

本文是上一篇论文 Playing Atari with Deep Reinforcement Learning 的拓展,得益于更大量的实验数据和精美的配图,本最终于 2015 在 Nature 上发表。这也是 DeepMind 在 Nature 上的第一篇文章,随后 DeepMind 就成了 Nature 的常客。
本篇文章的基本思路与其 13 年发表的论文类似。但多了很多精美的图和视频。这里主要挑出这些图片进行讲解。
首先是神经网络可视化表示:

与上一篇文章 Playing Atari with Deep Reinforcement Learning 的方法一致,不过使用了更好看的图来展示。
然后使用了一张表展示了他们的实验成果,有 49 款游戏使用 DQN 可以达到甚至超越人类玩家的水平。

下图展示了在不同画面情况下的价值函数大小。这里就是告诉我们 AI 已经成功的发现了,在 BreakOut 这款游戏中,挖出通道的奖励是很大的。比较明显的是在 2 和 4 处。2 处时,AI 已经打出了一些比较深的洞后,再击打到最外层的砖块,agent 就受到了 Value 函数下降的惩罚。而 4 点,agent 把小球打通洞了之后,Value 函数到达了顶峰。
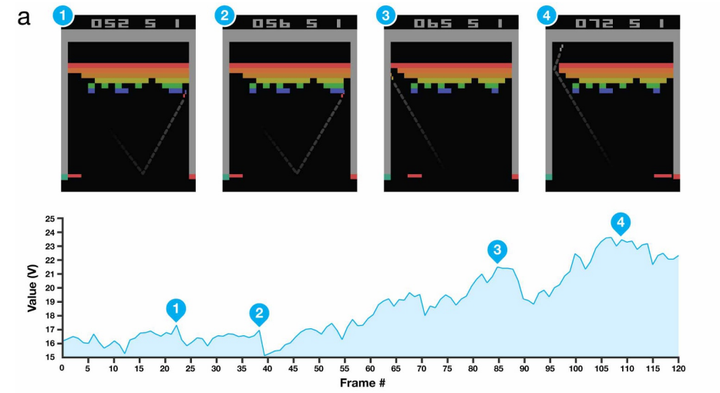
下图展示了使用 Q value 来提供游戏控制策略的图片。

这里AI学习到了一种非常极端的策略,即使用板子的边缘击球。如图 2,3 所示,在绿色板子击中球之前,agent 建议的控制策略都是向着球的方向移动。而当完成击打,并打出好球好,所有的操作都有较高的 Q 值,即胜率。
本文使用 Zhihu On VSCode 创作并发布



评论(0)
您还未登录,请登录后发表或查看评论