

Runner是MMdetection中的一种深度学习算法“工厂”,是对深度学习算法各个组件的“容器”。简单来说,所有的机器学习算法所包含的无非就是数据、模型、训练策略、评估、推理这五个部分。Runner就是将这五个部分组合在一起的工具。
其实光是Runner,可以说的东西不多,但是其背后的设计思路,以及对深度学习算法的概括是值的学习的。所以这篇文章不仅是提炼一下Runner中的操作,也是对一个算法“数据、模型、训练策略、评估、推理”这五个部分的一种总结。
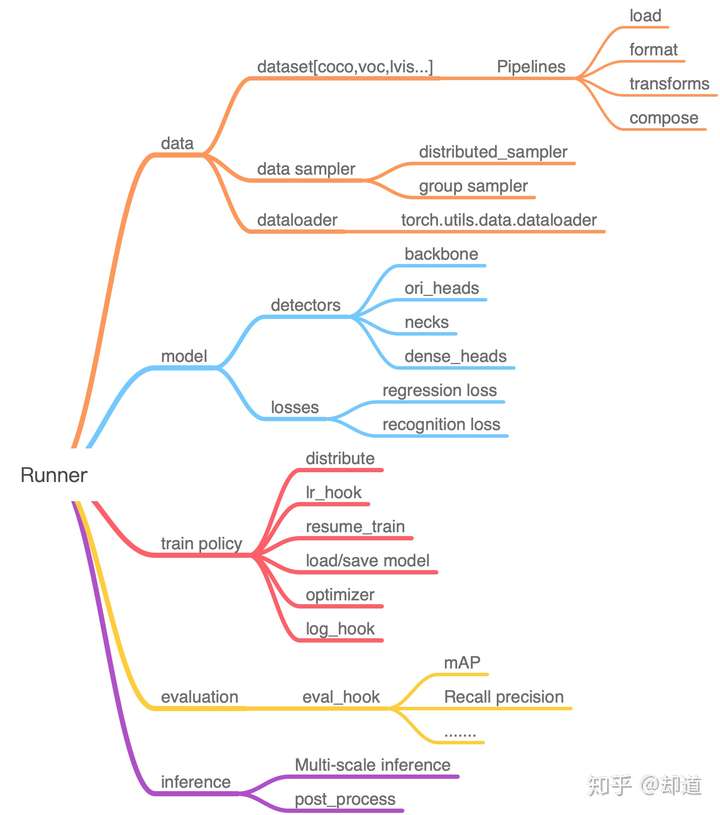
1. Runner整体架构
奉上一个我整理的Runner在MMdetection中的整体架构图,也是根据“数据、模型、训练策略、评估、推理”这五个部分分门别类的,在阅读源码的时候就可以根据这个架构来理清楚思路。
2. 代码逻辑
Runner的源码封装在MMCV库当中,目前主要是有epoch_runner和iter_runner两种,本质上差不多,只是大家的习惯不同罢了,其实在epoch_runner中也有内置计算了iter数。
给小白简单解释下epoch和iter的差别,比如训练数据是1000张图片,Mini-batch是10,那么训练1个epoch就是训练100次,也就是100个iter。所以如果你打算训练1w个iter的话等价于训练100个epoch。
我个人常用的是epoch_runner,那么就以epoch_runner为例理一理各个模块的使用。由于代码过多,所以有些类型判断、warning,参数注释我都删去了,只要理清楚整个代码运行逻辑就行。
@RUNNERS.register_module()
class EpochBasedRunner(BaseRunner):
def run_iter(self, data_batch, train_mode, **kwargs):
if train_mode:
outputs = self.model.train_step(data_batch, self.optimizer,**kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.train_step()"'
'and "model.val_step()" must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'], outputs['num_samples'])
self.outputs = outputs
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
# 以下几个call_hook就是几个典型的应用,HOOK的用法可以详细看下这个专栏里对于HOOK机制剖析的文章
self.call_hook('before_val_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch')
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
"""Start running.
Args:
data_loaders (list[:obj:`DataLoader`]): Dataloaders for training
and validation.
workflow (list[tuple]): A list of (phase, epochs) to specify the
running order and epochs. E.g, [('train', 2), ('val', 1)] means
running 2 epochs for training and 1 epoch for validation,
iteratively.
