

1 引言
YOLOv3在YOLOv2的基础上,改良了网络的主干,利用多尺度特征图进行检测,改进了多个独立的Logistic regression分类器来取代softmax来预测类别分类.

YOLOv2的论文链接: 戳我
闲话少述,我们直接开始
2 主干网络
YOLOv3提出了新的主干网络: Darknet-53 ,从第0层到第74层,一共有53层卷积层,其余均为Resnet层.
和Darknet-19相比,Darknet-53去除了所有的maxpooling层,增加了更多的1X1和3X3的卷积层,但因为加深网络层数很容易导致梯度消失或爆炸,所以Darknet-53加入了ResNet中的Residual 块来解决梯度的问题.
由下图的Darknet-53架构可以看到共加入了23个Residual block.
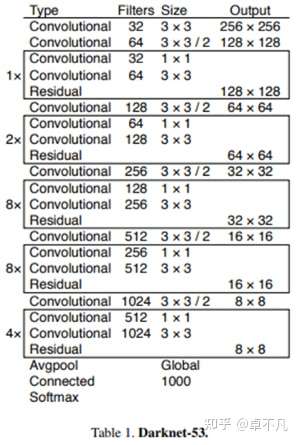
由于加深了网络层数,Darknet-53相比Darknet-19慢了许多,但是Darknet-53处理速度78fps,还是比同精度的ResNet快很多,YOLO3依然保持了高性能.

3 多尺度预测
YOLOv3借鉴了FPN的方法,采用多尺度的特征图对不同大小的物体进行检测,以提升小物体的预测能力.

YOLOv3通过下采样32倍 16倍和8倍得到3个不同尺度的特征图,例如输入416X416的图像,则会得到13X13(416/32),26X26(416/16) 以及52X52(416/8),这3个尺度的特征图.如下所示:

每个尺度的特征图会预测出3个Anchor prior, 而Anchor prior的大小则采用K-means进行聚类分析(YOLOv3延续了YOLOv2的作法).
在COCO数据集上,按照输入图像的尺寸为416X416,得到9种聚类结果(Anchor prior的wxh): (10X13),(16X30),(33X23),(30X61),(62X45),(59X119),(116X90),(156X198)以及(373X326)
不同大小特征图对应不同的Anchor prior
- 13X13的特征图(有较大的感受野)用于预测大物体,所以用较大的Anchor prior 即(116X90),(156X198),(373X326)
- 26X26的特征图(中等的感受野)用于预测中等大小物体,所以用中等的Anchor prior 即(30X61),(62X45),(59X119)
- 52X52的特征图(较小的感受野)用于预测小物体,所以用较小的Anchor prior 即(10X13),(16X30),(33X23)
4 网络结构
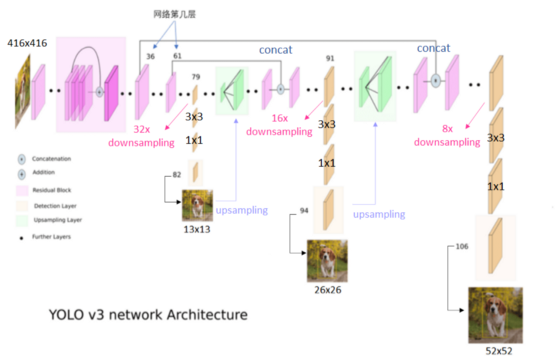
我们先来看YOLOv3的网络结构如下所示:

- 若输入416X416的图像,在79层卷积后,会先经过32倍的下采样,在通过3X3,1X1的卷积层后,得到13X13的特征图(第82层)
- 为了实现能够检测小物体,借鉴了FPN的方法,将第79层13X13的特征图进行上采样,与第61层的特征图进行合并(concat),在经过16倍的下采样以及3X3,1X1的卷积后,得到26X26的特征图(第94层)
- 接着第91层26X26的特征图再次上采样,并与第36层26X26的特征图进行合并(concat),在经过8倍下采样以及3X3,1X1的卷积层后,得到52X52的特征图(第106层)

