

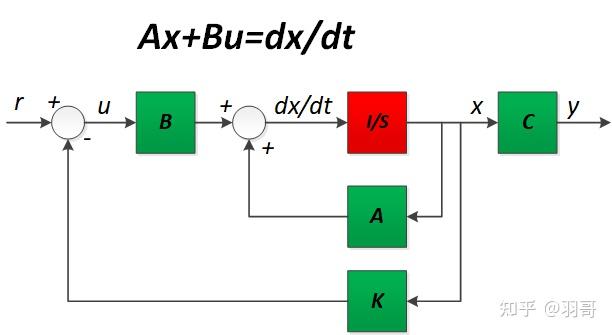
以阿克曼模型车辆作为控制研究对象,车辆在世界坐标系下的速度方程可以表示为:
(1)
上述方程的自变量有 ,
对上述方程求偏导,获得雅可比矩阵:
(2)
在上述公式,令误差
跟踪误差状态方程可以表示为:
(3)
化简误差状态方程:
(4)
令:
则有:
(4)
对(5)中的状态转移函数离散化:
令
则有
(5)
最优控制性能代价函数构建:
有了离散状态方程,现在需要求取反馈矩阵K。
(6)
假设权重矩阵:
(7)
迭代求解代数黎卡提方程(其推导过程较繁琐,有兴趣可以自己推导一下):
代数黎卡提方程如下:
(8)
当 ,其中eps为自己设定的精度值。如果达到该条件(设定的迭代精度和迭代次数)我们认为该方程已经收敛,此时根据获得的P矩阵求反馈控制增益K。
反馈增益矩阵:
(9)
反馈控制量:
(10)
最终的输出控制量为:
(11)
LQR 控制理论已经非常成熟了,套用公式就行,核心点是建立车辆的误差模型,并将误差模型进行线性化,转换为如下形式:
最后套用公式计算获得反馈增益矩阵即可。
如下是LQR代码实现:(代码中的实现很简单,细节请参考上文公式)
double lqrComputeCommand(double vx, double x, double y, double yaw, Traj_Point match_point,
double vel, double l, double dt)
{
double steer = 0.0;
MatrixXd Q = MatrixXd::Zero(3,3);
MatrixXd R = MatrixXd::Zero(1,1);
Q << 1 , 0 , 0,
0 , 1 , 0,
0 , 0 , 1;
R << 1;
double curvature = match_point.path_point.kappa;
if(vel < 0) curvature = -curvature;
double feed_forword = atan2(l * curvature, 1);
MatrixXd A = MatrixXd::Zero(3, 3);
A(0, 0) = 1.0;
A(0, 2) = -vel*sin(match_point.path_point.yaw)*dt;
A(1, 1) = 1;
A(1, 2) = vel*cos(match_point.path_point.yaw)*dt;
A(2, 2) = 1.0;
MatrixXd B = MatrixXd::Zero(3,1);
B(2, 0) = vel*dt/l/pow(cos(feed_forword),2);
double delta_x = x - match_point.path_point.x;
double delta_y = y - match_point.path_point.y;
double delta_yaw = NormalizeAngle(yaw - match_point.path_point.yaw);
VectorXd dx(3); dx << delta_x, delta_y, delta_yaw;
double eps = 0.01;
double diff = std::numeric_limits<double>::max();
MatrixXd P = Q;
MatrixXd AT = A.transpose();
MatrixXd BT = B.transpose();
int num_iter = 0;
while(num_iter++ < param_.maxiter && diff > eps)
{
MatrixXd Pn = AT * P * A - AT * P * B * (R + BT * P * B).inverse() * BT * P * A + Q;
diff = ((Pn - P).array().abs()).maxCoeff();
P = Pn;
}
MatrixXd feed_back = -((R + BT * P * B).inverse() * BT * P * A) * dx;
steer = NormalizeAngle(feed_back(0,0) + feed_forword);
return steer;
}



评论(1)
您还未登录,请登录后发表或查看评论