改后的 SDK:
1) 运行如下命令进行:
// 终端1:启动管理器节点
roscore
// 终端2:运行可执行文件(订阅voiceWakeup话题,发布voiceWords话题)
rosrun robot_voice iat_publish
// 终端3:voiceWords话题是识别数据
rostopic echo /voiceWords
// 终端4:voiceWakeup话题是唤醒功能,每发一次就可以录音一次
rostopic pub /voiceWakeup std_msgs/String ”data: ’anny string ’”
2) 发布唤醒信号后就可以,可以看到“Start Listening…”,这是对麦克风说话,在线识别后结果会显 示出来,如图 27 所示。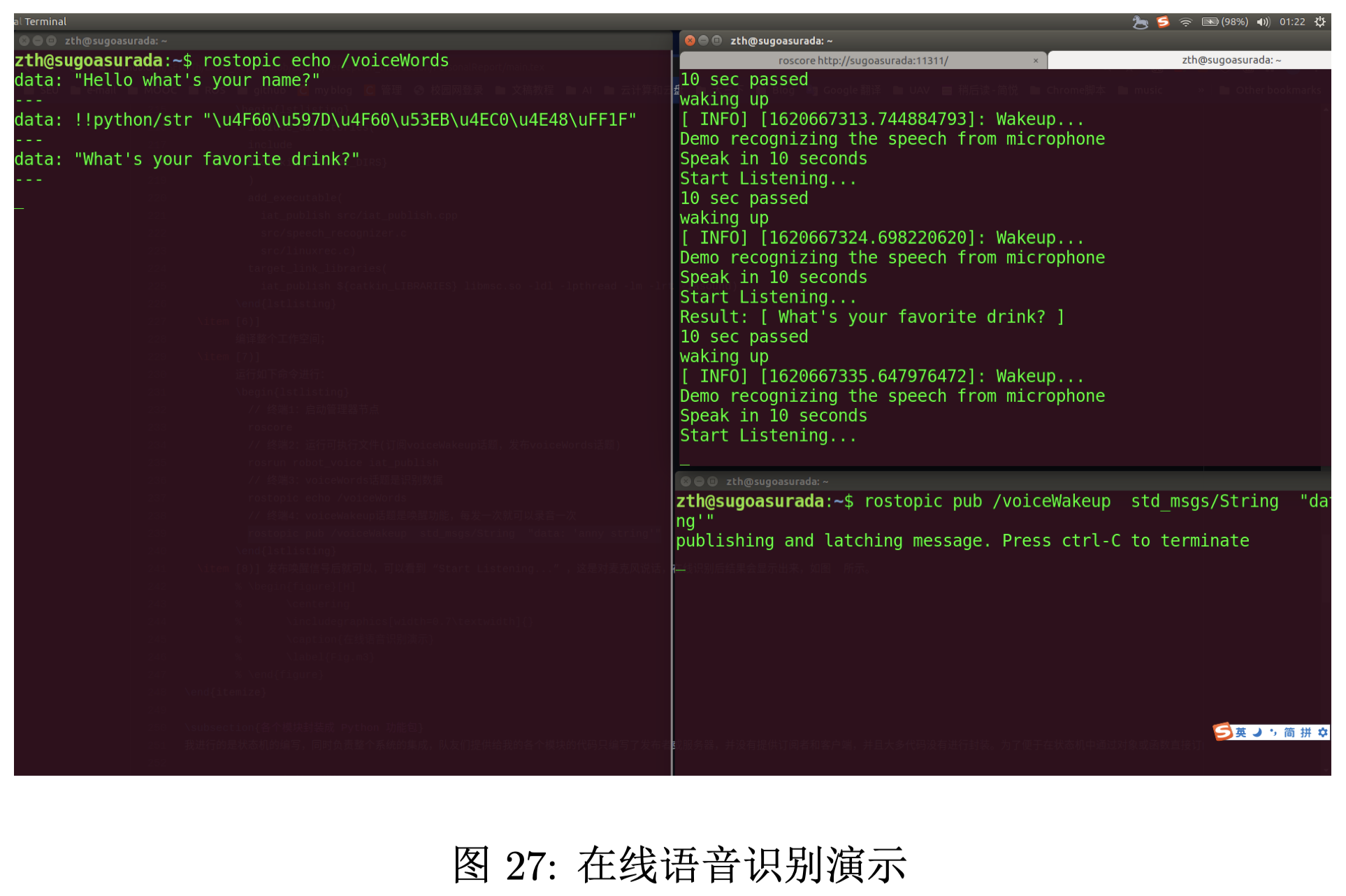
3.4 自主导航模块测试
打开 gazebo 环境模型(如图 32(a) 所示),打开建模地图并启动 rviz 可视化(如图 32(b) 所示),打 开摄像头(如图 32(c) 所示),启动多点导航程序(如图 32(d) 所示),机器人成功实现多点导航。
3.5 状态机模块测试
启动状态机节点后,利用 smach 可视化工具,得到如图 33 所示的状态图,程序在执行过程中,每执 行到一个状态,该状态会出现黄绿色的高亮显示。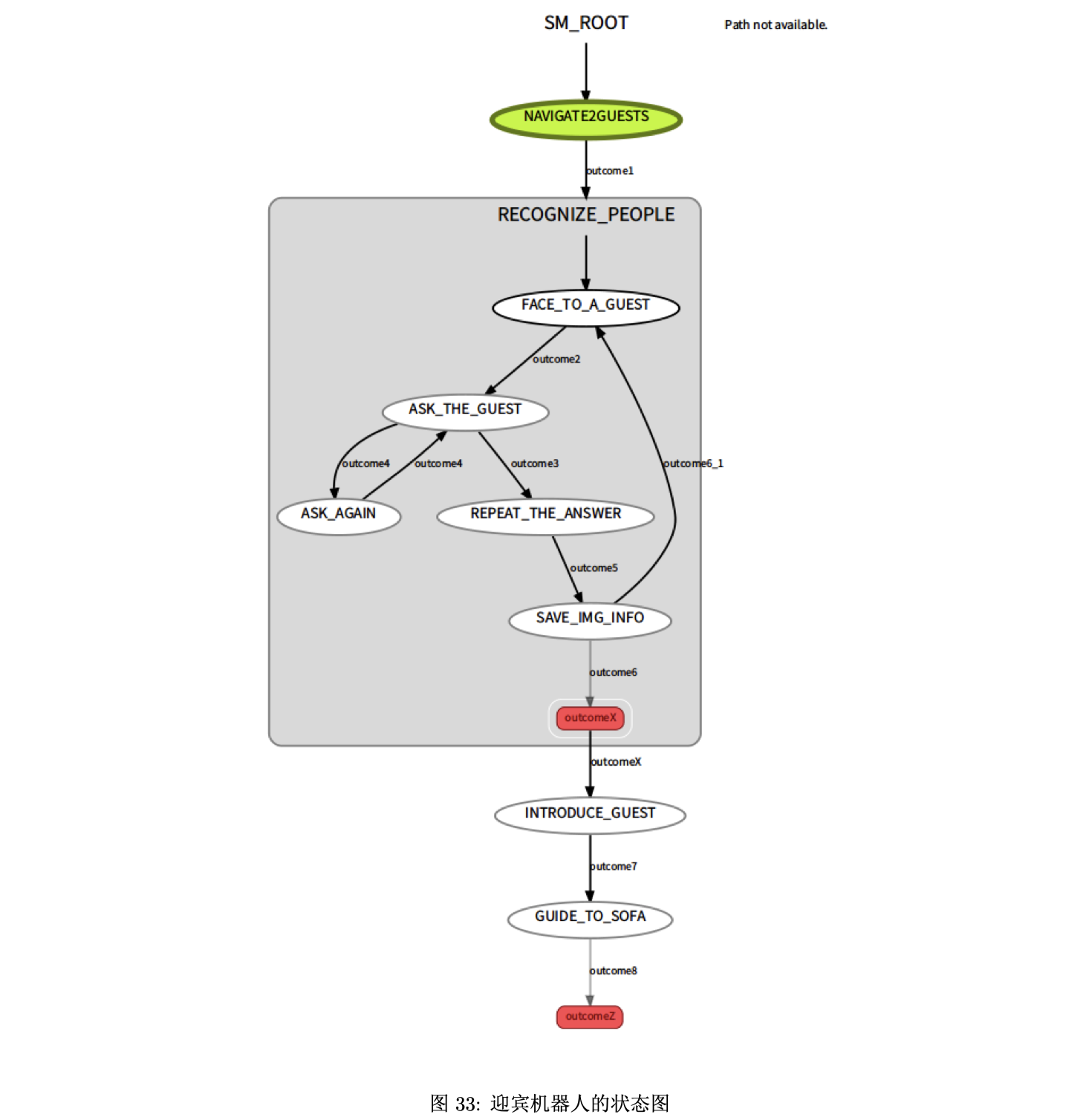
