

引言
强化学习发展到今天已经有了很多比较经典的算法流传于世,在算法的分类上,一般分为基于值函数的强化学习算法和基于策略函数的强化学习算法两种。基于值函数的强化学习算法核心是学习每个状态-动作对的价值,有了每个状态下动作对应的价值后,就可以根据相应的概率选择动作,最终得到较优的算法。而基于策略函数的强化学习算法是通过学习一个随机策略函数,直接得到每个状态下的动作。今天我们要来一起看一下基于值函数的强化学习中的DDQN算法,它是由DQN算法发展而来。
原理介绍
DQN算法是深度学习于Q-learning结合后的一个非常经典的算法。DQN算法的特点可以简单概括为:
1、使用深度神经网络学习输入状态
2、使用经验池来增加样本的利用率并增加样本间的强相关性
3、使用target network来使目标和待训练网络之间区分开来
在此基础上,DDQN对网络做了如下改进:
由于DQN算法在计算Q_target时会存在过估计的问题:
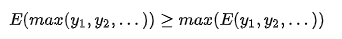
对此,在计算Q_target时采用一种先估计action_max,再使用另一个网络得到action_max对应的Q值。
代码讲解
现在我们来看一下实际的代码,我们使用ptan,并以Deep-Reinforcement-Learning-Hands-On书中附录代码为例,来讲解DDQN算法。首先需要做代码的本地化处理,也就是需要使代码在本地硬件环境,本地的强化学习环境中运行起来,说白了就是消除bug环境;随后再进行代码的讲解。
代码本地化
1、python中模块引用
我们都知道,在同一个文件夹下的python文件可以直接相互引用,我们假设他们分别是a.py和b.py。在通过一个文件夹下时,a.py可以直接引用b,py,通过import b的方式。但是如果说这个文件夹外的另一个文件由引用了a呢?这时候就可能会出现a找不到b的情况。这时我们可以通过在a.py的引用b文件的引用格式上做一些改进,将
import b改为import .b
2、Expected object of scalar type Float but got scalar type Double for argument
这个问题出现在模型的foward函数中,对此我们需要做的改进为,加上:
x = x.float()3、RuntimeError: gather_out_cuda(): Expected dtype int64 for index
这个问题的解决,是通过将变量进行一次处理:
actions_v = actions_v.type(torch.int64)
state_action_values = net(states_v).gather(1, actions_v.unsqueeze(-1)).squeeze(-1)如上所示,actions_v这个变量在使用前,先加上一个处理的语句,就可以解决。
4、action处理
在DQN算法中得到的是动作的变换,为了使其能满足应用的需求,可以在传入环境前对其进行改进:
actions = actions/(UREnv.action_space.shape[0]*10) - 0.05代码讲解
1、动作选取
首先来看模型的动作选取函数:
class EpsilonGreedyActionSelector(ActionSelector):
def __init__(self, epsilon=0.05, selector=None):
self.epsilon = epsilon
self.selector = selector if selector is not None else ArgmaxActionSelector()
def __call__(self, scores):
assert isinstance(scores, np.ndarray)
batch_size, n_actions = scores.shape
actions = self.selector(scores)#初始值为最大值
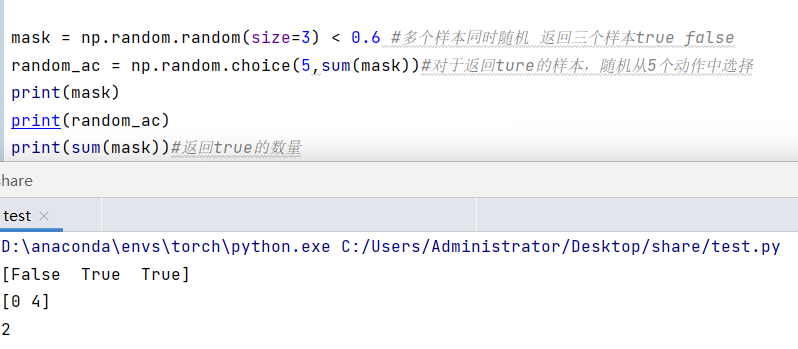
mask = np.random.random(size=batch_size) < self.epsilon#随机化的样本,随机的为true
rand_actions = np.random.choice(n_actions, sum(mask))#随机的样本选取随机动作
actions[mask] = rand_actions#修改动作,返回动作标号
return actions可以看到,代码首先根据传入的样本数,输出对应样本个数size的随机数,并根据每个随机数是否小于epsilon,来决定是否进行随机化动作,反之就采用具有最大价值的动作。
得到bool形的列表之后,对其中True的部分,选择随机动作,并分配。
以下是对上面代码的简单测试:
2、模型设置
首先设计网络,然后设计递减的贪婪系数,设计agent用来与环境交互,最后设计经验池。
#两个网络
net = ddqn_model.DQN(env.observation_space.shape[0], env.action_space.shape[0]).to(device_name)
tgt_net = ptan.agent.TargetNet(net)
#贪婪系数
selector = ptan.actions.EpsilonGreedyActionSelector(epsilon=params['epsilon_start'])
epsilon_tracker = common.EpsilonTracker(selector, params)
#agent
agent = ptan.agent.DQNAgent(net, selector, cuda=args.cuda)
#经验池
exp_source = ptan.experience.ExperienceSourceFirstLast(env, agent, gamma=params['gamma'], steps_count=1)
buffer = ptan.experience.ExperienceReplayBuffer(exp_source, buffer_size=params['replay_size'])3、训练
训练过程为一直在线的训练方式,采集一个样本之后,放入经验池,训练时从中采样。每隔固定步数后,同步网络参数到target_network。实验中记录的数据有:一回合的总奖励、固定步数后的测试奖励。
with common.RewardTracker(writer, params['stop_reward']) as reward_tracker:
while True:
frame_idx += 1
buffer.populate(1)#增加一条记录
epsilon_tracker.frame(frame_idx)#改变贪婪率
# 获取回合奖励,仅用于查看训练效果
new_rewards = exp_source.pop_total_rewards()
if new_rewards:
reward_tracker.reward(new_rewards[0], frame_idx, selector.epsilon)#先不管停止
# if reward_tracker.reward(new_rewards[0], frame_idx, selector.epsilon):#当奖励大于终止奖励停止
# break
#初始时不需要积攒很多
if len(buffer) < params['replay_initial']:
continue
# 设置损失并优化
optimizer.zero_grad()
batch = buffer.sample(params['batch_size'])
loss_v = calc_loss(batch, net, tgt_net.target_model, gamma=params['gamma'], device=device_name,double=args.double)
loss_v.backward()
optimizer.step()
# 同步参数
if frame_idx % params['target_net_sync'] == 0:
tgt_net.sync()
# 评估样本选择
if eval_states is None:
eval_states = buffer.sample(params['STATES_TO_EVALUATE'])
eval_states = [np.array(transition.state, copy=False) for transition in eval_states]
eval_states = np.array(eval_states, copy=False)
# 间隔n后,进行测试
if frame_idx % params['EVAL_EVERY_FRAME'] == 0:
mean_val = calc_values_of_states(eval_states, net, device=device_name)
writer.add_scalar("values_mean", mean_val, frame_idx)
eval_states = None这其中的参数:
初始经验池样本数为:50;
经验池总数为:100;
batch大小:15;
测试样本数:30;
测试间隔:20;
同步间隔:20.
May the force be with you!



评论(0)
您还未登录,请登录后发表或查看评论