


昨天说到tensorflow-ssd的实现,在此基础上训练自己模型,无奈知识水平有限,只好转战keras版本,感谢大佬Bubbliiiing的博客和b站内容,受益匪浅,成功完成了自己数据集的训练。
处理方式基本都是一样的,跟前面写过的yolov3的处理基本一样。
SSD的主干网络是VGG,我在前面用过tensorflow训练分类,对于我这种入门选手来说,最大的难题不是搭建网络,而是调试过程中各种基础内容的不懂。
首先是利用作者提供的模型,预测一下,嗯嗯,效果还不错。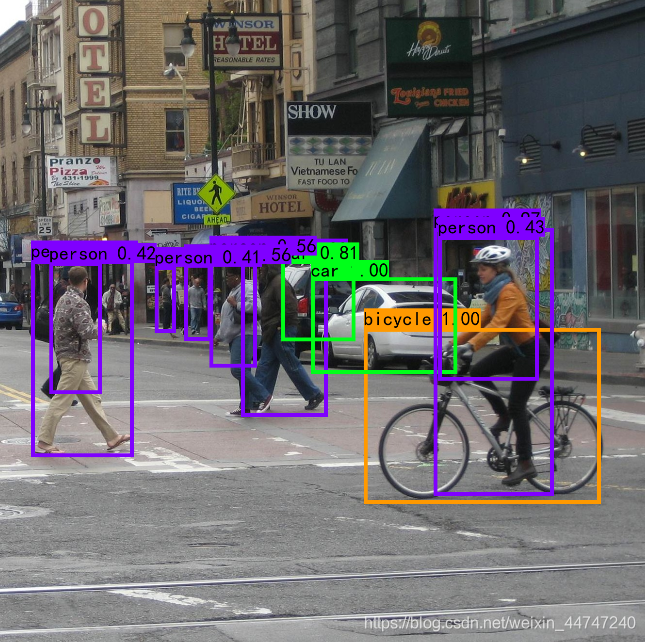
数据集准备
通过标注工具,对图片集进行目标标注,生成xml文件,分别放入JPEGImages和Annonations中,运行voc2ssd.py生成训练文本。
import os
import random
xmlfilepath=r'./Annotations'
saveBasePath=r"./ImageSets/Main/"
trainval_percent=1
train_percent=1
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
生成text文本
修改voc_annotation.py中要训练的种类并运行,生成train\val\test\三个文本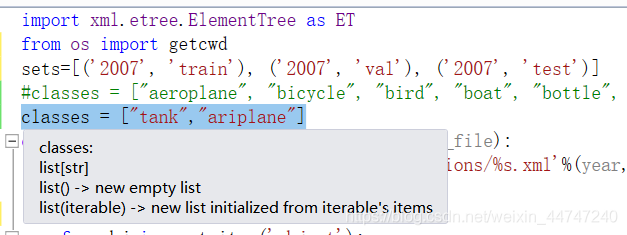
格式如下:
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
#classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["tank","ariplane"]
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
修改train.py
将要训练的种类改成class+1,运行train.py,设置好epoch,即可开始训练了。

from keras.backend.tensorflow_backend import set_session
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.models import Model
from keras.preprocessing import image
from nets.ssd import SSD300
from nets.ssd_training import MultiboxLoss,Generator
from utils import BBoxUtility
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import pickle
import tensorflow as tf
import cv2
import keras
import os
import sys
if __name__ == "__main__":
log_dir = "logs/"
annotation_path = '2007_train.txt'
NUM_CLASSES = 3
input_shape = (300, 300, 3)
priors = pickle.load(open('model_data/prior_boxes_ssd300.pkl', 'rb'))
bbox_util = BBoxUtility(NUM_CLASSES, priors)
# 0.1用于验证,0.9用于训练
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
model = SSD300(input_shape, num_classes=NUM_CLASSES)
model.load_weights('model_data/1.h5', by_name=True, skip_mismatch=True)
# 训练参数设置
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=6, verbose=1)
BATCH_SIZE = 4
gen = Generator(bbox_util, BATCH_SIZE, lines[:num_train], lines[num_train:],
(input_shape[0], input_shape[1]),NUM_CLASSES, do_crop=True)
if True:
model.compile(optimizer=Adam(lr=1e-4),loss=MultiboxLoss(NUM_CLASSES, neg_pos_ratio=5.0).compute_loss)
model.fit_generator(gen.generate(True),
steps_per_epoch=num_train//BATCH_SIZE,
validation_data=gen.generate(False),
validation_steps=num_val//BATCH_SIZE,
epochs=5,
initial_epoch=0,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
if True:
model.compile(optimizer=Adam(lr=5e-5),loss=MultiboxLoss(NUM_CLASSES, neg_pos_ratio=3.0).compute_loss)
model.fit_generator(gen.generate(True),
steps_per_epoch=num_train//BATCH_SIZE,
validation_data=gen.generate(False),
validation_steps=num_val//BATCH_SIZE,
epochs=10,
initial_epoch=5,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
目标识别结果