3.6 总体集成测试
运行 roslaunch smach_state smach_state.launch 来启动 Gazebo 世界、Rivz 和各个节点。
程序中设计了对机器人的位置进行初始化,避免人工摆放存在误差。
原地旋转 3 圈以聚集粒子,实现定位。
面向第 1 位客人并询问他的姓名和最爱的饮品。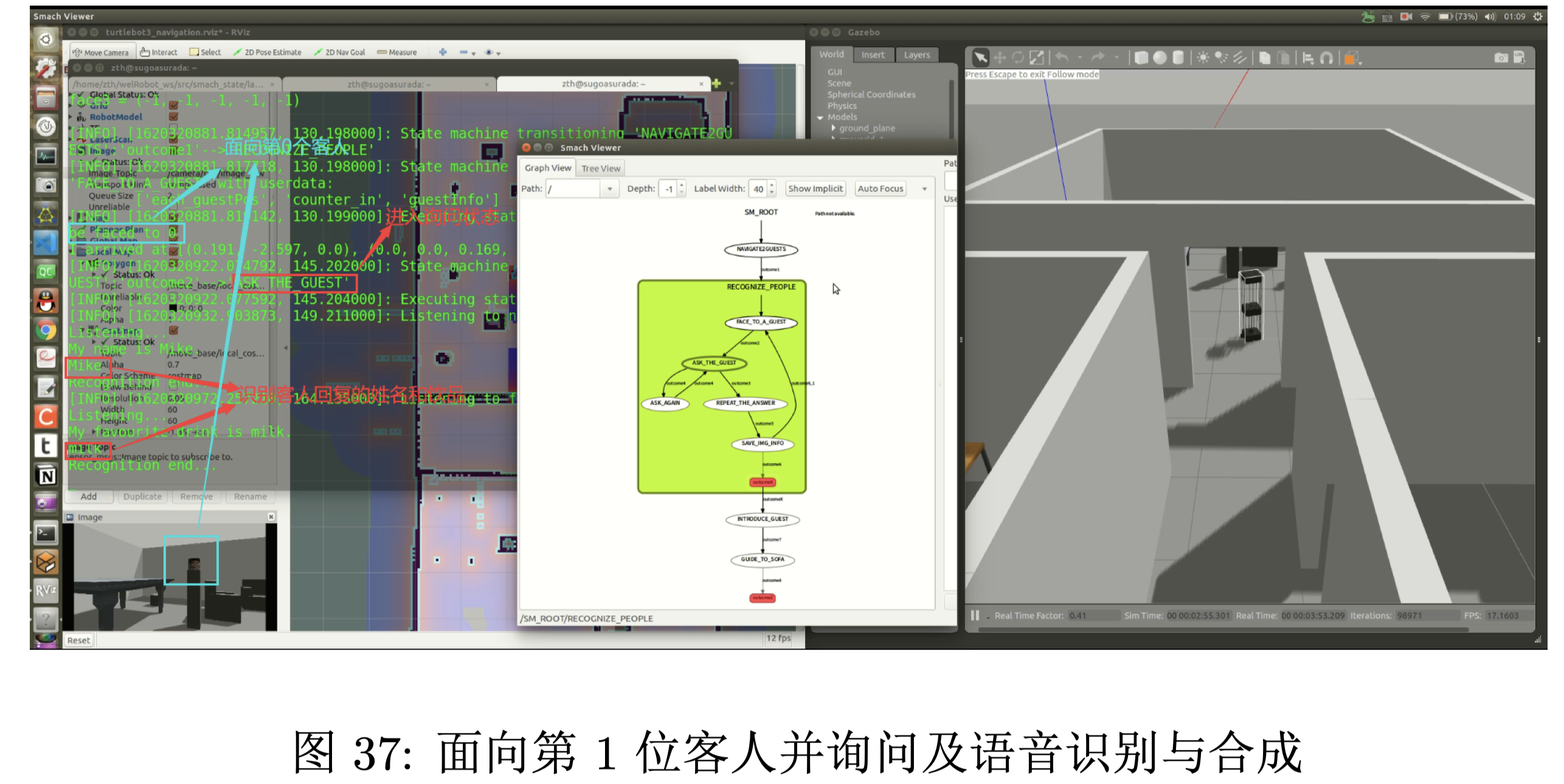
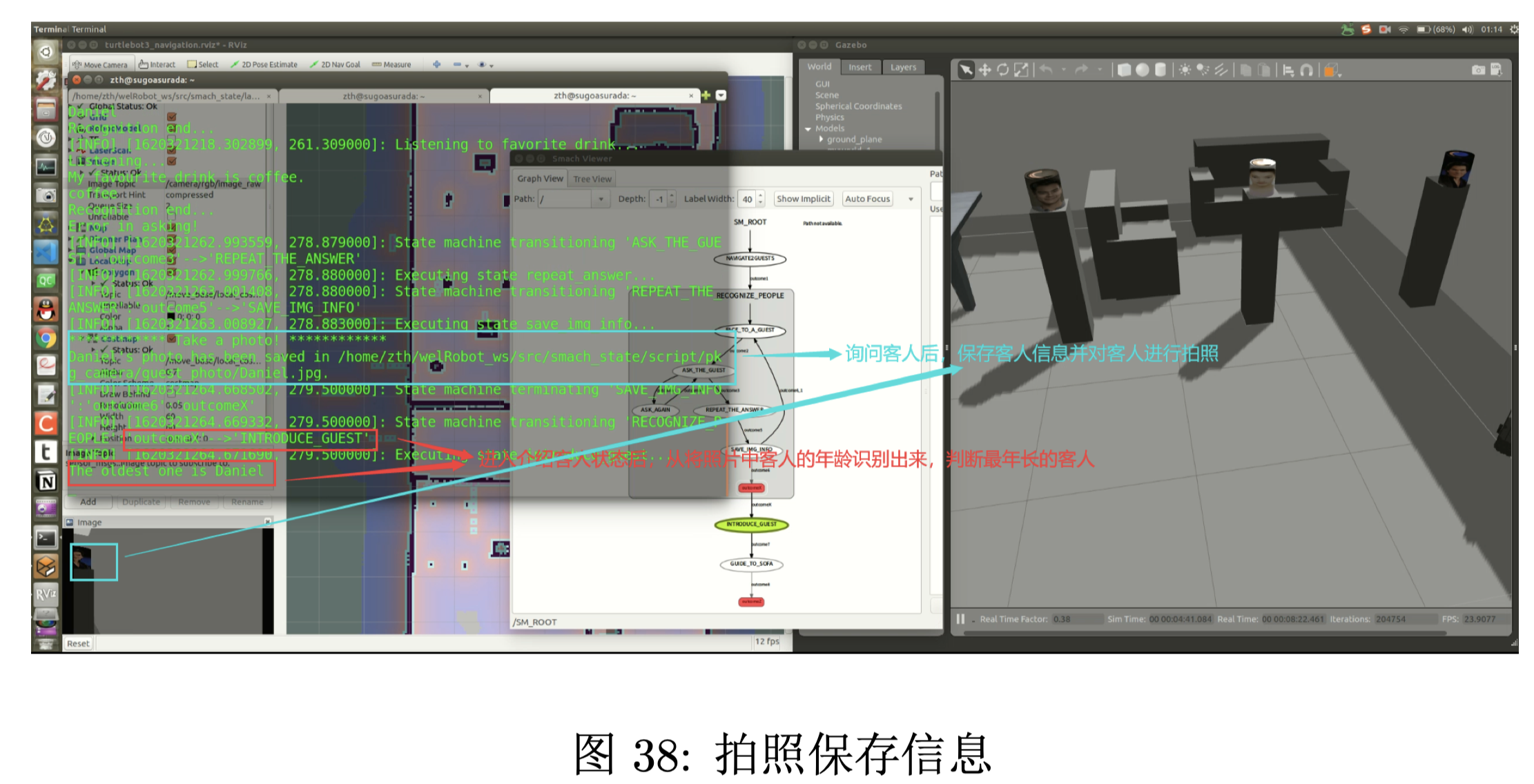
询问客人信息后,对客人进行拍照,并保存客人信息。进入介绍客人状态后,通过人脸识别出年龄并 计算出最年长的那位客人。