YOLOv2 VS YOLOv3
- YOLOv2采用passthrough结构来检测小物体的特征,而YOLOv3采用3个不同尺度的特征图来进行检测
- YOLOv2预测输出的bounding box共有13X13X5=845个, 而YOLOv3有13X13X3+26X26X3+52X52X3=10647个
YOLOv1 VS YOLOv2 VS YOLOv3
- YOLOv1在特征图(7X7)的每一个网格里预测出2个bounding box以及分类概率值,每隔bounding box预测5个值
- YOLOv1总输出为 7X7X(2X5+20)
- YOLOv2在特征图(13X13)的每一个网格里预测5个bounding box(对应5个Anchor Box),每个bounding box预测出5个值以及分类概率值
- YOLOv2总输出为 13X13X5X(5+20)
- YOLOV3在3个特征图的每一个网格中预测出3个bounding box(对应3个Anchor prior),每个bounding box预测5个值以及分类概率值(YOLOv3采用的为COCO数据集,共有80类)
- YOLOv3总输出为13X13X3X(5+80)+26X26X3X(5+80)+52X52X3X(5+80)
5 框的预测
YOLOv3使用Logistic regression来预测每个bounding box的confidence,以bounding box与gt的IOU为判定标准,对每个gt只分配一个最好的bounding box.通过利用这种方式,在做Detect之前可以减少不必要的Anchor进而减少计算量.
- 正样本: 将IOU最高的bounding box, confidence score设置为1
- 忽略样本: 其他不是最高IOU的bounding box 并且IOU大于阈值(0.5),则忽略这些bounding box, 不计算loss
- 负样本: 若bounding box 没有与任一gt对应,则减少其confidence score
为什么YOLOv3要将正例confidence score设置为1?
- 因为confidence score是指该bounding box是否预测出一个物体的置信度,是一个二分类.并且在学习小物体时,有很大程度会影响IOU.如果像YOLOv1使用bounding box与gt的IOU作为confidence,那么confidence score始终很小,无法有效学习,导致检测的Recall不高.
为什么存在忽略样本?
- 由于YOLOV3采用了多尺度的特征图进行检测,而不同尺度的特征图之间会有重合检测的部分.
- 例如检测一个物体时,在训练时它被分配到的检测框是第一个特征图的第三个bounding box, IOU为0.98, 此时恰好第二个特征图的第一个bounding box与该gt的IOU为0.95,也检测到了该gt,如果此时给其confidence score强行打0,网络学习的效果会不理想.
6 类别的预测
YOLO之前都是使用softmax去分类每个bounding box,但softmax只适用于单目标多分类(甚至类别是互斥的假设),而预测目标里可能有重叠的标识(属于多个类并且类别之间有相互关系),比如Person和Women
因此YOLOv3改采用多个独立的Logistic regression分类器(可以对多标识进行多分类预测)替代,使用二分类交叉熵作为损失函数,并且保证准确率不会下降.

7 损失函数
在介绍损失函数之前,我们先来引入以下参数:
bounding box中心点坐标xy与宽高
- 一样沿用YOLOv2的offset做计算
为gt框的中心点坐标,
为预测框的中心点坐标
为gt框的宽和高,
为预测框的宽和高
为第i个网格中第j个bounding box是否为正例,若是则输出1,否则为0
使模型着重于物体定位能力
bounding box物体的置信度
为第i个网格中第j个bounding box是否为负例,若是则输出1,否则为0
- 若是忽略样例(不是正例及负例),则皆输出0 (不产生任何loss)
- 无物体的系数
使得模型专注于有物体的识别,并降低找到没有物体的情形
YOLOv3在bounding box坐标与宽高的loss 计算时多乘了 系数并且在confidence score跟class的损失函数中使用二分类的交叉熵,如下所示:

YOLOv2 VS YOLOv3

8 模型评价
由下图可以看到:若采用COCO AP做为评价标准,YOLOv3在处理608X608图像速度可以达到20FPS;若采用COCO mAP50做评估标准, YOLOv3的表现达到57.9%,与RetinaRet的结果相近,并且速度快4倍,在实现相同准确度下YOLOv3要显著地比其他检测方法快.



9 总结
本文介绍了YOLO V3的网络架构和相应的具体实现细节,重点介绍了利用多尺度特征图进行检测以及利用多个独立的Logistic regression分类器来取代softmax来预测类别分类.
您学废了吗?



评论(0)
您还未登录,请登录后发表或查看评论