

yolo_v2论文发表在CVPR2017。v2算法在v1的基础上可以说是飞跃性提升,吸取诸子百家之优势。同时,v2的论文也是目前为止yolo系列论文里干货最多的文章。
论文标题:《YOLO9000: Better, Faster, Stronger》
论文地址: https://arxiv.org/pdf/1612.08242v1.pdf
yolo_v2的一大特点是可以”tradeoff“,翻译成中文就是”折中”。v2可以在速度和准确率上进行tradeoff,比如在67帧率下,v2在VOC2007数据集的mAP可以达到76.8; 在40帧率下,mAP可以达到78.6。这样,v2就可以适应多种场景需求,在不需要快的时候,它可以把精度做很高,在不需要很准确的时候,它可以做到很快。
v2在v1上的提升:
batch normalization: BN能够给模型收敛带来显著地提升,同时也消除了其他形式正则化的必要。作者在每层卷积层的后面加入BN后,在mAP上提升了2%。BN也有助于正则化模型。有了BN便可以去掉用dropout来避免模型过拟合的操作。BN层的添加直接将mAP硬拔了2个百分点,这一操作在yolo_v3上依然有所保留,BN层从v2开始便成了yolo算法的标配。
high resolution classifier:所有最顶尖的检测算法都使用了基于ImageNet预训练的分类器。从AlexNet开始,大多数分类器的输入尺寸都是小于256x256的。最早的YOLO算法用的是224x224,现在已经提升到448了。这意味着网络学习目标检测的时候必须调整到新的分辨率。
对于YOLOv2,作者一开始在协调分类网络(指DarkNet-19)用的448X448全分辨率在ImageNet上跑了10个epoch。这使得网络有时间去调整自己的filter来使得自己能够在更高分辨率的输入上表现更佳。然后,作者们把这种更高分辨率的分类网络用到detection上,发现mAP提升了4% 。
Convolutional With Anchor Boxes: 在yolo_v2的优化尝试中加入了anchor机制。YOLO通过全连接层直接预测Bounding Box的坐标值。Faster R-CNN并不是直接预测坐标值。Faster R-CNN只是用RPN种的全连接来为每一个box预测offset(坐标的偏移量或精修量)以及置信度(得分)。(说明:faster r-cnn的box主体来自anchor,RPN只是提供精修anchor的offset量)
由于预测层是卷积性的,所以RPN预测offset是全局性的。预测offset而不是坐标简化了实际问题,并且更便于网络学习。
作者去除了YOLO的全连接层,使用anchor框来预测bounding box。首先,作者去除了一层池化层以保证卷积输出具有较高的分辨率。作者把448X448的图像收缩到416大小。因为作者想让输出特征图的维度是奇数(416/32=13,13为奇数),这样的话会有一个中间单元格(center cell)。物体(尤其是大物体)经常占据图像的中心,所以有一个单独位置恰好在中心位置能够很好地预测物体。YOLO的卷积层下采样这些图像以32(即2的五次方)为采样系数(416/32 = 13),所以输出feature map为13x13。
使用了anchor boxes机制之后,准确率有一点点下降。YOLO(指YOLO v1)只能在每张图给出98个预测框,但是使用了anchor boxes机制之后模型能预测超过1000个框。