依次向每位客人介绍另外两位客人的姓名和最爱的饮品,最年长的客人放在最后向他介绍另外两位 年轻的人。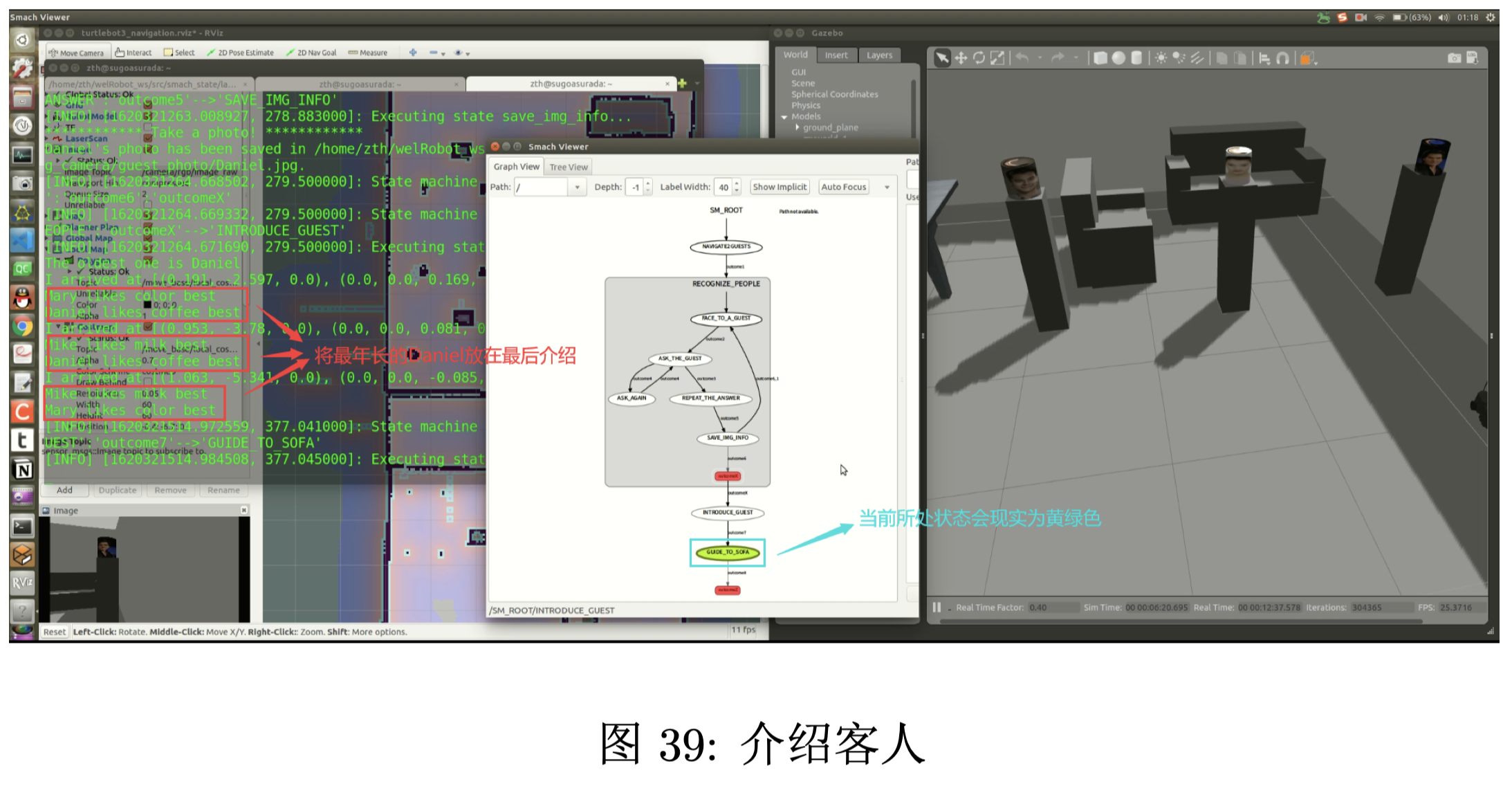
将最年长的客人引导至沙发。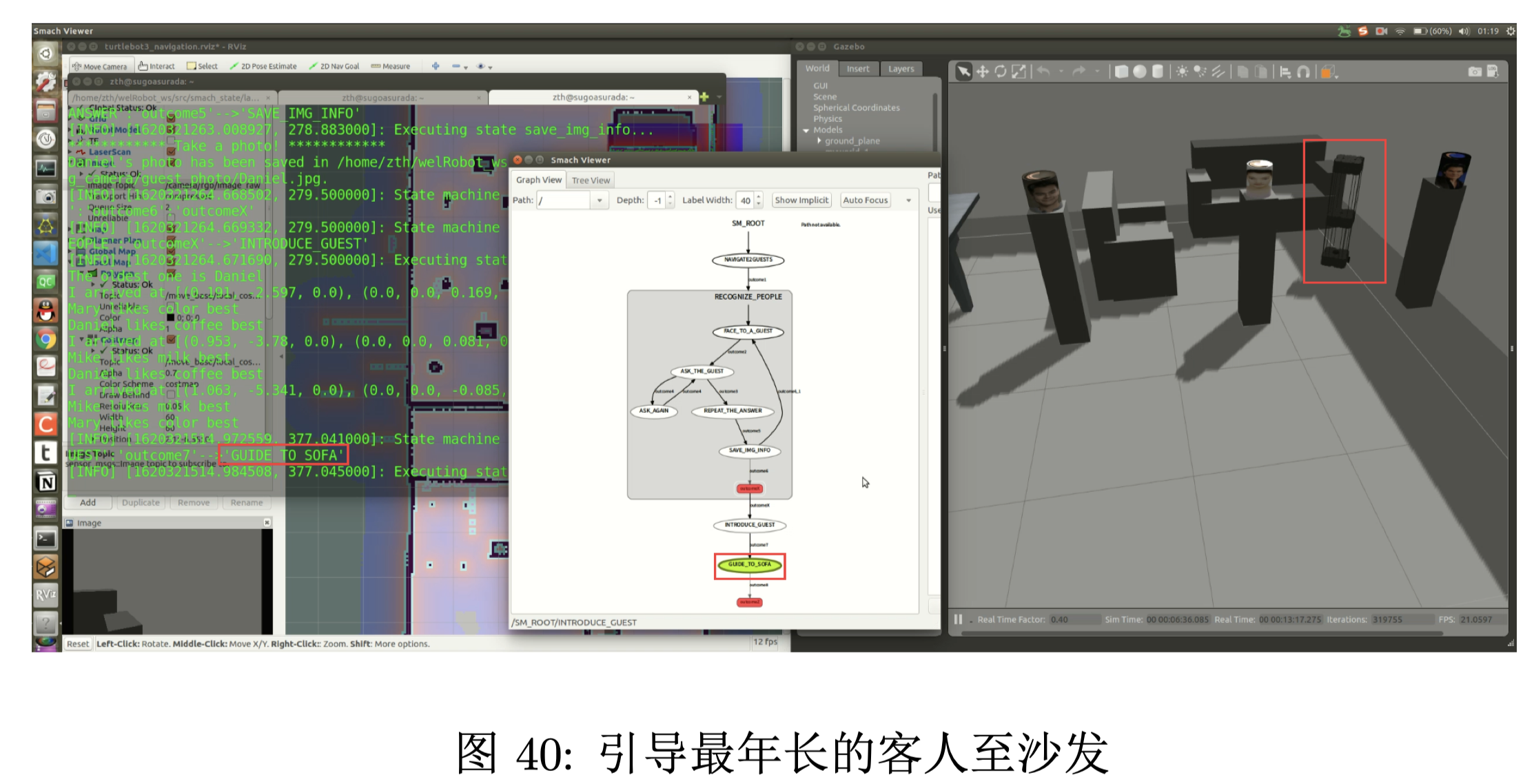
4. 分析总结
在此次实验工作量主要体现在系统的集成方面,对系统进行完整的测试也耗费了几十小时之多。
人脸识别模块是最先完成的,接着状态机模块也完成了框架,将人脸模块放入状态机中,进行了测试。随后自主导航和 Gazebo 世界模型也已经完成。