"""
for i, flow in enumerate(workflow):
mode, epochs = flow
if mode == 'train':
# epoch runner内部还是
self._max_iters = self._max_epochs * len(data_loaders[i])
break
work_dir = self.work_dir if self.work_dir is not None else 'NONE'
self.call_hook('before_run')
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
# 训练则mode='train'
# 评估则mode='val'
epoch_runner = getattr(self, mode)
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
epoch_runner(data_loaders[i], **kwargs)
time.sleep(1) # wait for some hooks like loggers to finish
self.call_hook('after_run')
def save_checkpoint(self,
out_dir,
filename_tmpl='epoch_{}.pth',
save_optimizer=True,
meta=None,
create_symlink=True):
# 保存模型的相关代码
if meta is None:
meta = dict(epoch=self.epoch + 1, iter=self.iter)
elif isinstance(meta, dict):
meta.update(epoch=self.epoch + 1, iter=self.iter)
else:
raise TypeError(
f'meta should be a dict or None, but got {type(meta)}')
if self.meta is not None:
meta.update(self.meta)
filename = filename_tmpl.format(self.epoch + 1)
filepath = osp.join(out_dir, filename)
optimizer = self.optimizer if save_optimizer else None
save_checkpoint(self.model, filepath, optimizer=optimizer, meta=meta)
# in some environments, `os.symlink` is not supported, you may need to
# set `create_symlink` to False
if create_symlink:
dst_file = osp.join(out_dir, 'latest.pth')
if platform.system() != 'Windows':
mmcv.symlink(filename, dst_file)
else:
shutil.copy(filename, dst_file)3. 细节短说
- 数据:对于数据的处理,主要看datasets中的代码,数据处理这块主要是逻辑上要严谨,代码上要细致,功能上要全面。比如对开源的不同数据集的处理方式,输出格式的统一,在做transform的时候要考虑一些边界问题,多数据集训练多卡训练。不同sampler的方式,对训练IO通信的优化(预加载数据到内存),样本均衡。
- 模型:算法框架被分为SingleStage和TwoStage两种,当然每一种都可以细分为AnchorFree或者是AnchorBased。算法这块内容有点多,但是主要还是LOSS和网络结构两个部分的创新。对于算法这块重头戏,打算在今年过年之前,对MMdetection中的所有算法都仔细研读并整理成文章。
- 训练策略:这部分也算是框架内容上,比如warm_up,lr的下降,早停,打印log(支持终端输出和tensorboard),可配置optimizer,保存模型、加载预训练模型、继续训练模型等。
- 评估策略:学术集的话一般是有提供评估代码,比如COCO和cityscapes,我们要做的只是把输出的格式处理成相应的格式就行。但是实际工程当中的话评估策略需要根据业务要求来定。想起在学校的时候说到分类必谈f1-score,但是到了实际工程中f1-score却很少用到,我自己也尝试过,发现这个指标很多时候不如TPR-FPR来得靠谱。
- 推理:目标检测inference最常用的是多尺度预测,当然还有一些细节,比如检测框和网络predict之间是有相应的变换的,推理的时候需要反变换为原图尺度。其实推理这部分和评估很多地方是重复的,只是在代码结构上他们是分开的,而且在有些任务中推理和评估还有一些不同之处,因此才把他们区分开来。
4. 总结
我想看懂runner的逻辑应该还是很简单的,其实最关键的还是理解HOOK机制,理解了HOOK机制才能学会从"使用"这个框架变成"改变这个框架",HOOK机制的剖析可以看这篇文章,原本按照我自己的写作习惯是要自己写一套demo的,但是画完Runner的架构梳理图之后觉得似乎没什么必要。
一方面是Runner本身只是一个逻辑梳理的流程,把深度学习的五大组成部分很好的融合在一起,并且秉持着高内聚、低耦合的原则,提供了很好的代码范例,我觉得我很难写出比这个质量更高的代码。另一方面是觉得MMDetection的源码阅读中Registry、HOOK、Runner仅仅只是属于"代码架构"上的东西,作为一名算法工程师,应该花更多的时间在算法细节、设计上面。
不管工作再忙,也要坚持写作,坚持输出,写完这几个架构上的东西,是时候上主菜了,下周开始每周分享一篇paper reading,力争在过年之前把MMDetection支持的所有算法从原理和代码上都扣得干干净净。
都看到这了,不防点个免费的赞~,谢谢~~~



评论(0)
您还未登录,请登录后发表或查看评论