import cv2
import keras
import numpy as np
import colorsys
import os
from nets import ssd
from keras import backend as K
from keras.applications.imagenet_utils import preprocess_input
from utils import BBoxUtility,letterbox_image,ssd_correct_boxes
from PIL import Image,ImageFont, ImageDraw
class SSD(object):
_defaults = {
"model_path": 'D:\\demo\\ssd_keras\\ssd_keras\\ssd-keras-master\\model_data/1.h5',
"classes_path": 'D:\\demo\\ssd_keras\\ssd_keras\\ssd-keras-master\\model_data/voc_classes.txt',
"model_image_size" : (300, 300, 3),
"confidence": 0.39,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
#---------------------------------------------------#
# 初始化ssd
#---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.sess = K.get_session()
self.generate()
self.bbox_util = BBoxUtility(self.num_classes)
#---------------------------------------------------#
# 获得所有的分类
#---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
#---------------------------------------------------#
# 获得所有的分类
#---------------------------------------------------#
def generate(self):
model_path = os.path.expanduser(self.model_path)
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
# 计算总的种类
self.num_classes = len(self.class_names) + 1
# 载入模型,如果原来的模型里已经包括了模型结构则直接载入。
# 否则先构建模型再载入
self.ssd_model = ssd.SSD300(self.model_image_size,self.num_classes)
self.ssd_model.load_weights(self.model_path,by_name=True)
self.ssd_model.summary()
print('{} model, anchors, and classes loaded.'.format(model_path))
# 画框设置不同的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
#---------------------------------------------------#
# 检测图片
#---------------------------------------------------#
def detect_image(self, image):
image_shape = np.array(np.shape(image)[0:2])
crop_img,x_offset,y_offset = letterbox_image(image, (self.model_image_size[0],self.model_image_size[1]))
photo = np.array(crop_img,dtype = np.float64)
# 图片预处理,归一化
photo = preprocess_input(np.reshape(photo,[1,self.model_image_size[0],self.model_image_size[1],3]))
preds = self.ssd_model.predict(photo)
# 将预测结果进行解码
results = self.bbox_util.detection_out(preds, confidence_threshold=self.confidence)
if len(results[0])<=0:
return image
# 筛选出其中得分高于confidence的框
det_label = results[0][:, 0]
det_conf = results[0][:, 1]
det_xmin, det_ymin, det_xmax, det_ymax = results[0][:, 2], results[0][:, 3], results[0][:, 4], results[0][:, 5]
top_indices = [i for i, conf in enumerate(det_conf) if conf >= self.confidence]
top_conf = det_conf[top_indices]
top_label_indices = det_label[top_indices].tolist()
top_xmin, top_ymin, top_xmax, top_ymax = np.expand_dims(det_xmin[top_indices],-1),np.expand_dims(det_ymin[top_indices],-1),np.expand_dims(det_xmax[top_indices],-1),np.expand_dims(det_ymax[top_indices],-1)
# 去掉灰条
boxes = ssd_correct_boxes(top_ymin,top_xmin,top_ymax,top_xmax,np.array([self.model_image_size[0],self.model_image_size[1]]),image_shape)
font = ImageFont.truetype(font='model_data/simhei.ttf',size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32'))
thickness = (np.shape(image)[0] + np.shape(image)[1]) // self.model_image_size[0]
for i, c in enumerate(top_label_indices):
predicted_class = self.class_names[int(c)-1]
score = top_conf[i]
top, left, bottom, right = boxes[i]
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32'))
right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32'))
# 画框框
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[int(c)])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[int(c)])
draw.text(text_origin, str(label,'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image
def close_session(self):
self.sess.close()
最终得到的效果呢,迭代了二十次的效果,比以前用yolov3的效果要好,自己再深入体会一下,继续学习。



评论(0)
您还未登录,请登录后发表或查看评论