Gazebo 模型在测试过程中修改了很多次,一开始走廊上特征过于相似,机器人无法精准定位,于是在走廊上添加了其他物体,这也导致重新建图。后来人的高度和机器人摄像头的高度不同, 导致拍照时需要距离人很远,人脸才能进入摄像头的视野,于是又重新对机器人的模型 URDF 文件进行 修改。
科大讯飞的语音识别与合成模块,,按照网上的教程,流程清晰,几乎没碰到什么障碍。不建议采用百度的API,好像只能将音频文件作为输入,无法直接从电脑麦克风输入。
各个模块都完成后,我发现各个模块现有的实现有的没有封装,没有给出接口,调用需要自己编写 代码,并且各种数据和字符变量需要处理,将其写在状态机中,代码调试更加困难,于是我将各个模块封 装成类,各种变量也写在类中作为成员变量,这样使用时只需要导入需要的模块即可。
各个模块的调用封装好之后,按照设计的流程在状态机的各个状态中调用类和函数,来测试整个流 程。由于语音每次从麦克风输入又从音响输出,耗费时间,所以先将音频变量事先给定,大大提高了调试 的速度。
虽然我将所有节点写入的 launch 文件,但是启动时,需要打开 Gazebo 、Rivz、smach_view 等窗口,每次都需要拖动并调整窗口大小,这样属实麻烦,可能这就是为什么有很多针对于此的 QT 界面二次开发,良好的人机交互界面对于用户的使用体验十分重要。
5. 附录
[1] Ubuntu16.04+Ros Kinetic+TurtleBot3 仿真搭建教程
[2] TurtleBot3 仿真环境搭建
[3] ROS应用 —— Ubuntu16.04下 科大讯飞SDK的下载与测试(1)
[4] ROS应用 —— Ubuntu16.04下 科大讯飞语音听写的修改&使用(2)
[5] unable to subscribe to a message
[6] ROS actionlib 学习
[7] actionlibDetailedDescription
[8] actionlib-开发简单的 action 客户端
[9] ROS 回调函数的类方法实现,both in Python 和 C++
[10] Navigation Tuning



评论(0)
您还未登录,请登录后发表或查看评论