尽管mAP稍微下降了一些,但是在召回率上的提升意味着模型有更多提升的空间。
Dimension Clusters: 当作者对yolo使用anchor机制时,遇到了两个问题。1,模板框(prior)的大小是手动挑选的(指anchor prior的大小一开始使人为手动设定的,Faster R-CNN中k=9,大小尺寸一共有3x3种)。box的规格虽然后期可以通过线性回归来调整,但如果一开始就选用更合适的prior(模板框)的话,可以使网络学习更轻松一些。(本文将prior翻译成模板框,是我自己的体会,仅供参考)
作者并没有手动设定prior,而是在训练集的b-box上用了k-means聚类来自动找到prior。如果用标准k-means(使用欧几里得距离),较大box会比较小box出现更多的错误。然而,我们真正想要的是能够使IOU得分更高的优选项,与box的大小没有关系。因此,对于距离判断,作者用了:
d(box, centroid) = 1 - IOU(box, centroid)
作者对k-means算法取了各种k值,并且画了一个曲线图
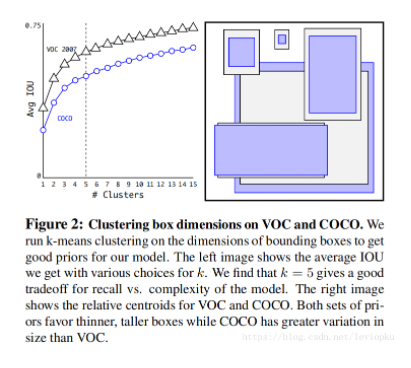
最终选择了k=5,这是在模型复杂度和高召回率之间取了一个折中。聚类得到的框和之前手动挑选的框大不一样。有稍微短宽的和高瘦一些的(框)。
我们比较了前后的平均IOU,如下表:
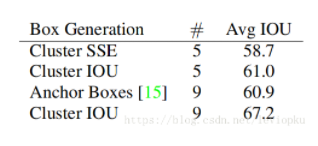
在k=5时聚类效果和Faster R-CNN中的9-anchor效果接近,而使用9-anchor的聚类,会有一个明显的提升。这表明了使用k-means聚类来生成b-box的初始框,这个模型能有更好的表型以及更容易学习。
Direct location prediction: 当在YOLO中使用anchor boxes机制的时候,遇到了第二个问题:模型不稳定。尤其时早期迭代的时候。不稳定的因素主要来自于为box预测(x,y)位置的时候。在RPN中,网络预测了值tx和ty以及(x, y)坐标,计算式如下:
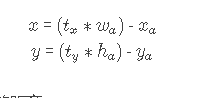
例如,预测出 txtx = 1意味着把框整体向右移动了一个框的距离。
这个公式没有加以限制条件,所以任何anchor box都可以偏移到图像任意的位置上。随机初始化模型会需要很长一段时间才能稳定产生可靠的offsets(偏移量)。
我们并没有“预测偏移量”,而是遵循了YOLO的方法: 直接预测对于网格单元的相对位置。
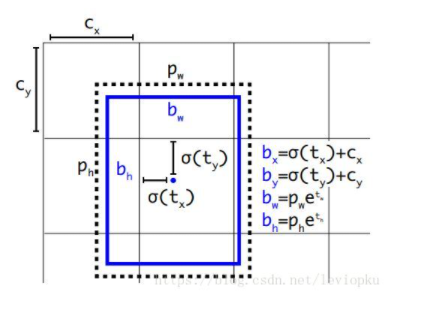
直接预测(x, y),就像yolo_v1的做法,不过v2是预测一个相对位置,相对单元格的左上角的坐标(如上图所示)。当(x, y)被直接预测出来,那整个bounding box还差w和h需要确定。yolo_v2的做法是既有保守又有激进,x和y直接暴力预测,而w和h通过bounding box prior的调整来确定。yolo为每个bounding box预测出5个坐标( tx, ty, tw,th, to)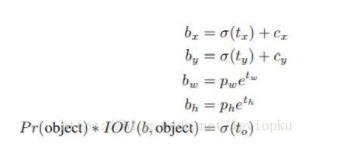
看上面的公式也可以看出,b-box的宽和高也是同时确定出来,并不会像 RPN那样通过regression来确定。 pw和 ph都是kmeans聚类之后的prior(模板框)的宽和高,yolo直接预测出偏移量 tw和 th,相当于直接预测了bounding box的宽和高。 使用聚类搭配直接位置预测法的操作,使得模型上升了5个百分点。
论文刚看到这儿的时候,我也很纳闷,好像又没用anchor,作者在前面花大篇幅讲的anchor机制在这里又被否定了。不过看到等我看到下面表格的时候我才明白:

从第四行可以看出, anchor机制只是试验性在yolo_v2上铺设,一旦有了dimension priors就把anchor抛弃了。最后达到78.6mAP的成熟模型上也没用anchor boxes。
Fine-Grained Features:调整后的yolo将在13x13的特征图上做检测任务。虽然这对大物体检测来说用不着这么细粒度的特征图,但这对小物体检测十分有帮助。Fast R-CNN和SSD都是在各种特征图上做推荐网络以得到一个范围内的分辨率。我们采用不同的方法,只添加了一个passthrough层,从26x26的分辨率得到特征。
multi-scale training:用多种分辨率的输入图片进行训练。
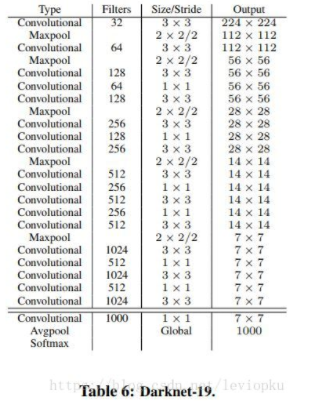
darknet-19:用darknet-19作为yolo_v2的backbone网络。一般的检测任务模型都会有一个分类网络作为backbone网络,比如faster R-CNN拿VGG作为backbone。yolo_v2用的自家的分类网络darjnet-19作为base,体现出自家的优越性。同时在darknet-19中使用batch normalization来加速收敛
。



评论(0)
您还未登录,请登录后发表或查看评论